




《Agentic Retrieval-Augmented Generation for Time Series Analysis》这篇文章提出了一种新颖的时间序列分析方法,称为Agentic Retrieval-Augmented Generation(RAG)框架。它通过多层次的多代理架构来处理时间序列任务,其中主代理协调多个专门的子代理,并将用户请求分配给相应的子代理进行处理。以下是对论文摘要和方法的详细解读:
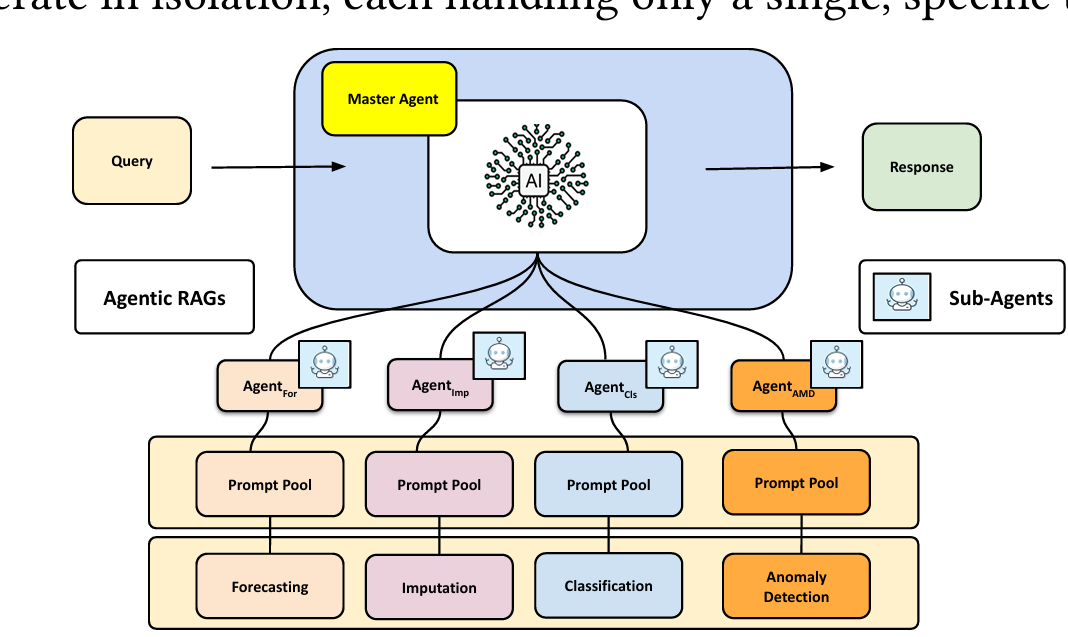
该图展示了提出的代理检索增强生成(agentic RAG)框架,旨在处理多样化的时间序列分析任务。该框架采用了层次化的多代理架构。主代理接收终端用户的问题,并根据具体的时间序列任务(如预测、数据填补、分类、异常检测)将其分配给相应的专门子代理。子代理利用预训练的小规模语言模型(SLMs),通过指令微调和直接偏好优化等技术,在任务特定的数据集上进行微调,以捕捉时间序列数据集内和跨数据集的时空依赖性。每个子代理维护自己的提示池,这些提示以“键-值”对的形式存储,包含与其专门领域内特定趋势和模式相关的历史知识。这使得子代理能够利用相关的过去经验,对新的、相似数据进行改进的任务特定预测,最后通过主代理将结果反馈给用户。
主要贡献
- Agentic RAG框架:该框架通过引入分层、多代理的架构来增强时间序列分析的灵活性和精确性。主代理管理多个子代理,每个子代理都专注于特定的时间序列任务(如预测、缺失数据填充、异常检测等)。这种模块化设计允许框架在不同任务之间共享知识,并针对特定任务进行优化,从而提高性能。
- 小型预训练语言模型(SLMs):框架利用了小型的预训练语言模型(如Gemma和Llama 3),这些模型通过指令微调和直接偏好优化(DPO)技术进行了定制,使其适应特定的时间序列任务。通过这种方式,SLMs可以更好地捕捉复杂的时空依赖关系,并在新的数据上进行更准确的预测。
- 提示池:每个子代理维护一个提示池,存储历史模式和趋势的“键值对”信息。当处理新的输入数据时,子代理可以从提示池中检索相关的提示,以提供上下文知识,从而增强对新场景的预测能力。这种知识增强的方法通过基于过去的模式进行条件化,有助于子代理更好地适应复杂的数据趋势。
方法创新
- 动态提示机制:为了应对非平稳性和分布变化的挑战,框架引入了可微分的动态提示机制,使传统的时间序列方法能够访问相关的历史知识,从而在新的相似输入数据上进行自适应学习。
- 指令微调和偏好优化:通过对SLMs进行指令微调和直接偏好优化,框架显著提高了模型处理时间序列数据的能力,特别是在处理长序列依赖和复杂模式方面。
实验与结果
该框架在多项时间序列任务(如预测、分类、异常检测、缺失数据填充)上进行了广泛的实证研究。实验结果表明,Agentic-RAG框架在多项基准数据集上实现了与现有方法相当或更好的性能,尤其是在处理单变量和多变量时间序列数据方面展现了优越性。
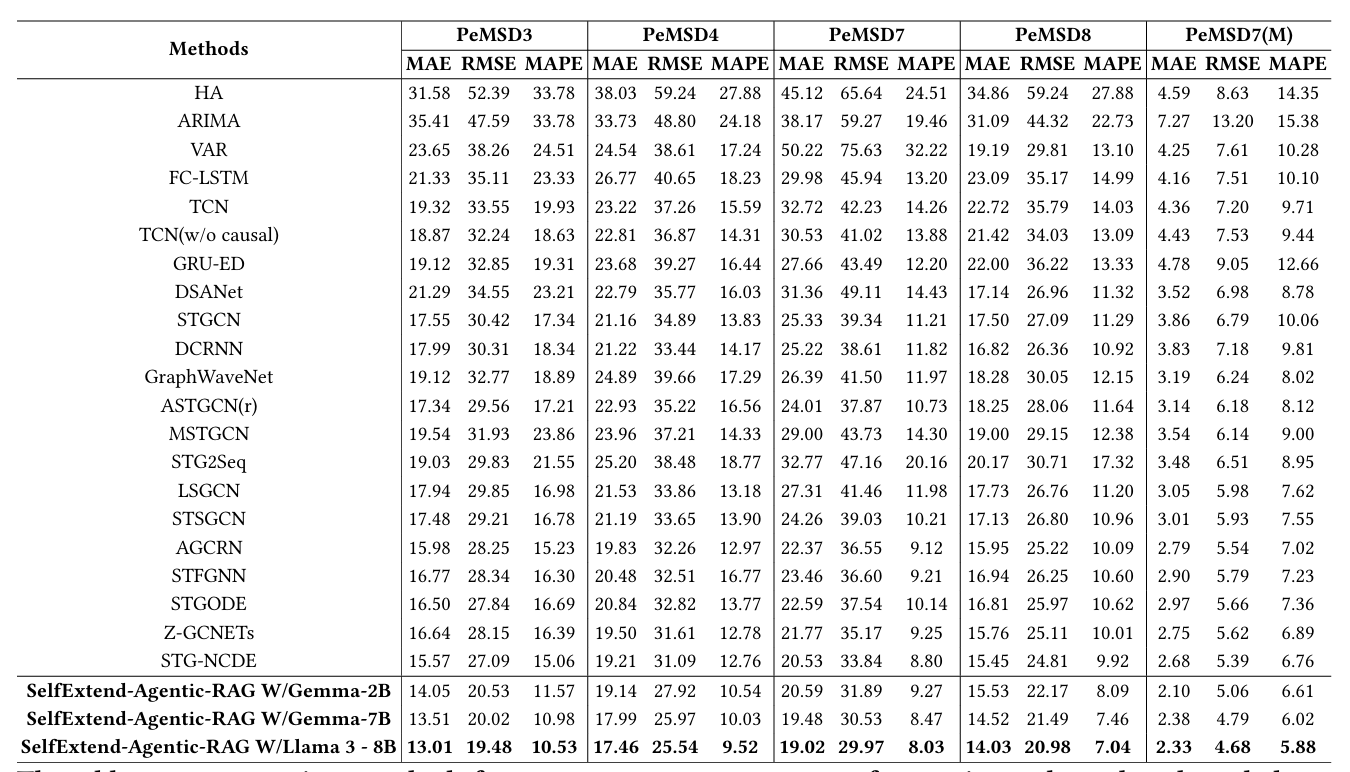
该表格比较了在基准数据集上进行12序列对12序列预测任务的各种方法,使用了多个评估指标。这些方法使用过去的12个序列来预测接下来的12个序列。
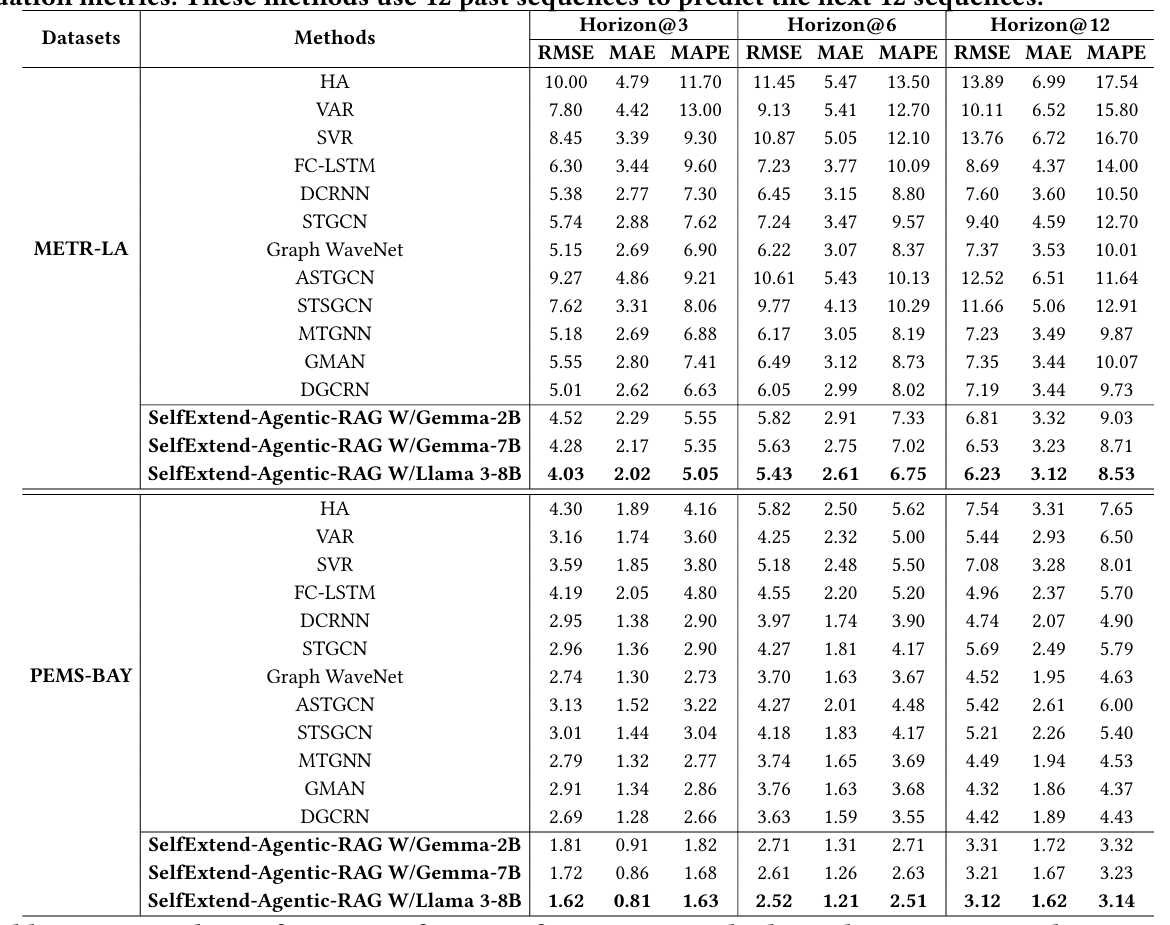
该表格比较了各种预测方法在METR-LA和PEMS-BAY基准数据集上的性能,使用了多个评估指标。所有方法均使用过去的12个序列来预测未来的3、6或12个序列。
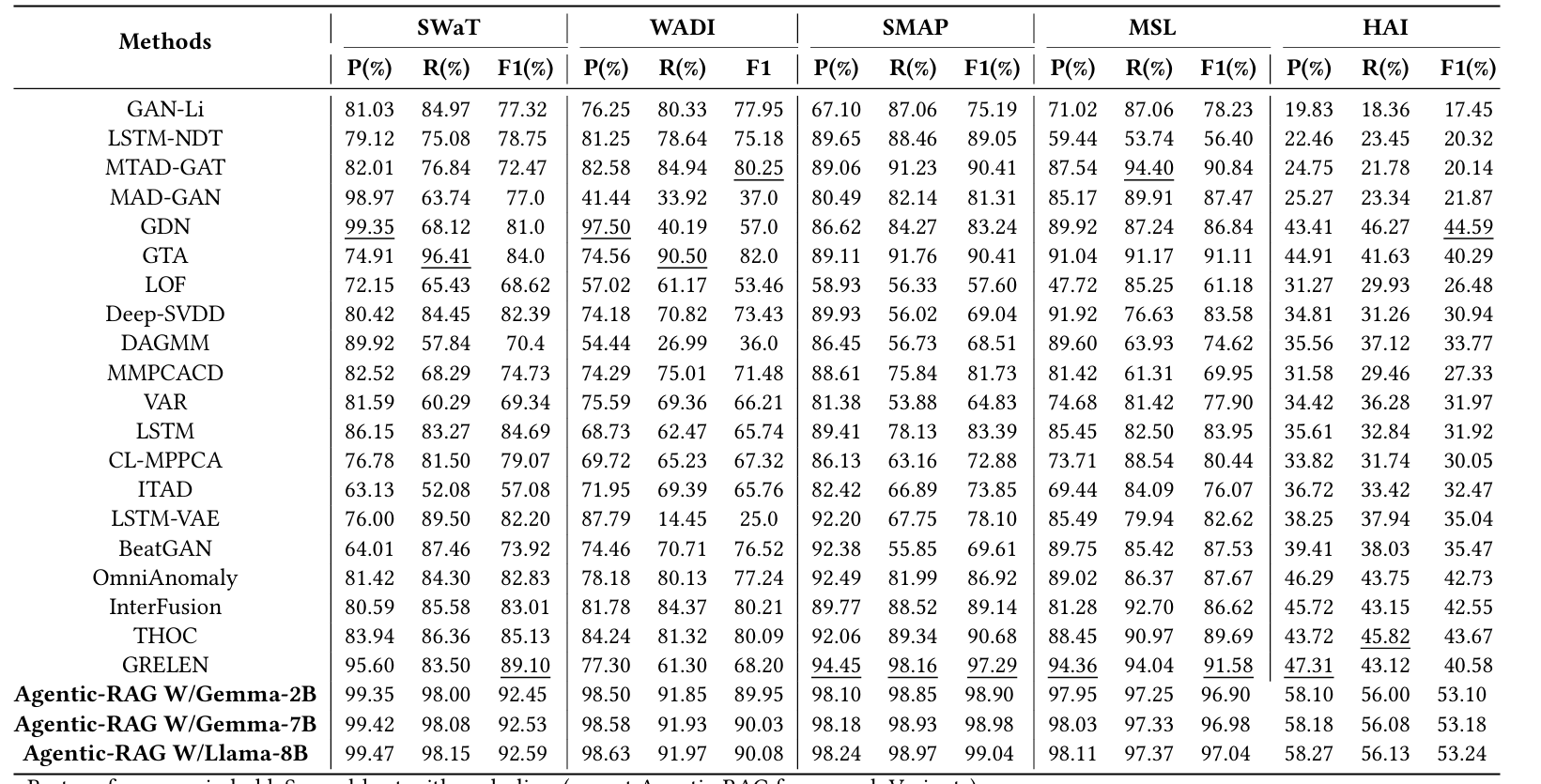
在异常检测基准数据集上的实验结果通常通过精确率(Precision)、召回率(Recall)和F1-Score来衡量
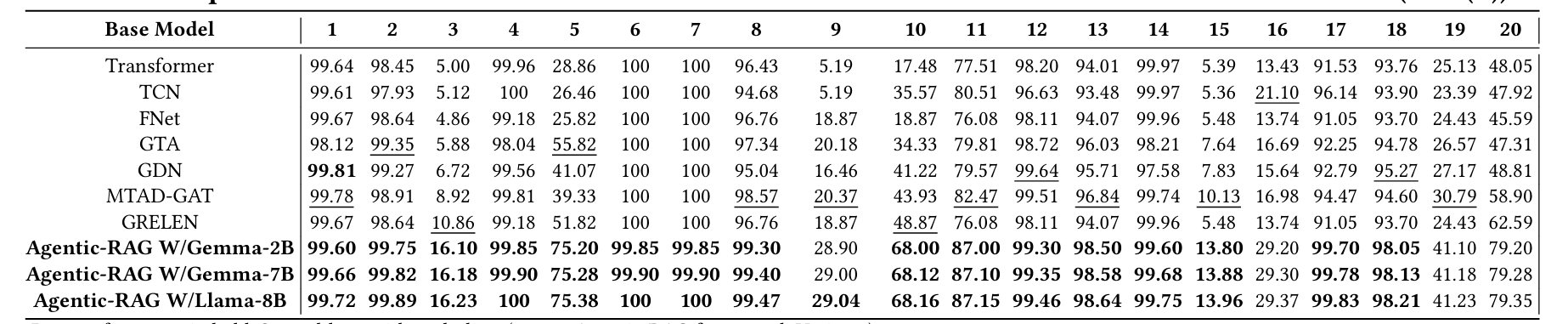
在模拟的Tennessee Eastman数据集上的实验结果,以故障检测率(Fault Detection Rate,FDR(%))为衡量指标。
优势与挑战
- 优势:框架的多代理架构具有模块化和灵活性,能够针对特定任务进行优化,并能随时进行更新。这种设计提高了不同任务的处理精度,也有助于更好地应对复杂的时间序列分析挑战。
- 挑战:虽然框架展现了很好的性能,但如何在更大规模的数据集或更复杂的实际应用中保持其高效性仍是一个挑战。此外,框架对提示池的依赖也可能带来额外的计算开销,如何优化这一过程也是未来的研究方向之一。
总结
Agentic RAG框架通过结合多代理架构和动态提示机制,为时间序列分析提供了一种灵活且高效的解决方案。它不仅在多个基准数据集上实现了先进的性能,而且展示了在应对时间序列分析中复杂挑战时的潜力。这种方法为未来的时间序列建模研究提供了一个有前景的方向。



















 733
733

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











