scrapy 爬取起点中文网首页的每周强推作品的详情介绍
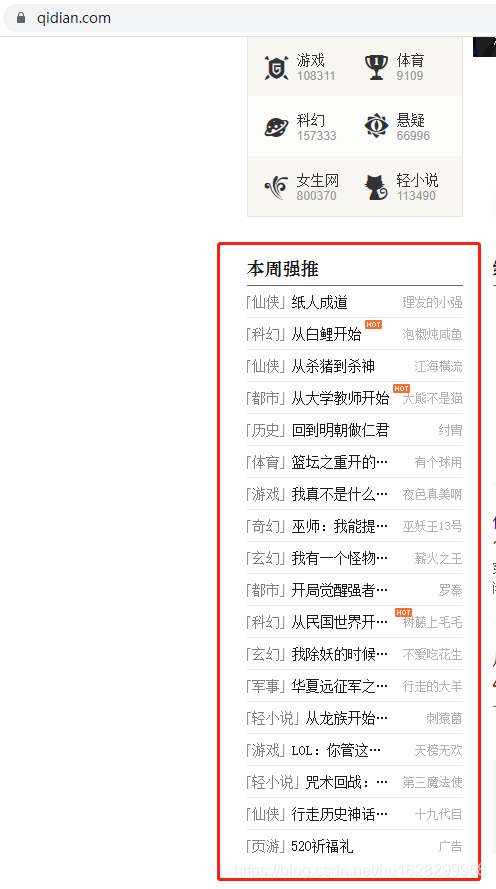
从列表页跳转到详情页
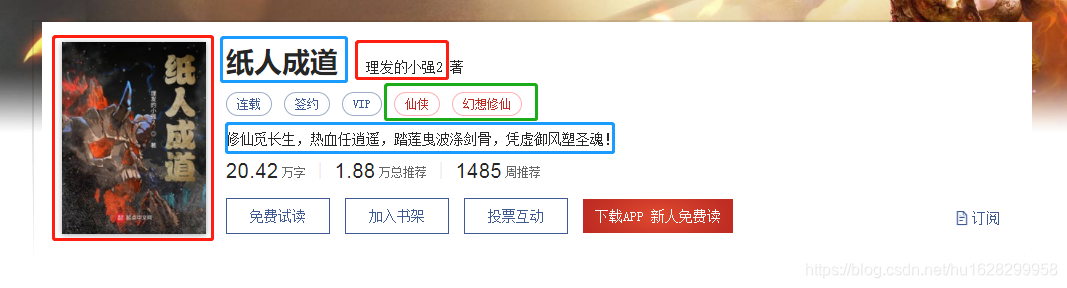
保存的数据
封面图
小说名
作者
类型
简介
import scrapy
# 起点首页 本周推荐
class WeektjSpider(scrapy.Spider):
name = 'weekTJ'
allowed_domains = ['qidian.com']
start_urls = ['http://qidian.com/']
def parse(self, response):
titles = response.css(".book-list-wrap")
for title in titles:
# print(title.extract())
# print(title.css(".book-list-wrap h3::text").extract())
title_arr = title.css(".book-list-wrap h3::text").extract()
if("本周强推" in title_arr):
# print(title_arr)
# 作者列表 剔除广告
# list = title.css(".author::text").extract()
# 这里我直接在 a 标签的 href 里面 做判断
# print(list)
# print(title.extract())
xiaoshuo_names = title.css(".name::attr(href)").extract()
for href in xiaoshuo_names:
# 剔除游戏广告 先将 href 转小写
if 'game' not in (href.lower()):
yield scrapy.Request(url= "http:"+href, callback=self.new_parse)
def new_parse(self, response):
details = response.css(".book-detail-wrap")
for detail in details:
# 去掉img \n
img = detail.css("#bookImg img::attr(src)").extract()[0]
if "\n" in img:
img = img[0:-1]
info = {
"img": "http:"+ img,
"title": detail.xpath("//div/div/h1/em/text()").get(),
"author": detail.css(".writer::text").extract()[0],
"type": detail.css(".book-info .tag a::text").extract(),
# html 标签
"remark": detail.css(".intro::text").extract()[0]
}
print(info)


























 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









