







pymysql模块与mysql数据库交互连接步骤:
1、创建数据库连接对象 db=pymysql.connect(xx,xx,xx,xx,xx)
2、创建游标对象 cursor=db.cursor()
3、执行sql命令 cursor.execute(sql语句,[xx,xx])
4、提交到数据库执行 db.commit()
5、关闭游标 cursor.close()
6、断开数据库连接 db.close()
pymysql之execute方法
问题:使用pymysql模块在列表中插入一条数据
数据库名称:doubandb 表:doubantab
#表字段:
name varchar(50)
message varchar(1000)
#sql语句
create database doubandb charset utf8;
use database;
create table doubantab(
name varchar(50),
message varchar(1000)
)charset=utf8;
desc doubantab;
例子:
#单行插入execute()
import pymysql
# 1、创建数据库连接对象
#Python3.8格式需要
db=pymysql.connect(host='localhost',user='root',password='xxx',database='doubandb',charset='utf8')
# 2、创建游标对象
cursor=db.cursor()
# 3、执行sql命令
ins='insert into doubantab values(%s,%s);'
cursor.execute(ins,['芬奇','2021-10-28'])
# 4、提交到数据库执行
db.commit()
# 5、关闭游标
cursor.close()
# 6、断开数据库连接
db.close()
#多行插入executemany()
import pymysql
# 1、创建数据库连接对象
#Python3.8格式需要
db=pymysql.connect(host='localhost',user='root',password='xxx',database='doubandb',charset='utf8')
# 2、创建游标对象
cursor=db.cursor()
# 3、执行sql命令
ins='insert into doubantab values(%s,%s);'
file_li=[
("大话西游","20211111"),
("喜剧之王","111111")
]
cursor.executemany(ins,file_li)
# 4、提交到数据库执行
db.commit()
# 5、关闭游标
cursor.close()
# 6、断开数据库连接
db.close()
豆瓣爬取并存储案例:
#实现代码
import pymysql
import urllib.request
import re
import time
import random
class DoubanSpider:
#1、定义常量
def __init__(self):
self.url='https://movie.douban.com/chart'
self.headers={'User-Agent':'Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; InfoPath.3; .NET4.0C; .NET4.0E'}
self.item=[]
self.db = pymysql.connect(host='localhost', user='root', password='xxx', database='doubandb', charset='utf8')
# 2、创建游标对象
self.cursor = self.db.cursor()
#2、获取响应内容
def get_html(self):
req=urllib.request.Request(url=self.url,headers=self.headers)
res=urllib.request.urlopen(req)
html=res.read().decode()
#直接调用解析函数
self.parse_html(html)
#3、解析提取数据函数
def parse_html(self,html):
#使用非贪婪匹配
regex = '<tr class="item">.*?title="(.*?)">.*?<p class="pl">(.*?)</p>'
pattern=re.compile(regex,re.S)
r_list=pattern.findall(html)
#直接调用数据处理函数
self.save_html(r_list)
# 4、数据处理函数
def save_html(self,r_list):
for r in r_list:
#转化为[(),(),()]形式
self.item.append((r[0].strip(),r[1].strip()[0:5]))
#5、程序入口
def run(self):
#发送响应请求
self.get_html()
ins = 'insert into doubantab values(%s,%s);'
self.cursor.executemany(ins, self.item)
self.db.commit()
self.cursor.close()
self.db.close()
#控制数据抓取的频率
time.sleep(random.randint(1,2))
if __name__=='__main__':
spider=DoubanSpider()
spider.run()
print("爬取成功!")
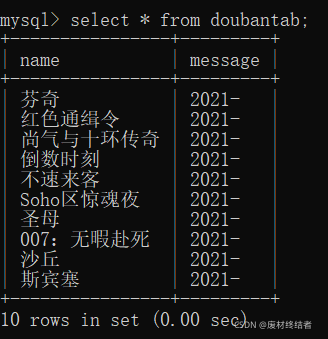
运行结果:
(这里由于第二个数据太长在处理的时候切片截取的前五个字符)



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











