前言
- workqueue的早期内核实现比较简单,高版本的实现比较复杂,本文希望通过其早期实现,为之后分析高版本内核工作队列CMWQ(Concurrency Managed Workqueue)打基础。本文基于2.6.12的内核版本分析。
- workqueue的引入是为了解决中断上下文无法睡眠的问题。在中断处理过程中,如果有些函数可能睡眠,那么可以将它实现后加入工作队列,异步执行。当然,普通的进程上下文,也可以使用工作队列来处理特定的函数。比如srcu中宽限期的统计,就是在srcu中将统计的动作放到了工作队列中执行。以下用WQ代替工作队列。
接口
- WQ的接口非常简单,首先是声明一个WQ,当然也可以不用声明使用系统默认的WQ keventd_wq;然后在要异步执行某个函数的时候(可以是中断上下文,也可以是进程上下文),将该函数加入到工作队列中。我们简单看下内核模块或者中断处理函数怎么使用工作队列,如果不太理解可以跳过,后面看完原理之后再回头看使用方法。
创建队列
- 创建队列有两个接口,分别创建了不同属性的队列,如下:
#define create_workqueue(name) __create_workqueue((name), 0) /* 1 */
#define create_singlethread_workqueue(name) __create_workqueue((name), 1) /* 2 */
1. 常用的工作队列,这种工作队列创建时,每一个cpu都会启动一个工作线程,处理各自CPU上具体工作队列中包含的任务
2. 单线程工作队列,只在CPU0上创建工作线程,并且只处理CPU0工作队列中包含的任务
- 具体的队列创建接口函数如下,输入是工作队列的名字,以及是否创建单线程工作队列的标志,返回值是一个工作队列
struct workqueue_struct *__create_workqueue(const char *name, int singlethread)
添加任务
- 将一个任务加入到工作队列,就可以让这个任务异步执行了,接口如下,输入是之前创建的工作队列和任务
int fastcall queue_work(struct workqueue_struct *wq, struct work_struct *work)
设计框架
workqueue_struct
- 内核定义了两类工作队列,分别是per-cpu工作队列和单线程工作队列,它们的区别在于:per-cpu工作队列在每个cpu上都会启动工作线程,单线程工作队列只在CPU0上启动一个工作线程。
- 假设一个中断处理例程的代码跑在了CPU2上,执行过程中它将自己的一个任务A加入到了工作队列。如果此工作队列是单线程的,最终任务A会在CPU0上由工作线程执行,如果此队列是per-cpu队列,那任务A会由CPU2上的工作线程执行。对于单线程工作队列,由于切换了CPU,它的cache命中率会下降,因此执行效率不如per-cpu这么高。工作队列的数据结构如下:
struct workqueue_struct {
struct cpu_workqueue_struct cpu_wq[NR_CPUS]; /* 1 */
const char *name; /* 2 */
struct list_head list; /* Empty if single thread */ /* 3 */
};
1. 工作队列数据结构包括两个基本的东西,一是CPU上的所有的工作线程,二是给每个工作线程“投喂”任务的具体工作队列,两个东西都与具体的
CPU相关,内核因此将其封装成cpu_workqueue_struct数据结构。
2. 工作队列名字
3. 内核中所有的per-cpu工作队列会被组织成一个链表,链表头保存到workqueues全局变量中,内核每创建一个per-cpu的工作队列,都会将其链
入这个链表,list字段就是用来链入链表的
cpu_workqueue_struct
- CPU上的工作线程和工作队列数据结构是工作队列的核心,如下:
struct cpu_workqueue_struct {
......
struct list_head worklist; /* 1 */
wait_queue_head_t more_work; /* 2 */
wait_queue_head_t work_done; /* 3 */
struct workqueue_struct *wq; /* 4 */
task_t *thread; /* 5 */
......
};
1. 真正组织工作队列中任务的是worklist链表,它是一个单向链表,维护本CPU上所有的任务,本CPU上的工作线程将worklist的第一个任务取出来,执行,然后取第二个,执行,以此循环。新的任务会添加到链表的末尾,由此实现任务处理的先进先出。
2. 当队列中没有任务时,工作线程就休眠,具体的实现就是将当前的工作线程挂入到一个等待队列中,然后让出CPU,睡眠,more_work就是工作
线程睡眠的等待队列,当工作队列中有新任务到来时,唤醒more_work上睡眠的工作线程,继续工作。
3. 当内核想删除工作队列时,如果工作队列中还有线程再处理任务,这是需要等待它结束。work_done等待队列上挂载的进程就是那些等待删除工
作队列的进程,工作线程每处理完一个任务,就会去唤醒队列上的进程。
4. 指向所属的工作队列。
5. 工作线程中运行的任务属于进程上下文,thread就是进程的结构体task_struct,这是工作线程中的任务可以休眠,可以被调度出去根本原因。
work_struct
struct work_struct {
......
unsigned long pending; /* 1 */
void (*func)(void *); /* 2 */
void *data; /* 3 */
......
};
1. 当一个任务添加到工作队列后,它就在等待工作线程处理了,此时需要标记自己处理等待状态,防止该任务被加入到别的工作队列上被重复处
理。pending就用来标记任务是否已经处于等待状态了
2. 任务
3. 任务函数执行时的参数
- 数据结构组织图如下:
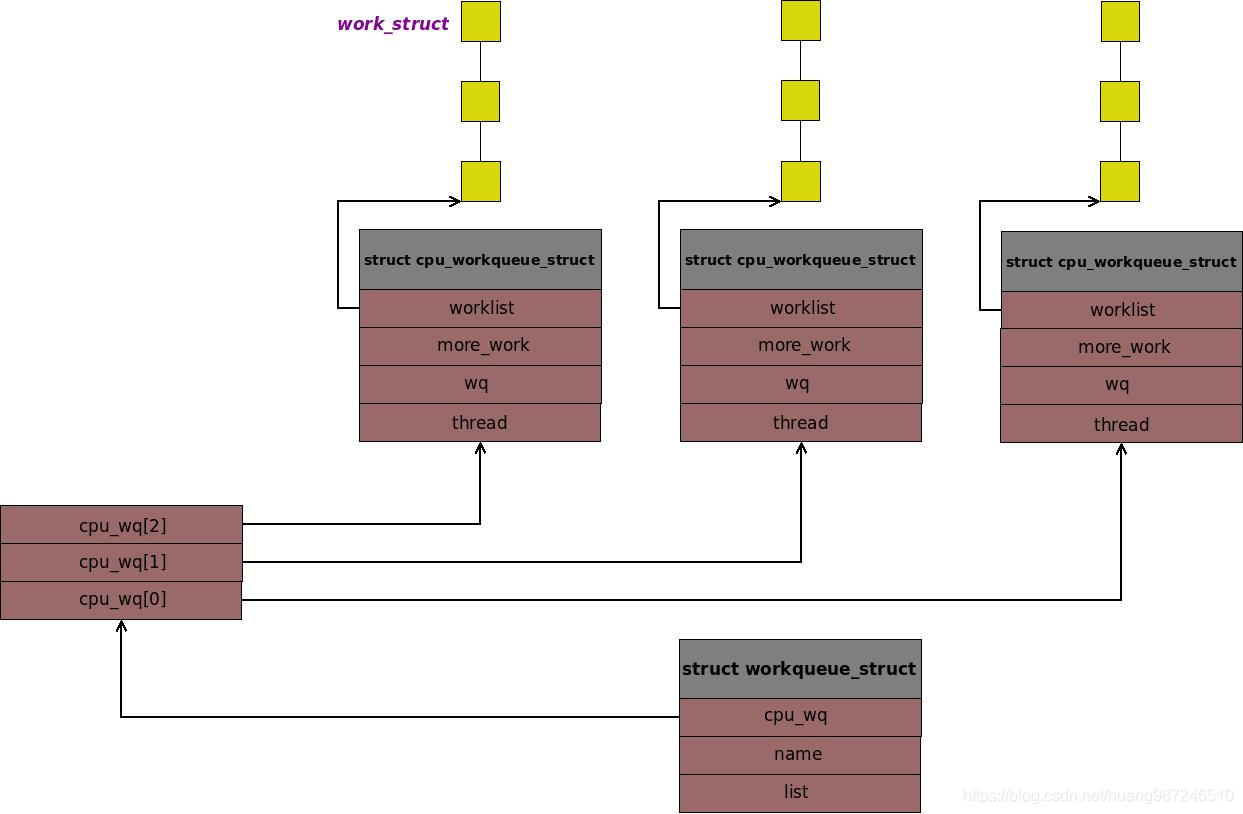
总体框图
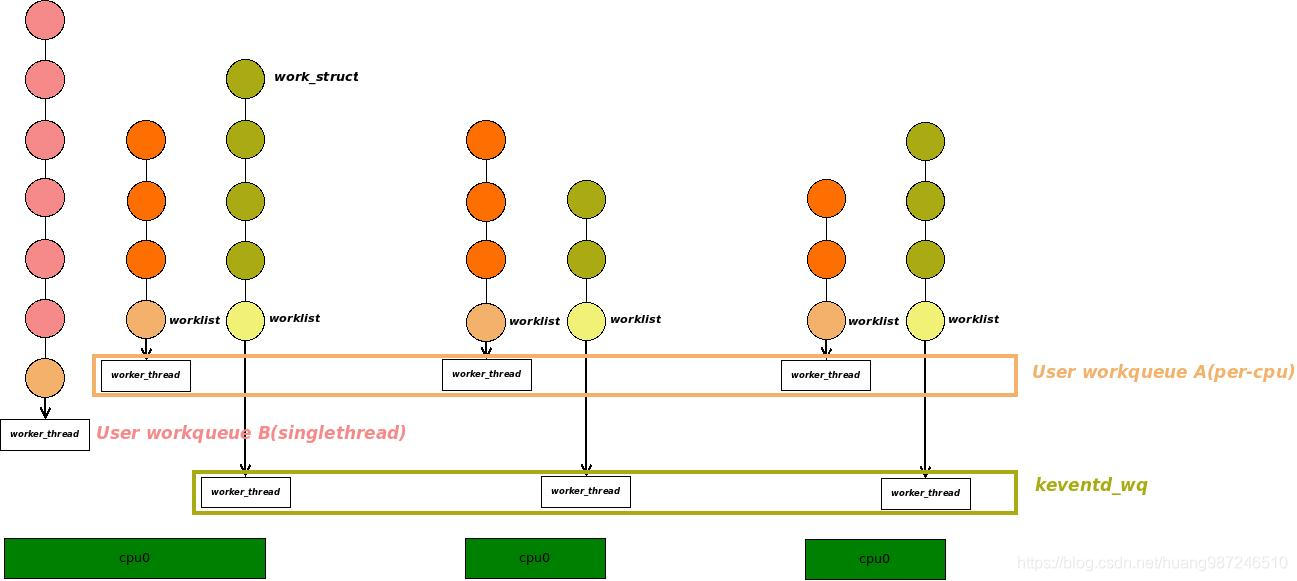
- 工作队列包含两个方向的东西,从上图看,包括了横向的,每个CPU上的工作线程worker_thread;包括了纵向的,每个CPU上的工作队列数据结构。
- 工作队列初始化发生在系统初始化阶段,它会创建一个默认工作队列keventd_wq,用户如果不想定义自己的工作队列,可以通过
schedule_work(work)实现将任务放到默认的工作队列keventd_wq上。 - 对于单线程的工作队列,它在创建时虽然也为每个cpu分配了cpu_wq字段,但除了cpu_wq[0],其它cpu_wq[x]都是空的,系统也只在CPU0上创建内核线程处理任务。当任务到来时会添加到CPU0上的工作队列处理。如上图的User workqueue B所示。对于单线程工作队列,它的优点是内核线程少节约了内存资源和进程pid,缺点是只有一个工作队列,添加到工作队列的任务需要排队,可能造成处理不及时。
- 对于普通的工作队列,系统创建时在所有cpu上都创建了工作线程。每个工作线程处理各自CPU上的具体工作队列上的任务,任务到来时会添加到发起入队的上下文所在cpu的工作队列,如上图User workqueue A所示。对于普通的工作队列,它的优点是内核线程多,添加到工作队列的任务相比单线程,处理更加及时。缺点是当需要工作队列处理的任务很少时,每个cpu上仍然跑了一个工作线程,开销很大。
原理实现
创建队列
struct workqueue_struct *__create_workqueue(const char *name, int singlethread)
{
......
struct workqueue_struct *wq;
struct task_struct *p;
wq = kmalloc(sizeof(*wq), GFP_KERNEL); /* 1 */
wq->name = name;
/* We don't need the distraction of CPUs appearing and vanishing. */
if (singlethread) { /* 2 */
INIT_LIST_HEAD(&wq->list);
p = create_workqueue_thread(wq, 0);
wake_up_process(p);
} else {
list_add(&wq->list, &workqueues); /* 3 */
for_each_online_cpu(cpu) { /* 4 */
p = create_workqueue_thread(wq, cpu); /* 5 */
if (p) {
kthread_bind(p, cpu); /* 6 */
wake_up_process(p);
}
}
......
}
1. 为工作队列分配内存,可以看到无论是单线程工作队列还是普通的工作队列,都分配了cpu_wq字段。
2. 对于单线程工作队列,它的list字段没有作用,因此将其初始化为空。然后在CPU0上创建工作线程并唤醒,加入到内核运行队列中
3. 对于普通的工作队列,它的list用来链入全局的工作队列链表,这里就是这个动作
4. 普通工作队列需要为每个CPU都创建一个工作线程,这里的实现分为两步,第一步是创建工作线程,第二步是将工作线程绑定到对应的CPU
5. 创建工作线程
6. 绑定工作线程并唤醒
void kthread_bind(struct task_struct *k, unsigned int cpu)
{
......
set_task_cpu(k, cpu); /* 6 */
k->cpus_allowed = cpumask_of_cpu(cpu); /* 7 */
}
7. 设置进程所在的cpu
8. 设置进程的亲和性,当将其投入到运行队列之后,调度器在选中此进程投入运行时,会根据cpus_allowed选择要运行在哪个CPU上
添加任务
- 添加任务有两个接口,一个是添加任务到默认工作队列keventd_wa上,一个是添加任务到指定工作队列上。
- 添加任务到默认工作队列,实现如下:
int fastcall schedule_work(struct work_struct *work)
{
return queue_work(keventd_wq, work);
}
int fastcall queue_work(struct workqueue_struct *wq, struct work_struct *work)
{
......
int cpu = get_cpu();
if (!test_and_set_bit(0, &work->pending)) { /* 1 */
if (unlikely(is_single_threaded(wq))) /* 2 */
cpu = 0;
__queue_work(wq->cpu_wq + cpu, work); /* 3 */
}
......
}
1. 标记work处于等待状态,如果work处于等待状态,说明它已经在某个工作队列上等待工作线程处理了,这时不能再重复添加,直接返回
2. 对于单线程的工作队列,它的workqueue_struct->list字段为0,由此作为判断,如果是单线程,将任务添加到CPU0上的工作队列中,否则,
获取当前上下文所在的CPU,添加到对应的工作队列上。
3. 将任务添加到工作队列上
static void __queue_work(struct cpu_workqueue_struct *cwq, struct work_struct *work)
{
......
list_add_tail(&work->entry, &cwq->worklist); /* 4 */
wake_up(&cwq->more_work); /* 5 */
......
}
4. 将任务添加到工作队列的末尾
5. 唤醒工作线程,当工作线程发现队列中没有可以处理的任务时,它会睡眠在more_work等待队列上,此时添加了新的任务,应该唤醒它,让它工
作了
执行任务
- 任务的执行是工作线程负责的东西,首先看一下工作线程的创建过程,工作线程的创建是在工作队列创建的时候,如下:
static struct task_struct *create_workqueue_thread(struct workqueue_struct *wq, int cpu)
{
......
struct task_struct *p; /* 1 */
if (is_single_threaded(wq)) /* 2 */
p = kthread_create(worker_thread, cwq, "%s", wq->name); /* 3 */
else
p = kthread_create(worker_thread, cwq, "%s/%d", wq->name, cpu);
......
}
1. 工作线程拥有task_struct结构体,因此可以被调度,可以睡眠,这里声明要创建的工作线程结构体
2. 对于单线程工作队列和普通的工作队列,它们创建的工作线程都是一样的,差别只在于名字。创建者通过设置线程的亲和性就能控制单线程只能
在CPU0上运行
3. 创建工作线程,传入的第一个参数函数地址,第二个是函数的参数,第三个是工作线程的名字
static int worker_thread(void *__cwq)
{
......
DECLARE_WAITQUEUE(wait, current); /* 4 */
set_current_state(TASK_INTERRUPTIBLE); /* 5 */
while (!kthread_should_stop()) {
add_wait_queue(&cwq->more_work, &wait); /* 6 */
if (list_empty(&cwq->worklist))
schedule();
else
__set_current_state(TASK_RUNNING);
remove_wait_queue(&cwq->more_work, &wait);
if (!list_empty(&cwq->worklist)) /* 7 */
run_workqueue(cwq);
}
......
}
4. 为本线程声明一个等待队列成员wait,当线程空闲时,利用wait将本线程添加到more_work等待队列中,进入睡眠状态
5. 设置内核线程的默认状态为睡眠,但此时并非可以真正实现睡眠,还需要将线程添加到等待队列中,然后主动让出CPU,才能实现睡眠
6. 将自己添加到等待队列中,如果判断到工作队列中没有任务,就让出CPU,进入睡眠状态,否则,将线程设置为运行状态并从等待队列中移除
7. 再此判断工作队列中是否有任务,如果有就执行该任务
static inline void run_workqueue(struct cpu_workqueue_struct *cwq)
{
......
while (!list_empty(&cwq->worklist)) { /* 8 */
struct work_struct *work = list_entry(cwq->worklist.next, /* 9 */
struct work_struct, entry);
void (*f) (void *) = work->func; /* 10 */
void *data = work->data;
list_del_init(cwq->worklist.next); /* 11 */
clear_bit(0, &work->pending); /* 12 */
f(data); /* 13 */
wake_up(&cwq->work_done); /* 14 */
}
}
8. 检查链表是否为空,如果为空说明任务处理完了,直接返回
9. 取出链表中的第一个任务
10. 取出任务的函数和参数
11. 将任务从链表中删除
12. 紧接着就要执行任务了,因此清除任务的等待标记。
13. 执行任务
14. 每当执行完一个任务,可能会有删除工作队列的进程或者flush工作队列的进程睡眠在 work_done等待队列上,这里是一个唤醒时机。需要将上
面的进程唤醒。
缺点
- 传统的工作队列设计,整个分析下来,从原理上看比较简单,但适用的场景也比较有限。下面分析几点缺陷:
- SMP扩展性。普通的工作队列,每创建一个用户的工作队列,就要在每个CPU上创建一个工作线程,虽然每个线程在没有任务时会睡眠,但线程本身的task_struct毕竟也是资源,占用了系统的pid资源。如果工作队列要处理的任务比较少,那么大多数因为工作队列而创建的内核线程是没有工作的。这是一种资源浪费。在系统核数很多的情况下,每个核都要创建工作线程,更显浪费,可能系统一起来进程剩余的pid资源不多了。还有一些情况,驱动的实现者明明可以用默认的工作队列,但因为搞不清楚原理,而去创建自己的工作队列,这样的驱动也会浪费很多pid资源。因此传统的工作队列存在SMP扩展性问题。
- 任务并发性。普通工作队列是每个核上都有工作线程,相对单线程的工作队列,任务处理会更及时。但仔细分析一个场景,假设现在有一个中断上下文运行在CPU2上,它想要异步执行任务WORK_A,因此将WORK_A加入到之前创建的工作队列WQ上,最终会添加到CPU2对应的worklist上,但如果CPU2对应的worklist也有很多任务等待处理,WORK_A还是需要排队,讲究先来后到。本质上,任务添加到每个CPU的worklist上还是要排队,如果此时别的CPU的worklist是空的,它也不能转移到上面去。因为传统的工作队列没有机制来处理这种情况,一旦任务添加到worklist上就只能死等。
- 线程数量二元化。传统工作队列只有两种类型,一种单线程工作队列,一种普通工作队列。单线程,适用于UP系统或者核数很少的系统。普通工作队列如果与核数相关,核数越多创建的线程数量越多。但实际使用时,大多数场景下,我们用不了这么多内核线程来处理任务,也没有这么多任务被处理。我们需要根据业务需要来动态创建线程。理想的情况下,随着要执行任务的增多,系统多创建一些线程,当执行的任务减少时,系统删除一些线程。
- 现代的内核工作队列CMWQ(Concurrency Managed Workqueue)就是为了解决上述这些问题而设计的。








 本文剖析了Linux内核工作队列机制,包括其在早期版本中的实现原理,以及如何解决中断上下文无法睡眠的问题。文章详细介绍了创建队列、添加任务、执行任务的过程,并分析了传统工作队列的局限性。
本文剖析了Linux内核工作队列机制,包括其在早期版本中的实现原理,以及如何解决中断上下文无法睡眠的问题。文章详细介绍了创建队列、添加任务、执行任务的过程,并分析了传统工作队列的局限性。


















 2458
2458

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











