



HashMap的结构是数组(table对应着Hash值)、链表(链表节点为Node)、红黑树结构
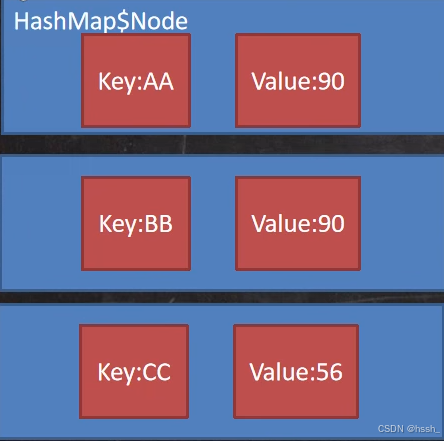
Map中的数据是以Node为单位存储数据的,一个Node包含Key、Value、Hash值。其中Hash值决定了此Node挂在table数组上的哪个索引。上图为三个HashMap$Node对象。
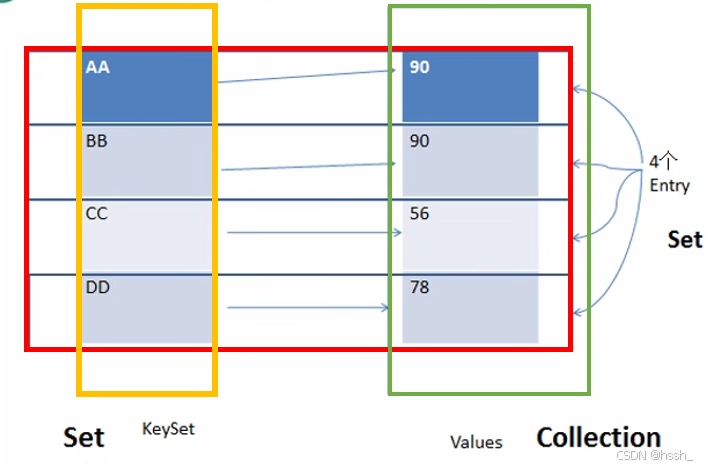
为了便利程序员,除基本的table-Node的架构外还会额外建立一个EntrySet的Set类型集合,该集合中元素的类型为Entry。而Entry表面是Entry类型实际上还是HashMap$Node类型,是因为HashMap$Node实现了Entry接口,即把保存了实际数据的Node包装成Entry,此时Entry也就有了相应的Key和Value,不过只是指向真实值的索引而并非真实值的地址(真实值地址还是保存在table-Node的Node节点中)。整体结构为:EntrySet<Entry<key,value>>,即上图红框所示的集合。 当把HashMap$Node节点封装到Entry后就方便遍历。因为Entry提供了两个方法:getkey和getvalue方法。同样的还会将所有的Key单独封装成一个Set类型的集合Keyset(黄色框所示集合),将所有的Value封装成一个Collection类型的集合Values(绿色框所示集合),封装方式同EntrySet。
由以上结构就催生出了遍历HashMap的三种方式分别是通过黄框遍历、通过绿框遍历、通过红框遍历。
1.先取出所有Key,再通过Key取出对应的value(黄框遍历法)
Set keyset = map.keySet(); //得到封装好的所有Key即黄框
for (Object key : keyset) { //用增强for的方式遍历
System.out.println(key + "-" + map.get(key));
}
Iterator iterator = keyset.iterator();//用迭代器遍历
while (iterator.hasNext()) {
Object key = iterator.next();
System.out.println(key + "-" + map.get(key));
}
2.直接取出所有Value(绿框遍历法)
Collection values = map.values();//得到所有Value的集合即lv框
for (Object value : values) {//用增强for直接遍历
System.out.println(value);
}
3.通过EntrySet来获取K-V(红框遍历法)
Set entrySet = map.entrySet();//得到红框所示集合
for (Object entry : entrySet) {//用增强for遍历需要把接收到的entrySet向下转型为Map.Entry,因为Map.Entry可以使用getKey和getvalue方法。
Map.Entry m = (Map.Entry) entry;//将Object类型的 entry 转成 Map.Entry类型
System.out.println(m.getKey() + "-" + m.getValue());
}

















 60万+
60万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









