



第二节:上下文、RAG和微调的区别
为了让大模型能够按照我们的要求来回答,我们可以采用上下文、RAG和微调三种方式来实现。为了方便大家理解,我将后面模型回答问题类比为一场考试。
一、上下文
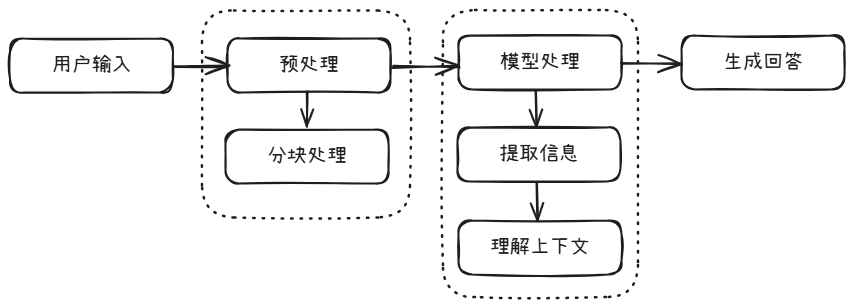
现在的大模型都支持超长上下文,从最开始的4K到现在的200K,我们完全可以在给大模型提问之前,先给出一段具有专业领域知识的上下文,比如发送一份PDF文件,然后让大模型根据PDF文档中的内容进行回答我的问题。这种方式类似于语文考试中的阅读理解,先给出一篇超长的文章,然后让你回答一些问题。其运行步骤为:
优点
可以将任何类型的文本发送给大模型作为上下文,随用随发,灵活性强。能够让大模型聚焦当前上下文的内容,回复的内容较为准确。
缺点
- 资源消耗大:模型上下文长度的增加,会导致大模型所需硬件资源的增加。
- 上下文限制:即使是再强大的模型,它的上下文窗口依然存在一个最大值,当我们给的上下文长度超过大模型的阈值时,就会出现无法回复的问题。
适用场景
适用于临时性让大模型辅助理解长文档中的内容。比如针对一篇报告,不想从头看到尾,那么可以丢给大模型,让大模型回答我感兴趣的部分。
二、RAG
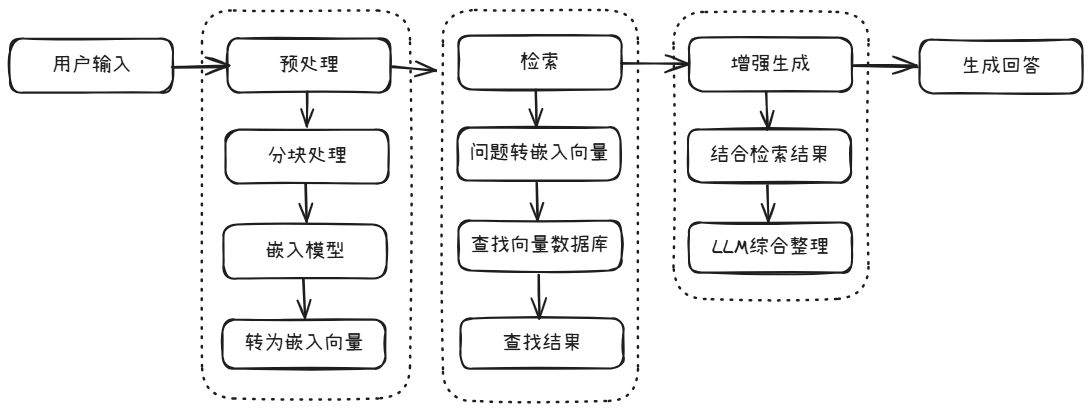
RAG(Retrieval-Augmented Generation,检索增强生成)。首先将知识库生成嵌入向量,存储到向量数据库中,然后大模型回复用户问题时,采用语义相似度等算法从向量数据库中检索出相关的内容,大模型结合检索出的内容进行回复。用学生考试的举例:让学生带着一本书参加开卷考试,考试的时候随时可以翻阅这本书来答题。
优点
相较于微调来说,可以随时更新知识库,让大模型能识别到最新的信息。并且不需要训练模型,人员成本和算力成本相对较低。
缺点
- 准确性:RAG中有一句话:Garbage in = Garbage Out,也就是知识库中数据对于RAG检索结果起到至关重要的作用。如果添加到向量数据库中的数据不准确或乱七八糟,那么检索出的结果也无法令人满意。
- 性能:由于每次回答都要查询向量数据库,所以回复问题的效率会有一定的影响。
适用场景
适用于知识库经常更新,对于回复时效性要求不高的场景。比如智能客服、企业内部问答系统等。
三、模型微调
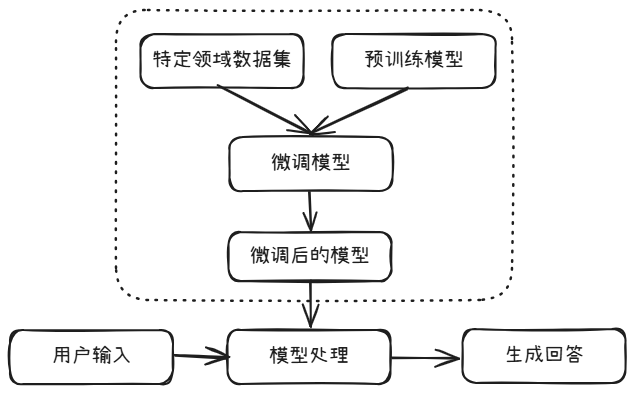
模型微调需要更新大模型中的部分参数,从而让大模型成为特定领域的专家。用学生参加考试的例子来理解:相当于是让学生考前参加该科目的辅导班,并学会更好的答题技巧,然后参加闭卷考试。其运行过程为:
优点
能够极大限度的提高模型在某专业领域的能力,并且可以显著提高模型的响应速度。
缺点
需要消耗一定的算力资源,还需要生成用于预训练的数据集。
适用场景
- 专业领域:如让大模型成为医疗、法律、金融等专业领域的专家。
- 特定任务:按照预训练的模式进行输出,如文本分类、情感分析等。
四、对比
| 上下文 | RAG | 微调 | |
|---|---|---|---|
| 原理 | 通过提供更丰富的上下文让大模型回答问题 | 通过挂载知识库增强大模型专业能力 | 通过调整大模型参数增强大模型专业能力 |
| 优点 | 灵活性强、准确性高 | 灵活性强、可随时更新知识库 | 性能最好、可定制性强 |
| 缺点 | 资源消耗大,上下文长度限制 | 性能低、依赖数据准确性 | 硬件设备要求高、数据要求高 |




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











