







 本文介绍了学习爬虫的原因,包括大创项目需求和个人技能提升。讲解了爬虫的合法性和风险,强调了如何避免成为恶意爬虫,以及使用requests库进行HTTP请求和BeautifulSoup解析HTML的基本技巧。
本文介绍了学习爬虫的原因,包括大创项目需求和个人技能提升。讲解了爬虫的合法性和风险,强调了如何避免成为恶意爬虫,以及使用requests库进行HTTP请求和BeautifulSoup解析HTML的基本技巧。
前言
-----------------这仅仅只是入门级别
参考入门视频
为什么要学爬虫?
- 大创项目的需要
- python知识的巩固
- 自己需要这个技能
什么是爬虫:通过编写程序,模拟浏览器上网,然后让其去互联网上抓取数据的过程
爬虫究竟是合法还是违法的?
- 在法律中是不被禁止
- 具有违法风险【善意爬虫 恶意爬虫】
爬虫带来的风险可以体现在如下方面:【恶意爬虫特点】
- 爬虫干扰了被访问网站的正常运营
- 爬虫抓取了收到法律保护的特定类型的数据或信息
如何在使用编写爬虫的过程中避免变成恶意爬虫呢?
- 时常的优化自己的程序,避免干扰忧被访问网站的正常运行【占用1/3流量就违反了】
- 在使用,传播爬取到的数据时,审查抓取到的内容,如果发现了涉及到用户隐私商业机密等敏感内容需要及时停止爬取或传播
- 不能侵犯别人的商业利益
HTTP
请求方式常用两种,GET和POST,POST中可以包含发送给服务器的信息,而爬虫是获取数据,因此爬虫主要会用GET方法
http请求

请求行包含方法类型,资源路径和协议版本

请求头会包含一些给服务器的信息
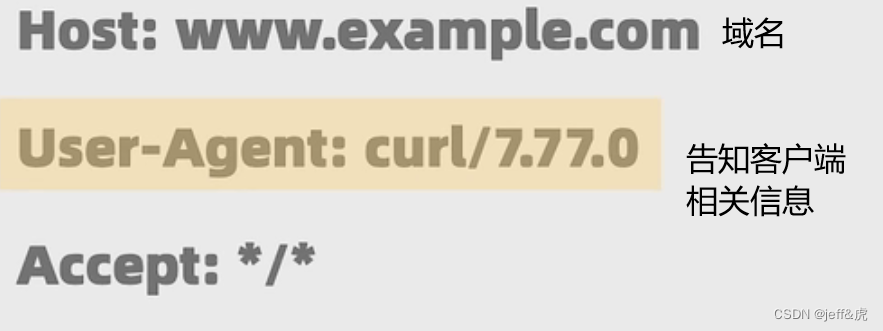
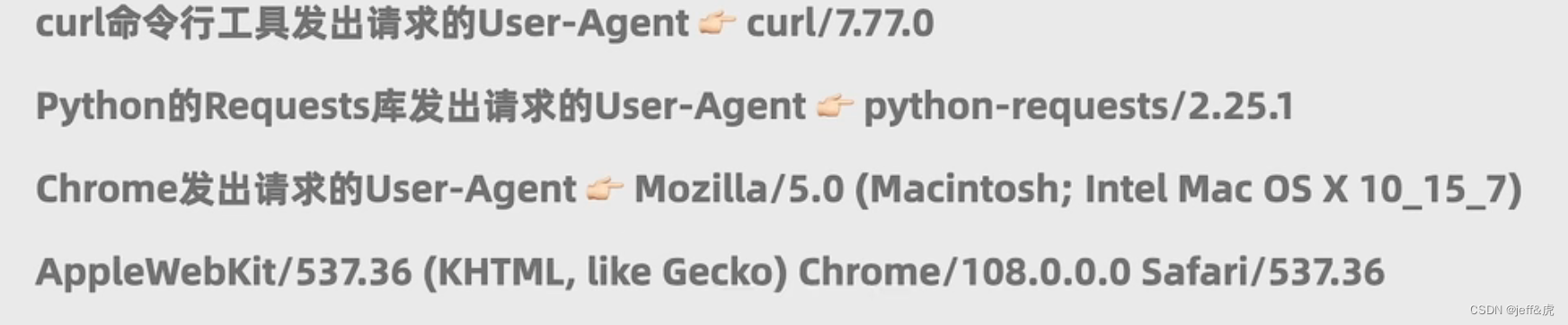
上图中提到的相关信息用于判断是浏览器发出来的还是Request库发出来的,以及相应的版本
accept用于告诉服务器客户端想要接收的数据类型

请求体用于传给客户端给服务器的其他任意数据,而GET方法的请求体一般是空的。
HTTP响应

状态行包包合了协议版本、状态码、狀态消息

响应头包含一些告知客户端的信息,如日期date,返回内容的类型及编码格式content-type,响应体就是服务器想给客户端的数据内容
python Requests
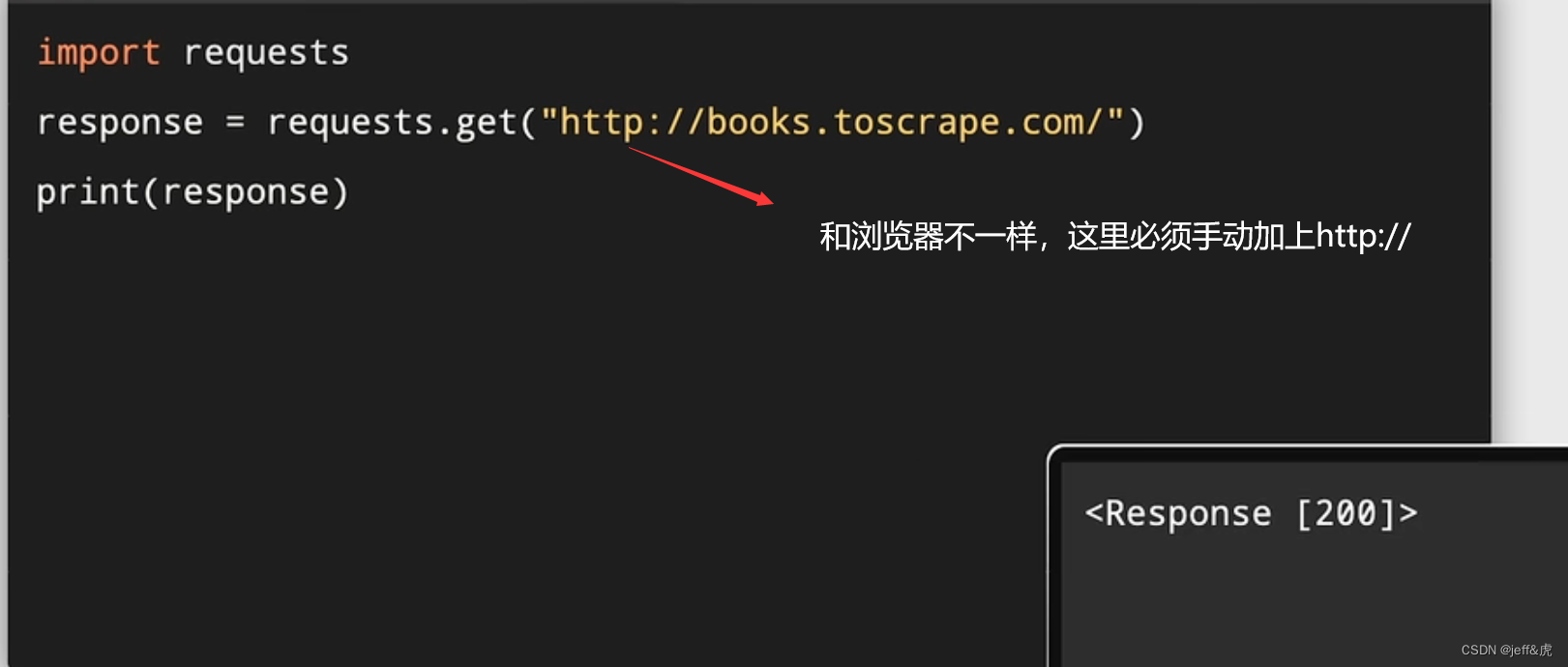

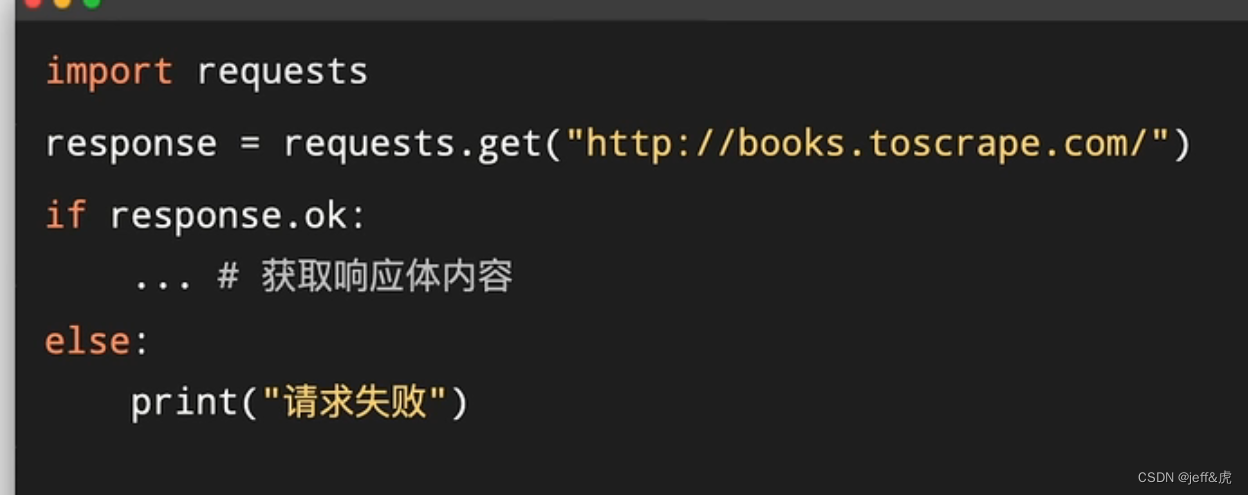
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











