







受 PromQL 的启发,Loki 也有自己的查询语言,称为 LogQL,它就像一个分布式的 grep,可以聚合查看日志。和 PromQL 一样,LogQL 也是使用标签和运算符进行过滤的,主要有两种类型的查询功能:
- 查询返回日志行内容
- 通过过滤规则在日志流中计算相关的度量指标
日志查询
一个基本的日志查询由两部分组成。
log stream selector(日志流选择器)log pipeline(日志管道)
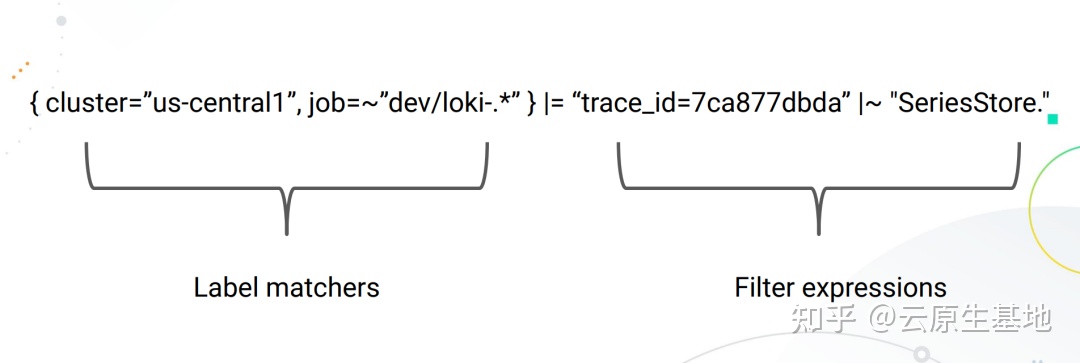
由于 Loki 的设计,所有 LogQL 查询必须包含一个日志流选择器。一个 Log Stream 代表了具有相同元数据(Label 集)的日志条目。
日志流选择器决定了有多少日志将被搜索到,一个更细粒度的日志流选择器将搜索到流的数量减少到一个可管理的数量,通过精细的匹配日志流,可以大幅减少查询期间带来资源消耗。
而日志流选择器后面的日志管道是可选的,用于进一步处理和过滤日志流信息,它由一组表达式组成,每个表达式都以从左到右的顺序为每个日志行执行相关过滤,每个表达式都可以过滤、解析和改变日志行内容以及各自的标签。
下面的例子显示了一个完整的日志查询的操作:
{container="query-frontend",namespace="loki-dev"} |= "metrics.go" | logfmt | duration > 10s and throughput_mb < 500该查询语句由以下几个部分组成:
- 一个日志流选择器
{container="query-frontend",namespace="loki-dev"},用于过滤loki-dev命名空间下面的query-frontend容器的日志 - 然后后面跟着一个日志管道
|= "metrics.go" | logfmt | duration > 10s and throughput_mb < 500,该管道表示将筛选出包含metrics.go这个词的日志,然后解析每一行日志提取更多的表达式并进行过滤
为了避免转义特色字符,你可以在引用字符串的时候使用单引号,而不是双引号,比如 `\w+1` 与 "\w+" 是相同的。
Log Stream Selector
日志流选择器决定了哪些日志流应该被包含在你的查询结果中,选择器由一个或多个键值对组成,其中每个键是一个日志标签,每个值是该标签的值。
日志流选择器是通过将键值对包裹在一对大括号中编写的,比如:
{app="mysql", name="mysql-backup"}上面这个示例表示,所有标签为 app 且其值为 mysql 和标签为 name 且其值为 mysql-backup 的日志流将被包括在查询结果中。
其中标签名后面的 = 运算符是一个标签匹配运算符,LogQL 中一共支持以下几种标签匹配运算符:
=: 完全匹配!=: 不相等=~: 正则表达式匹配!~: 正则表达式不匹配
例如:
{name=~"mysql.+"}{name!~"mysql.+"}{name!~"mysql-\\d+"}
适用于 Prometheus 标签选择器的规则同样适用于 Loki 日志流选择器。
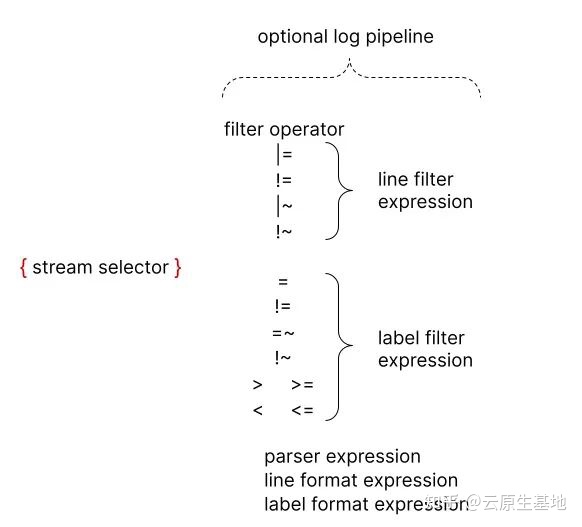
Log Pipeline
日志管道可以附加到日志流选择器上,以进一步处理和过滤日志流。它通常由一个或多个表达式组成,每个表达式针对每个日志行依次执行。如果一个表达式过滤掉了日志行,则管道将在此处停止并开始处理下一行。一些表达式可以改变日志内容和各自的标签,然后可用于进一步过滤和处理后续表达式或指标查询。
一个日志管道可以由以下部分组成。
- 日志行过滤表达式
- 解析器表达式
- 标签过滤表达式
- 日志行格式化表达式
- 标签格式化表达式
- Unwrap 表达式
其中 unwrap 表达式是一个特殊的表达式,只能在度量查询中使用。
日志行过滤表达式
日志行过滤表达式用于对匹配日志流中的聚合日志进行分布式 grep。
编写入日志流选择器后,可以使用一个搜索表达式进一步过滤得到的日志数据集,搜索表达式可以是文本或正则表达式,比如:
{job="mysql"} |= "error"{name="kafka"} |~ "tsdb-ops.*io:2003"{name="cassandra"} |~ "error=\\w+"{instance=~"kafka-[23]",name="kafka"} != "kafka.server:type=ReplicaManager"
上面示例中的 |=、|~ 和 != 是过滤运算符,支持下面几种:
|=:日志行包含的字符串!=:日志行不包含的字符串|~:日志行匹配正则表达式!~:日志行与正则表达式不匹配
过滤运算符可以是链式的,并将按顺序过滤表达式,产生的日志行必须满足每个过滤器。当使用 |~和 !~ 时,可以使用 Golang 的 RE2 语法的正则表达式,默认情况下,匹配是区分大小写的,可以用 (?i) 作为正则表达式的前缀,切换为不区分大小写。
虽然日志行过滤表达式可以放在管道的任何地方,但最好把它们放在开头,这样可以提高查询的性能,当某一行匹配时才做进一步的后续处理。例如,虽然结果是一样的,但下面的查询 {job="mysql"} |= "error" |json | line_format "{
{.err}}" 会比 {job="mysql"} | json | line_format "{
{.message}}" |= "error" 更快,日志行过滤表达式是继日志流选择器之后过滤日志的最快方式。
解析器表达式
解析器表达式可以解析和提取日志内容中的标签,这些提取的标签可以用于标签过滤表达式进行过滤,或者用于指标聚合。
提取的标签键将由解析器进行自动格式化,以遵循 Prometheus 指标名称的约定(它们只能包含 ASCII 字母和数字,以及下划线和冒号,不能以数字开头)。
例如下面的日志经过管道 | json 将产生以下 Map 数据:
{ "a.b": { "c": "d" }, "e": "f" }
->
{a_b_c="d", e="f"}在出现错误的情况下,例如,如果该行不是预期的格式,该日志行不会被过滤,而是会被添加一个新的 __error__ 标签。
需要注意的是如果一个提取的标签键名已经存在于原始日志流中,那么提取的标签键将以 _extracted 作为后缀,以区分两个标签,你可以使用一个标签格式化表达式来强行覆盖原始标签,但是如果一个提取的键出现了两次,那么只有最新的标签值会被保留。
目前支持 json、logfmt、pattern、regexp</
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 3387
3387

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











