




 本文介绍了构建一个能够处理高并发视频观看计数服务的分布式系统设计。从需求收集、架构设计到技术选型,详细讨论了存储设计(单个事件与数据聚合)、数据库选型(MySQL与Cassandra)、计数服务设计(包括数据处理策略和高可用方案)、查询服务设计以及技术栈选型。同时,文章强调了系统扩展性、性能、高可用性和成本控制的重要性,并提出了监控、故障排查和数据一致性验证的考量。
本文介绍了构建一个能够处理高并发视频观看计数服务的分布式系统设计。从需求收集、架构设计到技术选型,详细讨论了存储设计(单个事件与数据聚合)、数据库选型(MySQL与Cassandra)、计数服务设计(包括数据处理策略和高可用方案)、查询服务设计以及技术栈选型。同时,文章强调了系统扩展性、性能、高可用性和成本控制的重要性,并提出了监控、故障排查和数据一致性验证的考量。
1.需求收集和总体架构设计
1.1 分布式系统设计的一般步骤
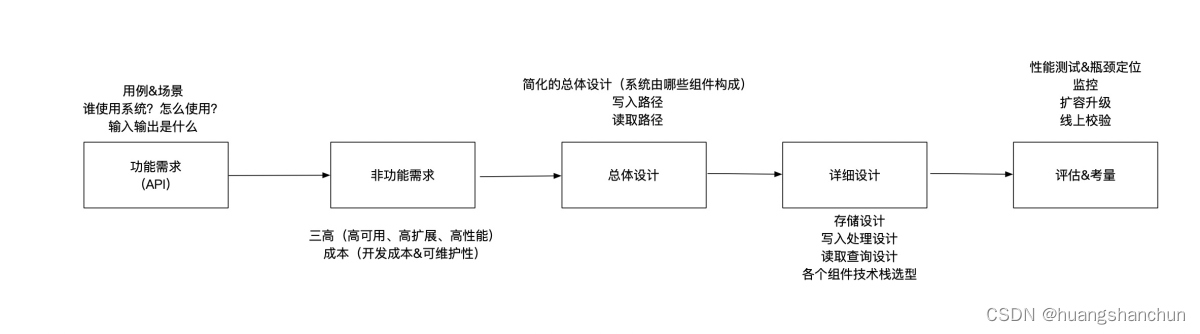
明确需求(功能和非功能性)从以下四个方面
● 场景&用例:谁用这个系统?如何使用?
● 量级&规模:qps多少,tps多少?流量模式,是否有流量高峰
● 性能:写入到读取延迟是多久?%99读取请求延迟是多少?
● 成本:开发成本&运维和维护成本
1.2 统计B站视频观看计数-案例
- 第一步明确功能需求(API)
--对视频观看数进行计数
// 对videoId 记录一次关键数量
countViewEvent(videoId)
//eventType like view share
countEvent(videoId,eventType)
//func count sum average
processEvent(videoId,eventType,func)
processEvents(listOfEvent)
根据时间返回视频观看数量
getViewsCount(videoId,startTime,endTime)
//func count sum average
getCount(videoId,evetType,func,startTime,endTime);
//func count sum average
getStatus(videoId,eventType,func,startTime,endTime);
-
第二步,明确非功能需求
量级&规模:量级和B站相当,每秒处理1W+视频点击观看记录
高性能:写入/读取毫秒级别延迟,写入读取更新分钟级别延迟(近实时流处理,最终一致性)
高可用:无单点失败
高扩展:容量不够时候,支持水平按需扩展
成本&维护:开源低成本 -
第三步,简化版总体设计-概要设计
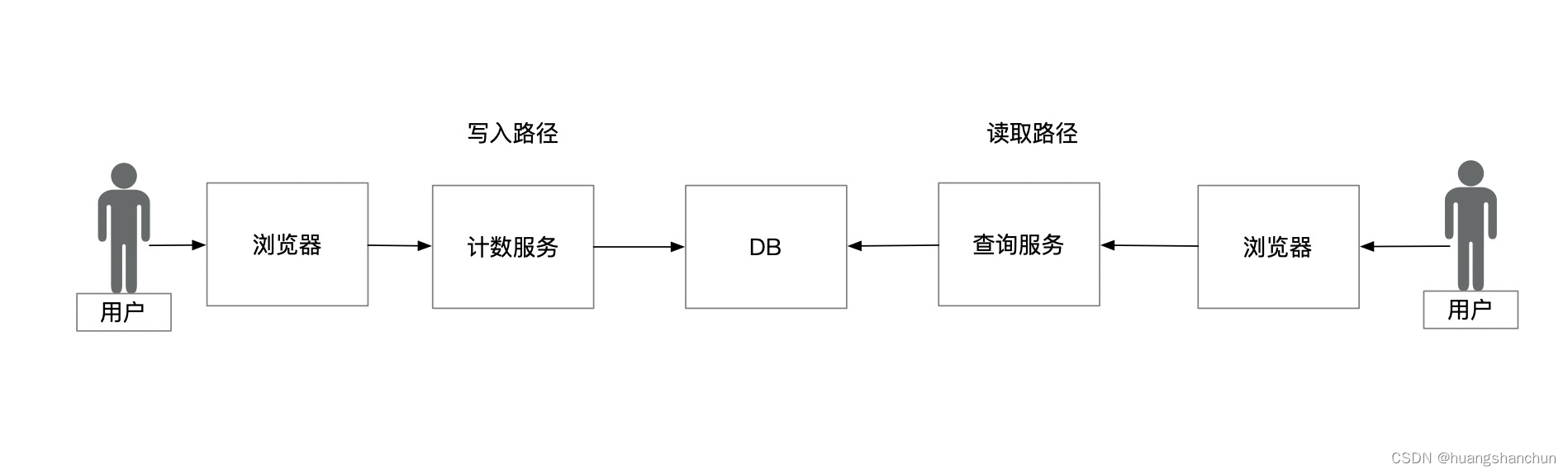
需要重点详细设计部分:计数服务、查询服务、存储设计,对于分布式系统核心是数据,可以考虑从存储开始设计。
2 存储设计
2.1 存储方式
两种存储方式:
存什么?也可以存单个事件,也可以存聚合的数据。
● 单个事件;优点:存原始数据可以快速写入,支持各种聚合运算 缺点:查询慢(都需要重复计算)、消耗存储

● 数据聚合;优点:查询快、存储少,缺点:只能按照已经聚合好的数据查询,出错无法修复(无原始数据),需要实时的聚合运算

有种折中的做法,两个都存储,这个会比较消耗存储。
2.2 数据库选型
选型要根据之前的需求,尤其是非功能需求进行选择
● 可扩展,根据读写规模按需扩展
● 高性能,快速读写
● 高可用,不丢数据,容灾
● 数据模型易于升级
● 一致性折中
● 可维护性&成本(开发者技术栈)
2.2.1传统关系型数据库
采用普通myql 做存储,需要分库分表 sharing,解决分摊负载的问题,resharing 需要手工导数据。
为了保障高可用,需要做主从复制。
提升性能,采用读写分离。
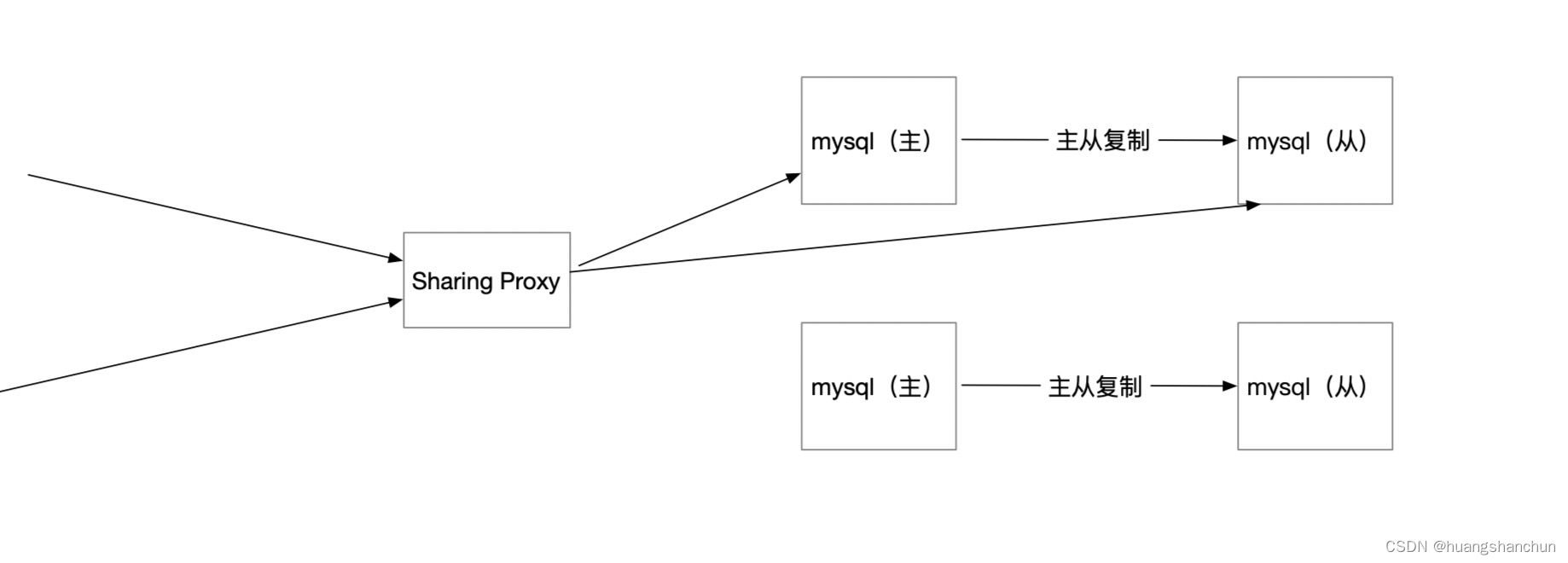
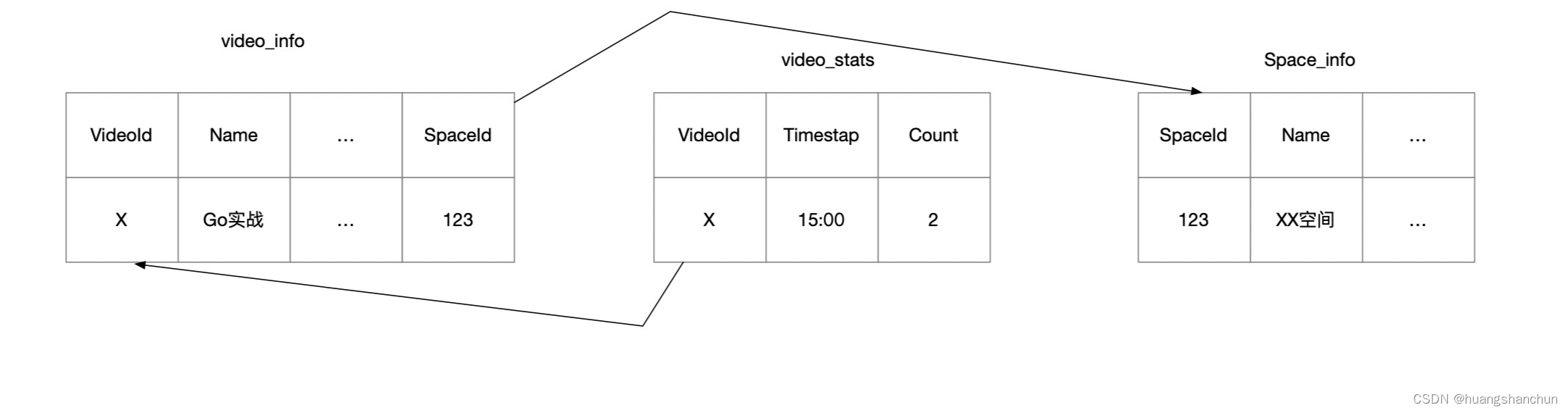
传统mysql 设计出来的表,尽可能的规范化,规划化的好处就是减少数据冗余,带来的不便查询时候需要join不同的表。
采用mysql 是虽然可以满足需求,为了满足高可以用和高扩展,引入了一些复杂性,如手工sharing、访问代理和配置中心,resharing 需要手工导数据。接下来引入NoSql 解决方案。
2.2.2NoSql 解决方案(Cassandra)
在一个Cassandra集群中也要分区的概念,数据也会按照某种hash算法分配到不同节点上(如一致性hash),这些节点都是对等的,没有主从之分。Cassandra集群会通过Gossip协议定期交换节点信息。当计算服务要写入一个L视频计数服务,首先将请求发到一个协调者(Coordinate节点)比如下图节点Node1,这个节点可以按照轮询或者就近或者其他负载均衡算法选出。Node1 知道L应该写到Node2,同时为了高可用Node1也会执行复制动作,比如集群中Node3(至于复制多少个节点称作复制因子),通过 Quorum Reads/Writes(仲裁读/写)来提升性能,节点中多数返回成功认为就是成功的,读取也是类似。Cassandra支持线性扩容无需人工干预,但是其运维管理复杂度也不低。
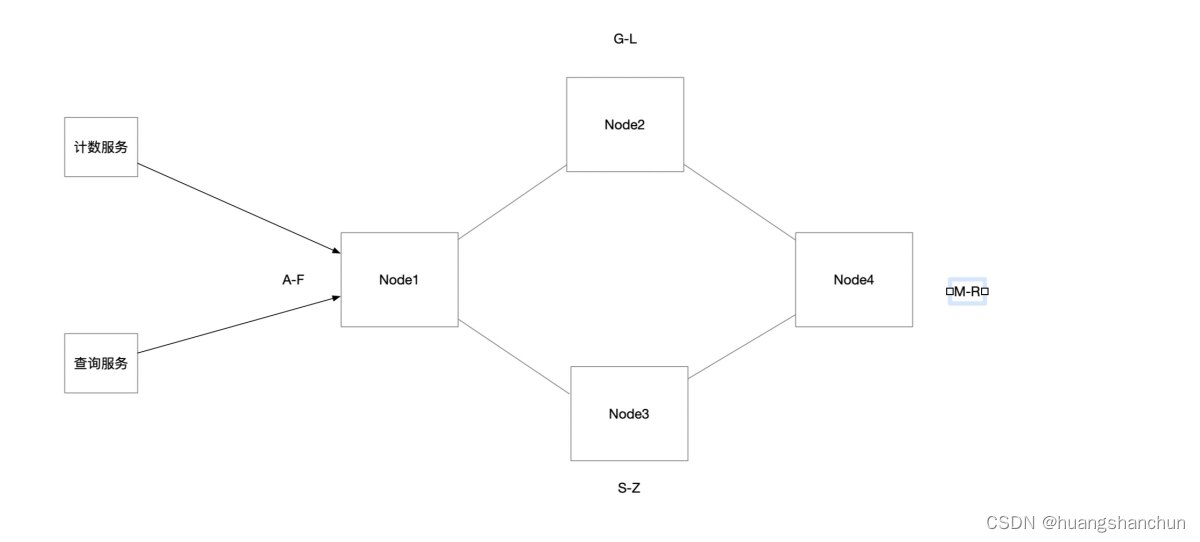
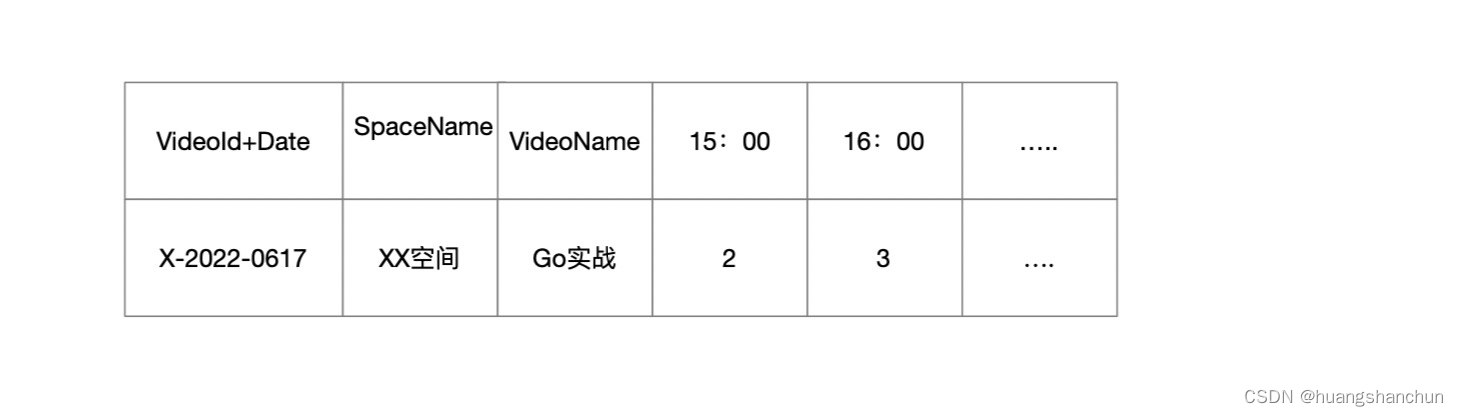
NoSql设计表目标是反规范化,允许必要冗余,在Cassandra中将视频一天访问特性建模在一行中,Cassandra支持宽行特性。
3 计数服务设计
首先再回顾一下需求&对应解决方案:
● 可扩展-可以根据写入规模按需扩展;解决方案:Sharding/Partitioning
● 高性能-快速写入,高吞吐;解决方案:内存计算、批处理
● 高可用-不丢数据,灾难恢复;解决方案:持久化,Replication,checkpointing
3.1数据聚合的基础
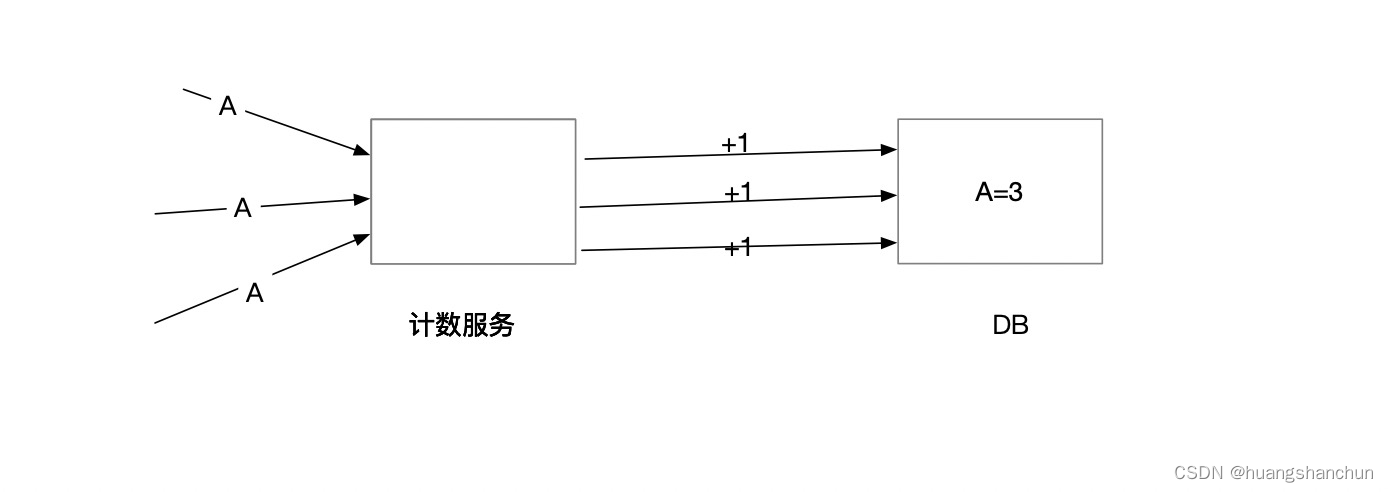
直接写入DB方式,这种做法优点:简单实时性好,缺点:频繁写入DB会给DB带来一定压力。
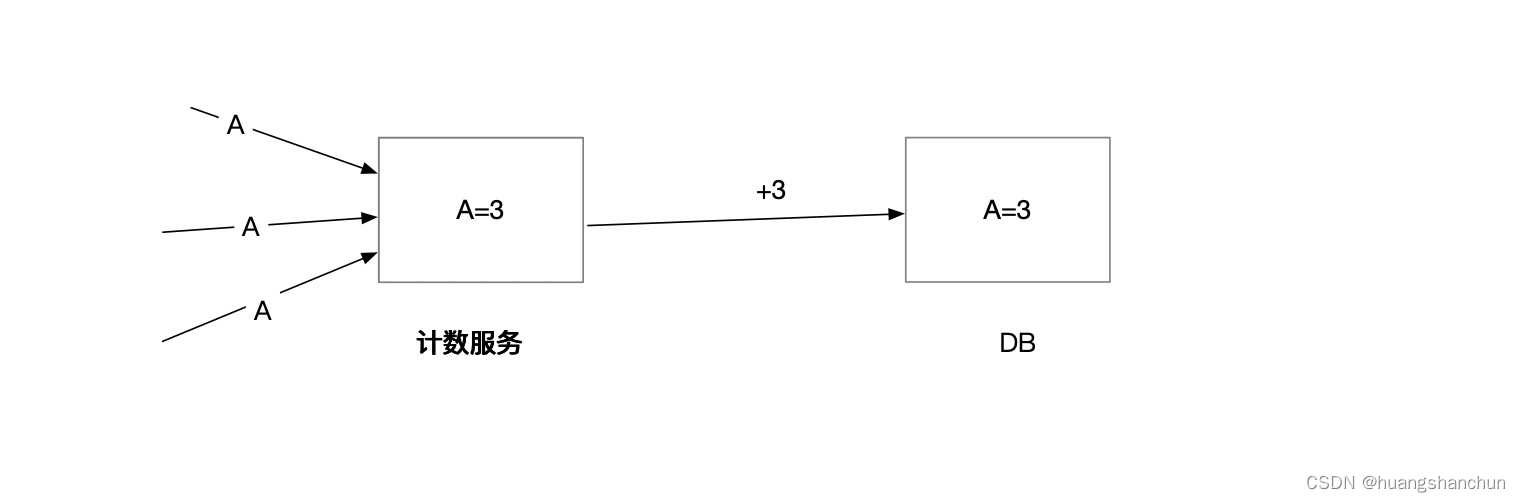
预聚合方式,内存聚合好,异步线程定期写入DB,这种做法可以减轻DB压力,系统吞吐量高;缺点:有一定延迟,系统设计复杂度。
3.2数据处理策略
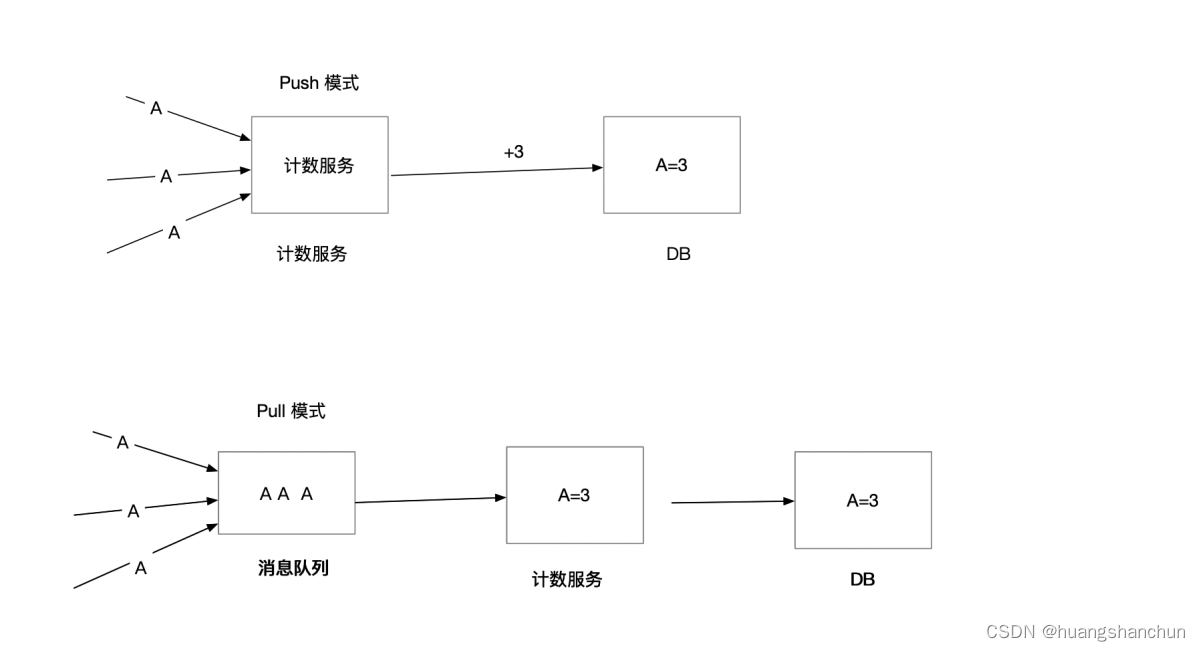
数据处理策略,常见有push和pull两种策略,如下图所示
● push模式:用户请求直接写入计数服务->数据库,中间没有任何缓冲,如果出现流量高峰就可能导致服务繁忙导致丢数据,这不满足系统高可用。
● pull模式:业界通常做法会在用户请求和计数服务之间引入消息队列;可以起到销峰作用,有效缓解生产和消费不匹配,同时也很好解耦了生产方和消费方。
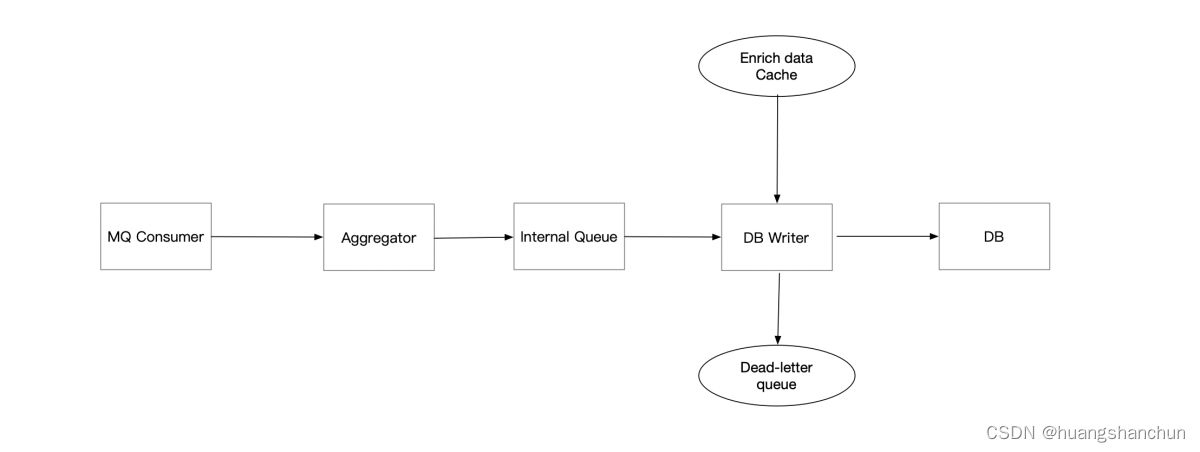
3.2 消费者端详细设计
消费者端流程如下,Aggregator(聚合运算)需要开发者开发,可用使用CurrentHashMap,定期将聚合结果写入到内部队列(需要高可用,简单做法将计算结果再发给Kafka),之所以引入队列原因是保证高可用,DB可能会慢如果写入失败就会丢数据;Enrich Data Cache 是数据补全用的;Dead-Letter Queue 也是保障高可用的,比如写入DB失败时候会进入这个队列,异步线程会后台定时重试写入数据库。
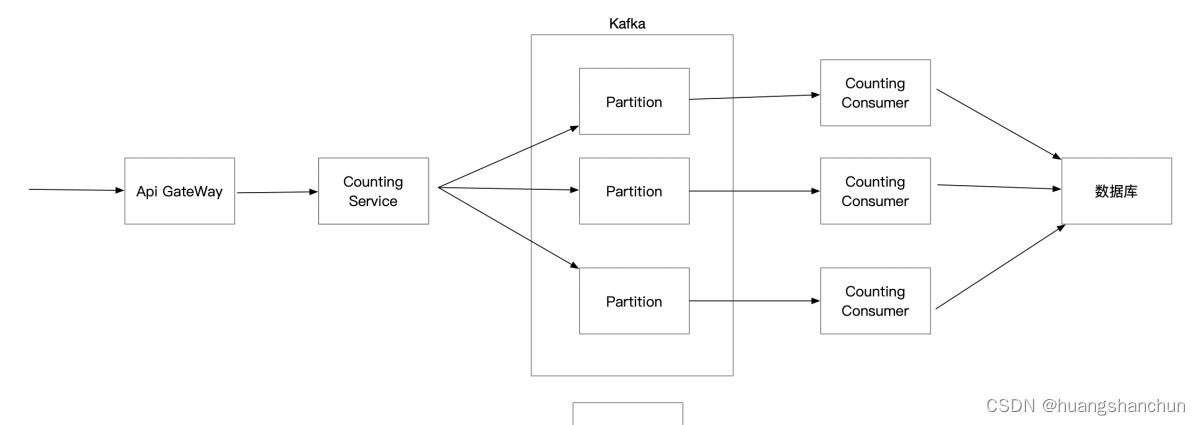
3.3 数据接收路径
用户点击观看视频,请求先打到API GateWay->网关转发到CountIng Service服务
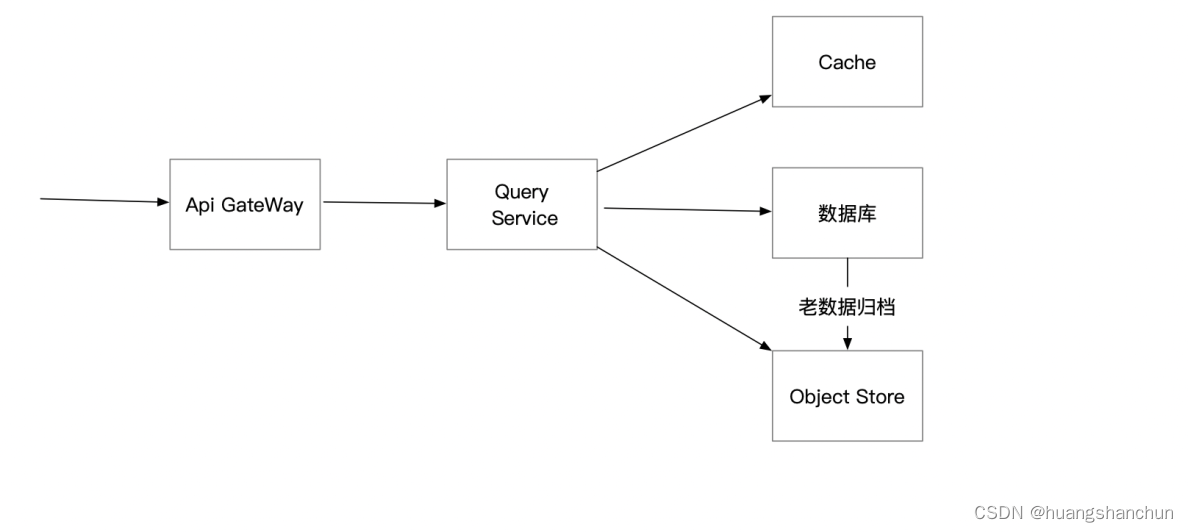
4 查询服务设计
这里查询是前提是数据已经聚合好,直接通过数据库去读取,而不是通过DB去进行聚合运算,整体流程如下图所示。为了提升查询性能,对于高频访问数据可以引入Cache,为了提升DB查询效率和降低DB存储空间,可以对历史数据进行归档(比如按月)。
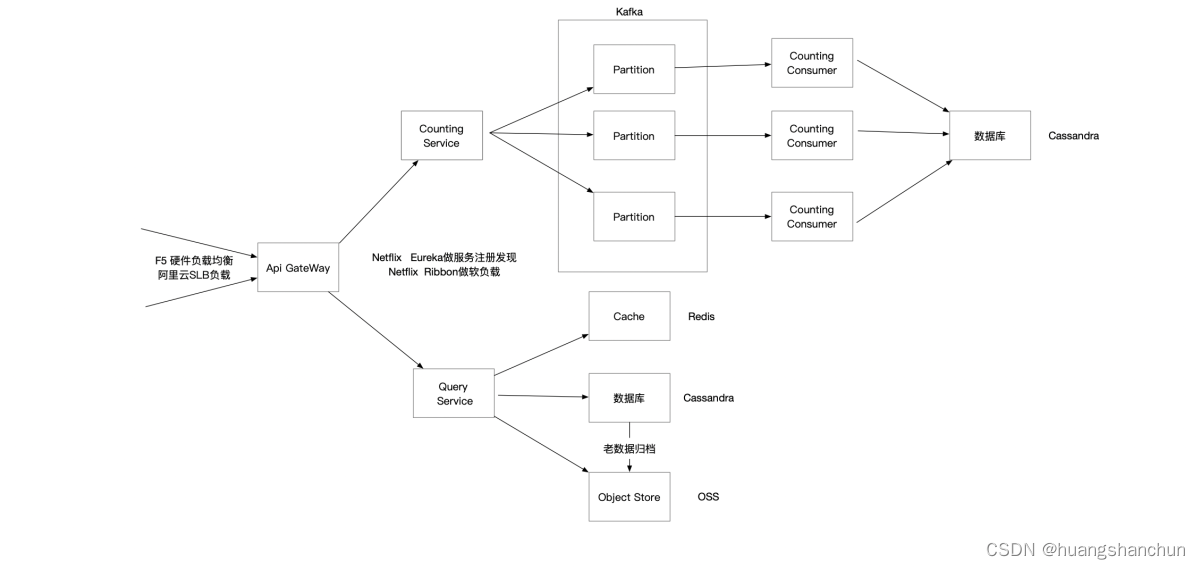
5 技术栈选型
整体采用java spring boot技术栈,具体技术选型如下图所示,
● api gateWay 可以考虑使用Netflix Zuul 网关或者Spring Cloud gateWay;这个网关也需要做集群和前置负载均衡,这里可以考虑F5硬件负载均衡器或者使用阿里云SLB。
● 网关和计数服务和查询服务之间需要服务发现问题,采用Netflix Eureka做服务注册发现,Netflix Ribbon做软负载。
● 存储选择比较适合大规模时间序列存储Cassandra或者Hbase,缓存就次用Redis,消息采用Kafka
6 进一步考量&总结
详细设计和技术栈选型也做完了,是不是就结束了呢?显然不是,还需要考虑以下问题
● 如何定位系统瓶颈?需要对系统进行做压力测试,找出系统性能问题并进行优化,根据系统基准线去做容量规划。
● 如何监控系统健康状况?需要做埋点监控,业务监控、应用监控、系统监控等。
● 如何确保线上系统运行结果正确?业界有两种做法:1.开发一套线上模拟系统,定期模拟线上点击事件,然后查询对结果进行校验。2.实时流计算+离线批处理系统对账(Lambda Architecture)。
● 如何解决热分区问题?两种做法:数据再分片,如对对视频Id+时间戳;第二种是迁移隔离,路由特定分组&节点上。
参考文献
[1] https://time.geekbang.org/course/intro/100053601?tab=catalog


















 1496
1496

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









