






费劲巴拉的花费半天时间 画了一下 bio时序图,最后发现 关键的就 4 个方法
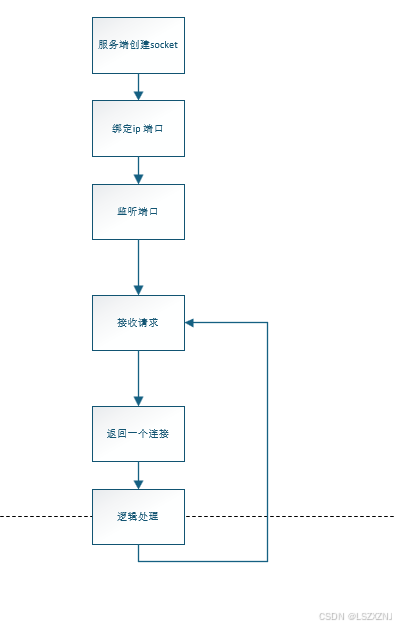
一个网络连接,就是 一个 int 型的 数字,一个数字 代表一个连接。
服务端创建一个 socket,比如数字是 1440
操作系统就会在 1440 上监听 连接请求,当接收到连接请求时,会返回一个 新的数字,比如 1864
后续 服务端 和 客户端 就是通过这个 1864 来进行数据传输的。
操作系统 此时 仍然在 1440 上监听 连接请求,如果有新的连接过来,会再返回一个 新的数字,比如 1880,以此类推。
1440 是固定的 一个用于服务端监听连接的,新的连接生成的 是 随机的。
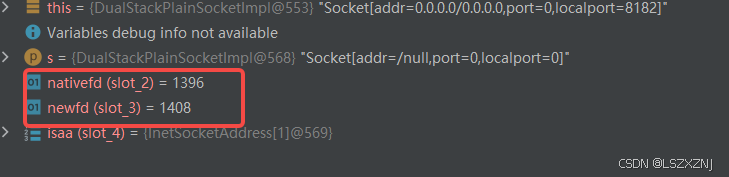

这里服务端的 socket 编码是 1396
接收到了 两个连接,分别是 1408 和 1400
通过命令查看,再 8182端口上, 51621端口 和 51737端口 是这次的连接。所以 这里查看的 是 连接 ip:port,不是 socket的编码
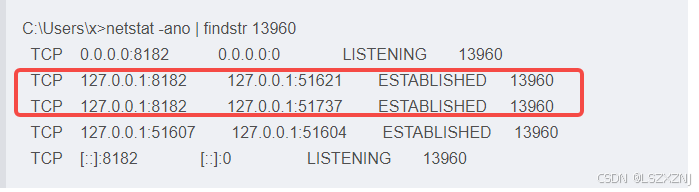
需要注意的是,这里accept 和 socket的读写操作都是 阻塞型的,也就是 会消耗掉一个 线程。这也就是 BIO 效率低的原因。
大概花了5h,就简单记录下吧。

















 1390
1390

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









