







 本文详细介绍了K折交叉验证的原理,包括数据集划分、模型评估和性能平均。K折交叉验证在模型选择、参数调优、特征选择等方面具有重要作用,能有效评估模型的泛化能力,提高模型的稳定性和鲁棒性。通过案例分析展示了如何在二分类问题中应用K折交叉验证选择最优模型。
本文详细介绍了K折交叉验证的原理,包括数据集划分、模型评估和性能平均。K折交叉验证在模型选择、参数调优、特征选择等方面具有重要作用,能有效评估模型的泛化能力,提高模型的稳定性和鲁棒性。通过案例分析展示了如何在二分类问题中应用K折交叉验证选择最优模型。
本文重点
在机器学习和数据科学的领域中,模型的性能评估是至关重要的一环。为了准确地评估模型的泛化能力,避免过拟合和欠拟合的问题,我们通常需要将数据集划分为训练集和测试集。然而,当数据集较小或模型较为复杂时,简单的训练集-测试集划分可能不足以给出可靠的评估结果。这时,K折交叉验证(K-Fold Cross-Validation)便成为了一种常用的模型评估方法。
K折交叉验证的原理
K折交叉验证是一种将数据集划分为K个子集(或称为“折”)的方法,然后每次将K-1个子集作为训练集,剩下的一个子集作为验证集(或称为“测试集”)来评估模型的性能。这个过程会重复K次,每次选择一个不同的子集作为验证集,最终将K次的结果进行平均,以得到对模型性能的总体评估。
具体来说,K折交叉验证的步骤如下:
将原始数据集随机地划分为K个互不重叠的子集,每个子集的样本数量大致相等。
对于每个k=1到K:
将第k个子集作为验证集,其余K-1个子集作为训练集。
在训练集上训练模型,并在验证集上评估模型的性能。
记录模型的性能指标(如准确率、召回率、F1分数等)。
将K次评估的结果进行平均,得到对模型性能的总体评估。
如下所示,将训练数据分为几份
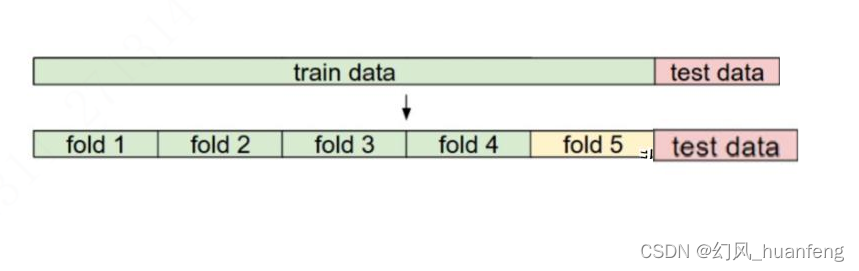
具体来说

 订阅专栏 解锁全文
订阅专栏 解锁全文


















 1498
1498

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











