




 本文详细解读了Redis中的核心数据结构redisObject、redisDb和redisServer,介绍了它们的组成、用途和内存管理,以及不同数据类型的编码策略,如ziplist、hashtable等。
本文详细解读了Redis中的核心数据结构redisObject、redisDb和redisServer,介绍了它们的组成、用途和内存管理,以及不同数据类型的编码策略,如ziplist、hashtable等。
Redis 数据存储模型
redisObject
typedef struct redisObject {
unsigned type:4;
unsigned encoding:4;
unsigned lru:LRU_BITS; /* LRU time (relative to global lru_clock) or
* LFU data (least significant 8 bits frequency
* and most significant 16 bits access time). */
int refcount;
void *ptr;
} robj;
定义了 Redis 中的数据对象结构 redisObject,它是 Redis 存储数据的基本单元。
-
unsigned type:4;和unsigned encoding:4;:这两个字段用于表示对象的类型和编码方式。它们各自使用 4 位来存储,因此每个字段的值可以是 0 到 15(4 位的二进制数可以表示 0 到 15 的十进制数)。type表示对象的数据类型(例如字符串、哈希、列表等),encoding表示对象的内部编码方式(例如字符串的编码方式可以是 int、embstr 等)。 -
unsigned lru:LRU_BITS;:这个字段用于实现 LRU(Least Recently Used)算法,用于对象的淘汰策略。LRU_BITS表示用多少位来表示 LRU 时间。这个字段在对象类型为字符串时用于存储 LRU 时间,而在其他对象类型时用于存储 LFU(Least Frequently Used)数据,其中低 8 位存储频率信息,高 16 位存储访问时间信息。 -
int refcount;:这个字段表示对象的引用计数,用于管理对象的内存释放。当一个对象被多个地方引用时,引用计数会增加;当引用计数为 0 时,表示对象不再被使用,可以被释放。 -
void *ptr;:这个字段是一个指针,指向实际存储数据的位置。这可以是各种不同类型的数据,根据对象的不同类型和编码方式而变化。
关于占用多少字节的问题,这个取决于编译器对结构体内存对齐的规则和枚举字段的位数。通常来说,该结构体可能占用的字节数是这些字段所占字节数的总和。但由于内存对齐的原因,编译器可能会在结构体中插入一些填充字节,以便使结构体的各个字段在内存中对齐,以提高访问效率。因此,要确切知道 redisObject 在你的环境中占用多少字节,可以通过 sizeof(robj) 进行查询。注意,这可能会因编译器和平台而异。
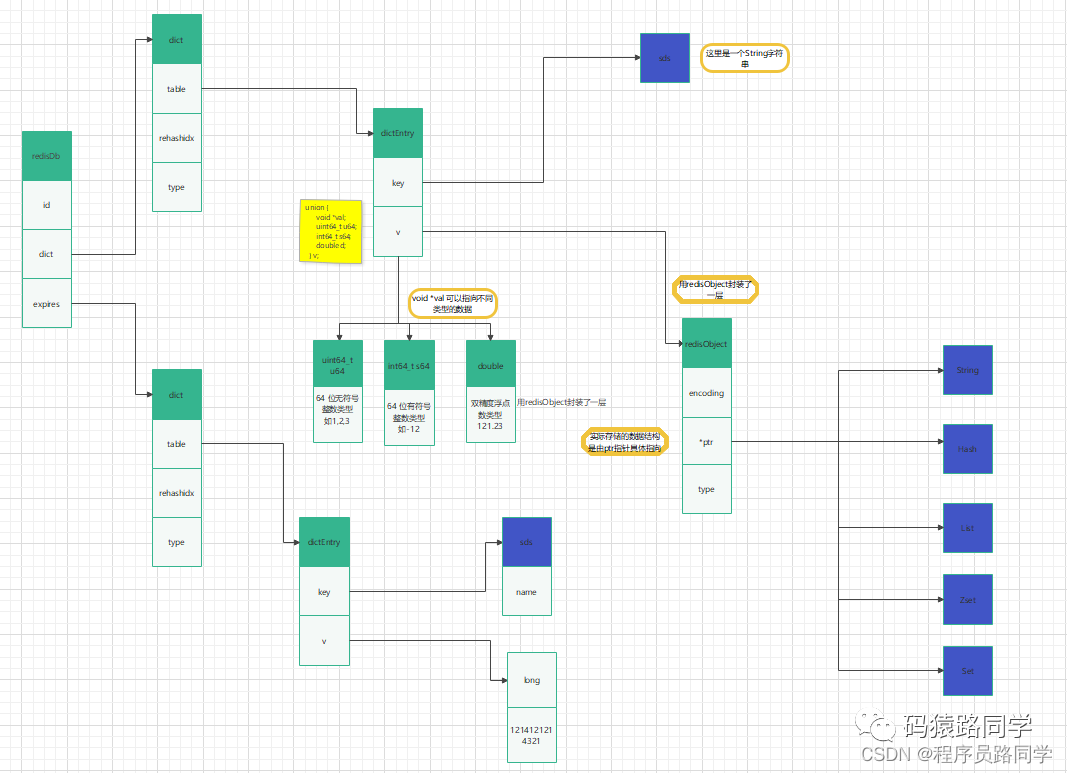
redisDb
/* Redis database representation. There are multiple databases identified
* by integers from 0 (the default database) up to the max configured
* database. The database number is the 'id' field in the structure. */
typedef struct redisDb {
dict *dict; /* The keyspace for this DB */
dict *expires; /* Timeout of keys with a timeout set */
dict *blocking_keys; /* Keys with clients waiting for data (BLPOP)*/
dict *ready_keys; /* Blocked keys that received a PUSH */
dict *watched_keys; /* WATCHED keys for MULTI/EXEC CAS */
int id; /* Database ID */
long long avg_ttl; /* Average TTL, just for stats */
unsigned long expires_cursor; /* Cursor of the active expire cycle. */
list *defrag_later; /* List of key names to attempt to defrag one by one, gradually. */
} redisDb;
这是 Redis 数据库的内部表示结构,用于表示一个 Redis 数据库。在 Redis 中,有多个数据库,每个数据库通过一个整数标识(从 0 到最大配置的数据库数)来区分,这个整数就是结构中的 id 字段。
-
dict *dict;:
这是一个指向字典数据结构的指针,用于存储这个数据库的键值对信息。每个数据库都有一个独立的字典,用于存储键值对数据。 -
dict *expires;:
用于存储具有过期时间的键的信息。这个字典用于管理带有过期时间的键,以及它们的过期时间。 -
dict *blocking_keys;:
存储正在进行阻塞操作(如 BLPOP)的键,表示这些键有客户端正在等待获取数据。 -
dict *ready_keys;:
存储已经被解除阻塞(通过 PUSH 操作)的键,表示这些键原本有客户端在等待,但已经收到了数据。 -
dict *watched_keys;:
用于 MULTI/EXEC 命令中的 CAS(Check-And-Set)操作,存储被 WATCH 命令监视的键。 -
int id;:
表示数据库的唯一标识符,是一个整数。默认情况下,Redis 会有多个数据库,编号从 0 开始。 -
long long avg_ttl;:dictht
表示所有键的平均 TTL(Time-To-Live,生存时间),仅用于统计目的。 -
unsigned long expires_cursor;:
表示活跃的过期键的游标。在进行过期键的管理时,Redis 会通过这个游标来确定当前的处理位置。 -
list *defrag_later;:
一个列表,存储需要逐一尝试进行碎片整理的键的名称。这是一个逐步进行的过程,用于减少碎片化。
redisDb 结构体表示了 Redis 数据库的基本属性和状态信息。它包含了用于存储键值对、管理过期键、处理阻塞键等多个字典和列表,以及一些统计信息。每个数据库都有一个独立的 redisDb 结构来管理和维护自己的数据和状态。
redisServer
redisServer的数据结构可以在server.h中查看,这里因为篇幅有限,大致给出部分字段解释:
struct redisServer {
/* General */
pid_t pid;
char *executable; /* Absolute executable file path. */
redisDb *db;
dict *commands; /* Command table */
char *requirepass; /* Pass for AUTH command, or NULL */
char runid[CONFIG_RUN_ID_SIZE+1]; /* ID always different at every exec. */
/* Networking */
int port; /* TCP listening port */
char *bindaddr[CONFIG_BINDADDR_MAX]; /* Addresses we should bind to */
int dbnum; /* Total number of configured DBs */
....
}
General:通用字段,包含一些常规的配置和运行时信息。
pid:主进程的进程 ID。executable:可执行文件的绝对路径。db:指向 Redis 数据库的指针。commands:Redis 命令表,存储可用的命令。requirepass:用于 AUTH 命令的密码。runid:Redis 实例的运行 ID。
Networking:网络相关字段,处理连接和通信。
port:TCP 监听端口。bindaddr:要绑定的 IP 地址列表。
AOF/RDB Persistence:AOF(Append-Only File)和 RDB(Redis Database)持久化相关字段。
aof_state:AOF 的状态,ON/OFF/WAIT_REWRITE。
redis数据底层的存储结构图:
redisServer中还包括 主从,集群,luna脚本相关的其他信息
Redis常用的数据类型编码
在 Redis 中,编码是指数据在内存中的表示方式,不同类型的数据可能使用不同的编码方式来优化内存使用和操作效率。以下是 Redis 中常见数据类型的编码方式:
- String 类型:
- int 编码:当字符串可以被解释为整数时,使用 int 编码,节省内存。
- embstr 编码:存长度小于44字节的字符串(redis3.2版本之前是39字节,之后是44字节)存储简短字符串,一次的内存分配;它是只读的,如果对内容进行修改,就会变成raw编码(即使没超过44字节);
- raw 编码:保存长度大于44字节的字符串(redis3.2版本之前是39字节,之后是44字节),可分配多次内存空间
- Hash 类型:
- ziplist 编码:当 Hash 中元素数量较少时,使用 ziplist 编码,节省内存。
- hashtable 编码:当 Hash 中元素数量较多时,使用 hashtable 编码,提供更高的操作效率。
- List 类型:
- ziplist 编码:当 List 中元素数量较少时,使用 ziplist 编码,节省内存。
- linkedlist 编码:当 List 中元素数量较多时,使用 linkedlist 编码,提供更高的操作效率。(redis3.2之前)
- quickList 编码: (redis3.2后,引入quickList )
- Set 类型:
- intset 编码:当 Set 中元素可以被解释为整数时,使用 intset 编码,节省内存。
- hashtable 编码:当 Set 中元素数量较多或包含非整数元素时,使用 hashtable 编码。
- Sorted Set (Zset) 类型:
- ziplist 编码:当 Zset 中元素数量较少时,使用 ziplist 编码,节省内存。
- skiplist 编码:当 Zset 中元素数量较多时,使用 skiplist 编码,提供更高的操作效率。
需要注意的是,Redis 根据数据的大小、类型以及一些配置参数来决定使用何种编码方式。在内部,Redis 会自动进行编码和解码以提供适当的数据操作和内存占用。您可以使用 DEBUG OBJECT 命令来查看特定键的编码信息,以及使用 MEMORY USAGE 命令来获取键的内存占用情况。
使用type命令查看数据类型
> type b
"hash"
> debug object b
"Value at:0x7f2cfa8304c0 refcount:1 encoding:ziplist serializedlength:69 lru:14101881 lru_seconds_idle:4"
> memory usage b
(integer) 416
如果大家比较喜欢我的文档,多谢支持,目前本人正在开始自己的公众号以及抖音视频技术讲解,有喜欢的小伙伴可以微信搜索公众号: 码猿路同学,私聊分析抖音个人账号分析技术视频。感谢各位的关注支持,努力向全栈发展,每天进步一点点。


















 1832
1832

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











