




 本文深入剖析MySQL的Server层和存储引擎层,涉及连接器、权限管理、SQL解析与优化,以及InnoDB与MyISAM的区别。了解连接流程、权限分配与优化策略,提升数据库性能管理认知。
本文深入剖析MySQL的Server层和存储引擎层,涉及连接器、权限管理、SQL解析与优化,以及InnoDB与MyISAM的区别。了解连接流程、权限分配与优化策略,提升数据库性能管理认知。
0 mysql 逻辑架构图
大体来说,mysql可以分为Server层和存储引擎层两个大部分,
- Server层包括连接器、查询缓存、分析器、优化器、执行器等;涵盖了Mysql的大多数核心服务功能了,如所有的内置函数(如日期、时间、数学、加密函数),所有跨存储引擎的功能都在这一层实现,比如存储过程、触发器、视图等。
- 引擎层数据存储和提取,InnoDB支撑事务、外键、行锁等,MyISAM 插入数据快,空间和内存使用比较低。
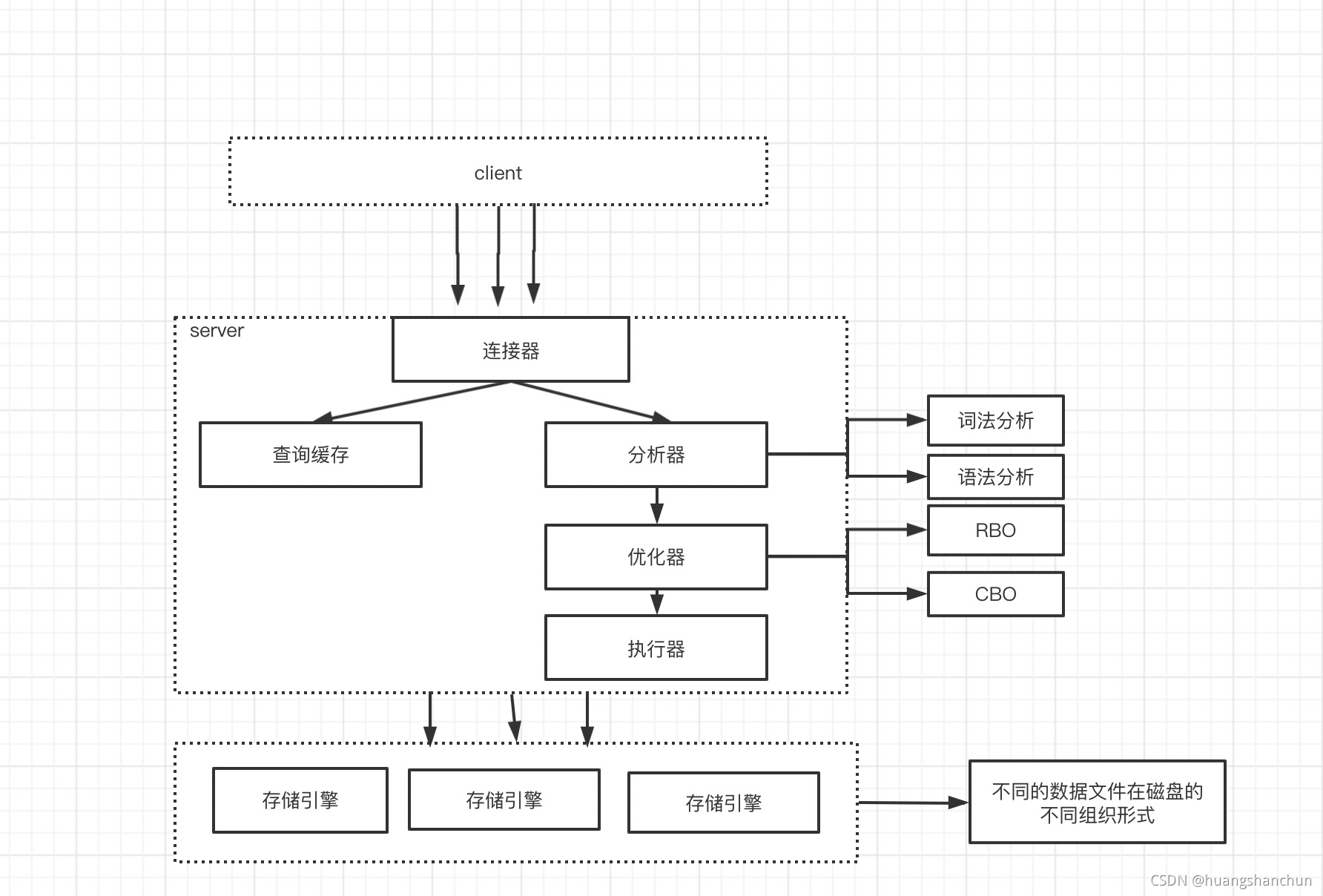
1 Server层
1.1 连接器
连接器作用是管理连接,权限验证;show variables like ‘%max_connections%’; show processlist 可以查看连接状态等信息,客户端连接成功,如果超过一定时间(默认8小时)没有动静,连接器会自动将其断开。show variables like ‘%wait_timeout%’;
如果用户名或密码不对,你就会收到一个"Access denied for user"的错误,然后客户端程序结束执行。
如果用户名密码认证通过,**连接器会到权限表里面查出你拥有的权限。**之后,这个连接里面的权限判断逻辑,都将依赖于此时读到的权限。
mysql 相关用户权限存储;
-
user表:存储用户账号信息和全局权限。这些权限对MySQL服务器上的所有数据库生效。每行代表一个用户以及该用户的全局权限和属性。
-
db表:存储数据库级别的权限。这些权限仅对特定数据库生效。它记录了用户在特定数据库上所拥有的权限。
-
tables_priv表:存储表级别的权限。这些权限仅对特定数据库中的特定表生效。
-
columns_priv表:存储列级别的权限。这些权限仅对特定数据库中特定表的特定列生效。
-
procs_priv表:存储存储过程和函数的权限。
-
roles_mapping表(MySQL 8.0及以后版本中):存储角色和用户的关联信息。角色是一组权限的集合,可以分配给用户。
如下图所示,先判断有没有权限(不是先检查表是否存在)

给某个用户授权权限
GRANT CREATE, ALTER, DROP, INSERT, UPDATE ON *.* TO 'username'@'hostname';
案例:
授予 用户hsc 在marketing库下所有表权限
GRANT CREATE, ALTER, DROP, INSERT, UPDATE ON marketing.* TO 'hsc'@'localhost';

mysql 建立连接的过程通常是比较复杂的,在实际生产环境,尽量使用长连接;但是使用长连接后,你可能会发现;有些时候 MySQL 占用内存涨得特别快,这是因为 MySQL 在执行过程中临时使用的内存是管理在连接对象里面的。如果长连接积累一定程度可能会导致OOM,从现象看就是 MySQL 异常重启了;有两种解决方案
- 定期断开长连接。使用一段时间,或者程序里面判断执行过一个占用内存的大查询后,断开连接,之后要查询再重连。
- 如果你用的是 MySQL 5.7 或更新版本,可以在每次执行一个比较大的操作后,通过执行 mysql_reset_connection 来重新初始化连接资源。这个过程不需要重连和重新做权限验证,但是会将连接恢复到刚刚创建完时的状态。
1.2 分析器
分析器作用是语法分析、词法分析,知道sql要做什么,构建语法树。开源的插件有antlr、calcite。 如下图所示不存列会在分析阶段报出来。fen
1.2 优化器
优化器;执行计划生成,索引选择;优化器是在表里有多个索引或者一个语句有多表关联 join。常见优化器有:RBO(Rule-Based Optimization)和CBO(Cost-Based Optimization)。
- 执行器;操作引擎,返回结果;mysql 通过分析器知道sql要做什,通过优化器知道怎么做,执行器
- 查询缓存;一般不建议使用查询缓存;只要有对一个表更新;这个表上的所有查询缓存都会被清空。如果是静态表(几乎不更新)那这样才适合查询缓存。 show variables like ‘%query_cache_type%’;
2 一条查询如何执行
select * from user where id=1;
第一步客户端要通过连接器连接上数数据库, mysql -h h o s t − P host -P host−Pport -u$user -p ;说明:
- $host 应该被替换为实际的主机名或者 IP 地址。
- $port 应该被替换为实际的端口号;注意这里是大写P,小写p指的是密码
- $user 应该被替换为实际的用户名。
- -p 指定了需要输入密码。使用这个选项后,终端会提示用户输入密码。为了安全起见,建议不要在命令行中直接包含密码,而是使用 -p 后不直接跟密码,这样可以在提示时安全输入。
如下所示登录本地mysql,用户名hsc,ps:这里端口号是-P(大写的)
mysql -hlocalhost -uhsc -P3306 -p
第二步查询缓存,如果缓存有数据就直接返回,mysql 8.0 以上的版本已经取消了。
第三步分析器,mysql 根据你输入通过词法分析识别出select 、where关键字和非关键字user和id等,接下来会进行语法分析,判店输入的这个SQL是否满足mysql语法,然后生成相应语法树,如果语法不对会报错。
第四步优化器,经过分析器之后,mysql知道了你要做什么,但是怎么做才能最优,会按照RBO和CBO进行优化。比如该用那个索引或者在一个语句有多表关联join的时候,决定各个表的链接顺序。
第五步执行器,通过分析器知道到要做什么,通过优化器知道了该怎么做。在执行器阶段就开始调用存储引擎的接口执行。上面这个查询语句中如果id没有锁引执行过程1)调用InnoDB引擎的接口读取这个表的第一行,判断Id是不是等于1,如果满足条件则放到结果集中,不满足条件的则跳过 2)读取下一行数据,重复1步骤,直到读取完所有数据 3)将上述遍历满足条件的所有数据的结果集返回给客户端。对于有索引的表,执行逻辑也类似。如果查询中遇到了慢查询可以查看mysql慢查询日志分析,慢查询介绍。
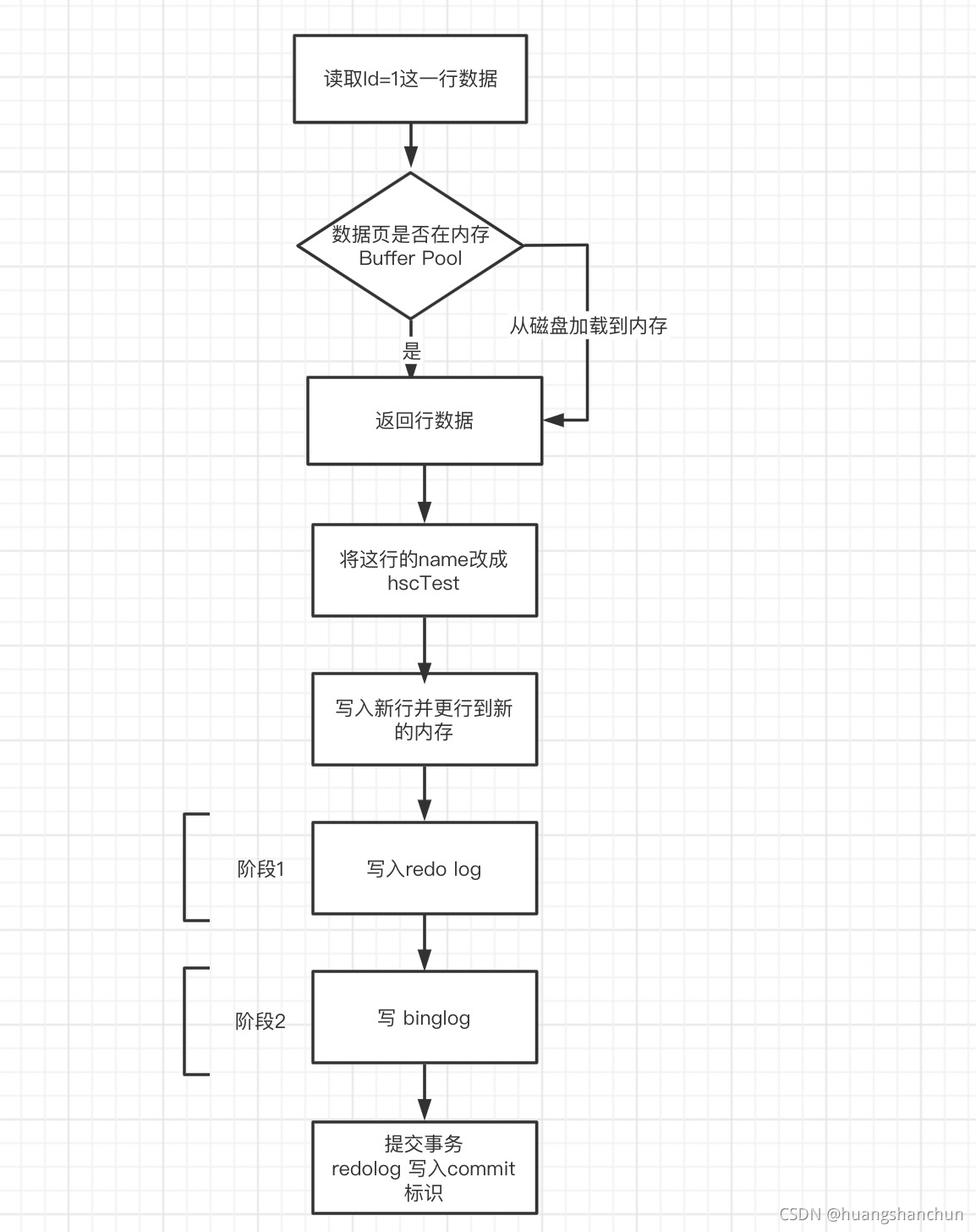
3 一条更新的语句如何执行
update user set name="hscTest" where id=1;
更新流程如下图所示,采用两阶段提交来保证redo log 和binlog 逻辑上一致性。先看下怎么保障逻辑一致性的?有以下几种情况 1)阶段1 prepare redo log 已经写完,在写binlog 之前mysql进程异常退出或者写失败。由于此时 binlog 还没写,数据也不会传到备库,redo log 也还没提交,所以崩溃恢复的时候,这个事务会回滚掉。2)阶段一和阶段二都已经完成,即prepare redo log 已经写完,binlog已经写完,还没有commit前发生crash。恢复时候如果redo log 里面的事务是完整的,也就是已经有了 commit 标识,则直接提交;如果redo log 里面的事务只有完整的 prepare,则判断对应的事务 binlog 是否存在并完整:如果都是完整的则提交事务否则回滚。
参考文献
[1]https://dev.mysql.com/doc/refman/8.0/en/access-control.html
[2] 高性能mysql 第三版
[3]极客时间mysql实战45讲

















 1495
1495




 到【灌水乐园】发言
到【灌水乐园】发言







