







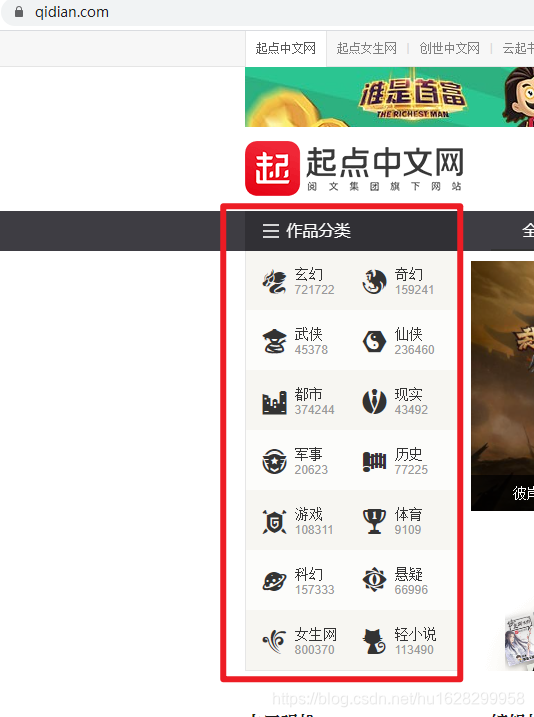
scrapy 爬取起点中文网的作品分类
创建项目
scrapy startproject qidian
创建爬虫
scrapy genspider qidianSpider qidian.com
核心代码
import scrapy
# 集成 scrapy.Spider 类
class QidianSpider(scrapy.Spider):
# 爬虫名字 唯一
name = 'qidian'
# 允许采集的域名
allowed_domains = ['qidian.com']
# 开始采集的网站
start_urls = ['http://qidian.com/']
# 解析响应数据 提取数据 或者网址等 response 网页源码
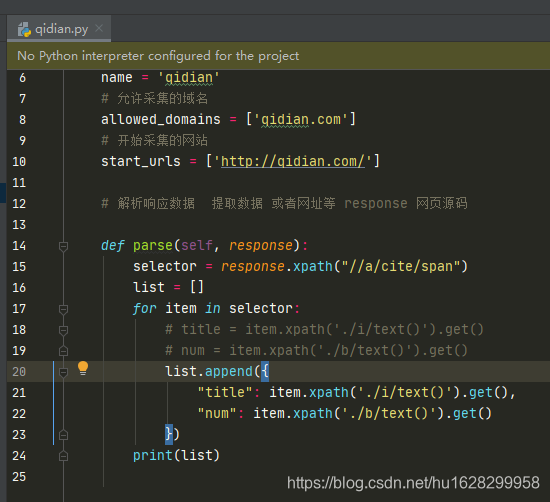
def parse(self, response):
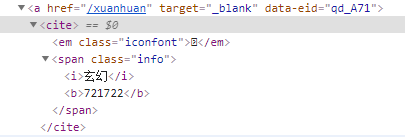
selector = response.xpath("//a/cite/span")
list = []
for item in selector:
# title = item.xpath('./i/text()').get()
# num = item.xpath('./b/text()').get()
list.append({
"title": item.xpath('./i/text()').get(),
"num": item.xpath('./b/text()').get()
})
print(list)



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









