




 本文详细介绍了如何使用Caffe工具包中的extract_features.bin程序来提取深度学习模型的特征。包括设置参数如网络模型参数(pretrained_net_param)、网络配置原型(feature_extraction_proto_file)、特定层特征(extract_feature_blob_name)等,并解释了存储方式(db_type)和设备选择(CPU/GPU)。同时,提供了读取和转换提取特征的数据文件(lmdb)的Python示例代码。
本文详细介绍了如何使用Caffe工具包中的extract_features.bin程序来提取深度学习模型的特征。包括设置参数如网络模型参数(pretrained_net_param)、网络配置原型(feature_extraction_proto_file)、特定层特征(extract_feature_blob_name)等,并解释了存储方式(db_type)和设备选择(CPU/GPU)。同时,提供了读取和转换提取特征的数据文件(lmdb)的Python示例代码。
提取特征
extract_features pretrained_net_param feature_extraction_proto_file extract_feature_blob_name1[,name2,…] save_feature_dataset_name1[,name2,…] num_mini_batches db_type [CPU/GPU] [DEVICE_ID=0]
参数:
1.extract_features:为可执行文件
2.pretrained_net_param:表示网络模型参数,保存了,事先训练好的网络参数,具体的文件是bvlc_reference_caffenet.caffemodel。
3.feature_extraction_proto_file,网络配置原型,imagenet_val.prototxt文件
4.extract_feature_blob_name1:表示特定层的特征,比如fc7,conv5,pool5,这个需要和imagenet_val.prototxt文件里面定义的一致。
5.save_feature_dataset_name1 :表示需要存储提取到的特征目录,这个目录需要不存在,由程序自动创建。
6.num_mini_batches:为批处理个数,这个乘以imagenet_val.prototxt里面配置的batch_size得到的就是总共需要提取的图片的个数。参看上图。
7.db_type:表示提取到的特征按着什么方式存储,目前由两种方式,lmdb和leveldb,但是我使用leveldb无法提取特征,不知道怎么回事。
8.GPU/CPU,默认是使用CPU提取特征(较慢),后面可以指定GPU,以及具体的GPU个数。
例如:在caffe根目录下进行
./build/tools/extract_features.bin /home/htt/PoseNet_caffemodle/weights_kingscollege.caffemodel /home/htt/PoseNet_caffemodle/train_kingscollege.prototxt icp9_out /home/htt/workspace/result/snet_data/features 340 lmdb
注:生成特种文件的文件夹是系统自动生成/home/htt/workspace/result/snet_data/features,既我们只创建snet_data文件夹
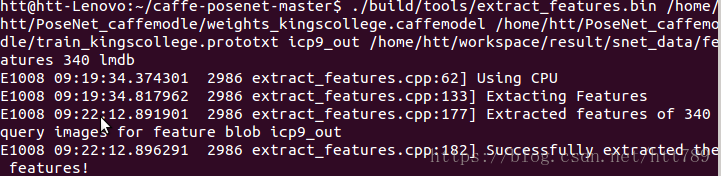
会生成两个数据文件data.lmdb和lock.mdb
读取和转换
import lmdb
from caffe.proto import caffe_pb2
import caffe
import numpy as np
fea_lmdb = lmdb.open("/home/htt/caffe-posenet-master/examples/temp/features")
txn = fea_lmdb.begin()
with fea_lmdb.begin() as txn:
cursor=txn.cursor()
for key,value in cursor:
print ‘key:’,key
datum = caffe.proto.caffe_pb2.Datum()
datum.ParseFromString(value)
flat_x = np.fromstring(datum.data, dtype=np.uint8)
print flat_x
fea_lmdb.close()

















 463
463

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









