






为了将这些模型应用于密度估计问题,我们需要一种 在给定观测数据集的情况下确定合适参数值的方法(主要聚焦于最大化似然函数)。
密度估计问题的本质
密度估计是要从观测数据中推断出数据的潜在概率分布。具体步骤是:
- 选择模型族:假设数据来自某个参数化的分布族(如正态分布、指数分布等)
- 确定参数:找到最能解释观测数据的参数值
- 得到密度函数:用估计的参数构建完整的概率密度函数
为什么需要参数估计
假设我们观察到一组身高数据,想要估计整个人群的身高分布:
- 模型假设:身高服从正态分布 N(μ, σ²)
- 问题:μ 和 σ² 是未知的
- 目标:从观测数据中找出最合适的 μ 和 σ² 值
没有参数值,我们只有一个"空壳"模型,无法进行预测或推断。
为什么最大似然是合理的
- 直观性:如果数据真的来自某个分布,那么使数据出现概率最大的参数最有可能是真实参数
- 频率主义解释:在大量重复实验中,真实参数使观测数据出现的概率最大
- 信息论解释:MLE等价于最小化模型分布与经验分布之间的KL散度
MLE等价于最小化模型分布与经验分布之间的KL散度经验分布 具体例子:一维高斯分布
假设真实数据来自 N(2,1)N(2, 1)N(2,1),我们用 N(μ,1)N(\mu, 1)N(μ,1) 来拟合:
import numpy as np
from scipy.stats import norm
# 生成数据
np.random.seed(42)
data = np.random.normal(2, 1, 1000)
# 经验KL散度
def empirical_kl(data, mu):
cross_entropy = -np.mean(norm.logpdf(data, mu, 1))
return cross_entropy # 忽略常数项
# 遍历不同 μ
mus = np.linspace(0, 4, 100)
kls = [empirical_kl(data, mu) for mu in mus]
# KL 最小的 μ
optimal_mu = mus[np.argmin(kls)] # ≈ 2.0
# MLE 估计
mle_mu = np.mean(data) # ≈ 2.0
✅ 最小KL散度 和 最大似然估计 给出相同的最优 μ\muμ!
似然函数的定义
假设我们有 n 个观测数据样本 x1,x2,…,xnx_1, x_2, \dots, x_nx1,x2,…,xn,这些数据来自某个概率分布模型,该模型的参数为 θ。似然函数 L(θ∣x1,x2,…,xn)L(\theta \mid x_1, x_2, \dots, x_n)L(θ∣x1,x2,…,xn) 定义为:在给定参数 θ 的条件下,观测到这些具体数据样本的概率(或概率密度)。
数学上,它被写成:
L(θ∣x1,x2,…,xn)=f(x1,x2,…,xn∣θ) L(\theta \mid x_1, x_2, \dots, x_n) = f(x_1, x_2, \dots, x_n \mid \theta) L(θ∣x1,x2,…,xn)=f(x1,x2,…,xn∣θ)
其中:
- f(x1,x2,…,xn∣θ)f(x_1, x_2, \dots, x_n \mid \theta)f(x1,x2,…,xn∣θ) 是随机变量 X1,X2,…,XnX_1, X_2, \dots, X_nX1,X2,…,Xn 的联合概率密度函数 (PDF) 或联合概率质量函数 (PMF),取决于分布是连续型还是离散型。
- 竖线 “|” 表示条件:左侧是似然函数(参数 θ 给定数据),右侧是联合分布(数据给定参数 θ)。
为什么这样写?因为似然函数本质上就是将观测数据视为固定值,而将参数 θ 视为变量的联合概率函数。它“借用”了概率分布的形式,但颠倒了视角:
-
在概率中,我们固定 θ,计算数据出现的概率:P(data∣θ)P(\text{data} \mid \theta)P(data∣θ)。
-
在似然中,我们固定数据,评估不同 θ 的“合理性”:
L(θ∣data)=P(data∣θ) L(\theta \mid \text{data}) = P(\text{data} \mid \theta) L(θ∣data)=P(data∣θ)
这不是巧合,而是定义使然:似然函数直接等于给定 θ 时数据的联合概率(密度),因为它衡量了“数据在该 θ 下有多‘似然’(likely)出现”。
为什么不写成其他形式?
- 不能写成 L(x∣θ)L(\mathbf{x} \mid \theta)L(x∣θ),因为这还是概率视角(数据变,θ 固定),而似然强调 θ 变,数据固定。
- 似然不是概率分布(即:∫L(θ)dθ≠1\int L(\theta) d\theta \neq 1∫L(θ)dθ=1),它只是一个相对度量,用于比较不同 θ。
- 这个写法突显了贝叶斯与频率学派的区别:在贝叶斯中,似然是后验的一部分:p(θ∣x)∝L(θ∣x)⋅p(θ)p(\theta \mid \mathbf{x}) \propto L(\theta \mid \mathbf{x}) \cdot p(\theta)p(θ∣x)∝L(θ∣x)⋅p(θ) ,但 MLE 是纯频率方法,只用似然最大化。
[!NOTE]
注意对数似然函数仅依赖 xnx_nxn 的 NNN 个观测值的和 ∑n=1Nxn\sum_{n=1}^N x_n∑n=1Nxn 。该值给出了数据在这一分布下的充分统计量(sufficient statistic)
直观理解
假设你有一组数据,想要估计某个未知参数。充分统计量的意思是:如果你知道了这个统计量的值,那么原始数据中就没有额外的信息能帮助你更好地估计这个参数了。换句话说,这个统计量已经“充分”概括了数据中关于参数的所有相关信息。
正式定义
设 X1,X2,…,XnX_1, X_2, \dots, X_nX1,X2,…,Xn 是来自分布 f(x∣θ)f(x|\theta)f(x∣θ) 的随机样本,其中 θ\thetaθ 是未知参数。统计量 T(X1,X2,…,Xn)T(X_1, X_2, \dots, X_n)T(X1,X2,…,Xn) 是关于参数 θ\thetaθ 的充分统计量,当且仅当在给定 TTT 的值后,样本的条件分布不依赖于 θ\thetaθ。
数学表达式为:
P(X1,X2,…,Xn∣T=t,θ)=P(X1,X2,…,Xn∣T=t) P(X_1, X_2, \dots, X_n \mid T = t, \theta) = P(X_1, X_2, \dots, X_n \mid T = t) P(X1,X2,…,Xn∣T=t,θ)=P(X1,X2,…,Xn∣T=t)
因子分解定理(Factorization Theorem)
判断充分统计量的一个实用方法是因子分解定理:
统计量 T(X)T(X)T(X) 是充分统计量,当且仅当样本的联合概率密度函数可以分解为:
f(x1,x2,…,xn∣θ)=g(T(x1,x2,…,xn),θ)⋅h(x1,x2,…,xn) f(x_1, x_2, \dots, x_n \mid \theta) = g(T(x_1, x_2, \dots, x_n), \theta) \cdot h(x_1, x_2, \dots, x_n) f(x1,x2,…,xn∣θ)=g(T(x1,x2,…,xn),θ)⋅h(x1,x2,…,xn)
其中 ggg 依赖于 θ\thetaθ 和 TTT,而 hhh 不依赖于 θ\thetaθ。
因子分解定理的核心思想
一个统计量 T(X)T(X)T(X) 是关于参数 θ\thetaθ 的充分统计量,如果在知道 T(X)T(X)T(X) 的情况下,原始样本数据中不再包含额外的关于 θ\thetaθ 的信息。
因子分解定理提供了一个“检查充分性”的实用方法:
只要能把联合概率分布写成依赖于 T(X)T(X)T(X) 与 θ\thetaθ 的部分,以及完全不依赖 θ\thetaθ 的部分,就能判定 T(X)T(X)T(X) 是充分统计量。
为什么要分解?
样本的联合分布函数为:
f(x1,x2,…,xn∣θ) f(x_1, x_2, \dots, x_n \mid \theta) f(x1,x2,…,xn∣θ)
这是数据与参数的完整关系。因子分解定理告诉我们,可以把它写成两部分:
-
g(T(x),θ)g(T(x), \theta)g(T(x),θ):信息部分
- 只依赖于 θ\thetaθ 和统计量 T(x)T(x)T(x)。
- 说明所有关于 θ\thetaθ 的信息都集中在 T(x)T(x)T(x) 中,数据再多也只是通过 T(x)T(x)T(x) 来影响参数。
-
h(x)h(x)h(x):无关部分
- 与 θ\thetaθ 无关,只依赖于原始数据 xxx。
- 这部分不能提供关于 θ\thetaθ 的信息,所以对参数推断没有用。
因此,一旦分解成立,T(X)T(X)T(X) 就是充分统计量。
一个经典例子:泊松分布
设 X1,X2,…,Xn∼i.i.d.Poisson(λ)X_1, X_2, \dots, X_n \overset{\text{i.i.d.}}{\sim} \text{Poisson}(\lambda)X1,X2,…,Xn∼i.i.d.Poisson(λ)。
单个样本的 pmf 为:
f(xi∣λ)=λxie−λxi!,xi=0,1,2,… f(x_i \mid \lambda) = \frac{\lambda^{x_i} e^{-\lambda}}{x_i!}, \quad x_i = 0, 1, 2, \dots f(xi∣λ)=xi!λxie−λ,xi=0,1,2,…
联合分布为:
f(x1,…,xn∣λ)=∏i=1nλxie−λxi!=λ∑i=1nxie−nλ⋅1∏i=1nxi! f(x_1, \dots, x_n \mid \lambda) = \prod_{i=1}^n \frac{\lambda^{x_i} e^{-\lambda}}{x_i!} = \lambda^{\sum_{i=1}^n x_i} e^{-n \lambda} \cdot \frac{1}{\prod_{i=1}^n x_i!} f(x1,…,xn∣λ)=i=1∏nxi!λxie−λ=λ∑i=1nxie−nλ⋅∏i=1nxi!1
现在看结构:
- g(T(x),λ)=λ∑x_ie−nλg(T(x), \lambda) = \lambda^{\sum x\_i} e^{-n\lambda}g(T(x),λ)=λ∑x_ie−nλ (依赖 λ\lambdaλ 和 T(x)=∑xiT(x)=\sum x_iT(x)=∑xi)
- h(x)=1∏xi!h(x) = \frac{1}{\prod x_i!}h(x)=∏xi!1 (只依赖数据,不依赖 λ\lambdaλ)
由因子分解定理可知,T(X)=∑i=1nXiT(X) = \sum_{i=1}^n X_iT(X)=∑i=1nXi 是 λ\lambdaλ 的充分统计量。
直观理解
- 如果我们知道了 ∑Xi\sum X_i∑Xi,就已经包含了所有和 λ\lambdaλ 有关的信息;
- 剩下的细节(比如每个 XiX_iXi 的排列方式)只影响 h(x)h(x)h(x),但它和 λ\lambdaλ 无关;
- 所以对于参数估计来说,∑Xi\sum X_i∑Xi 已经足够,原始数据再详细也没用。
总结
因子分解定理的意义:
- 提供了一个判断“充分性”的操作性工具。
- 本质上说明了:一个统计量是充分的,当它能捕获所有与参数相关的信息,剩余数据部分与参数无关。
重要性质
- 数据压缩:充分统计量实现了无损的数据压缩,用更简单的形式保留了所有关于参数的信息。
- 最小充分统计量:在所有充分统计量中,维数最小的称为最小充分统计量。
- 与估计的关系:任何好的参数估计量都应该是充分统计量的函数(Rao-Blackwell 定理)。
[!NOTE]
对于单个实数变量,能够使它的熵最大 化的分布就是高斯分布。这一性质对于多元高斯分布同样适用.当 我 们 考 虑 多 个 随 机 变 量 之 和 的 时 候, 同 样 会 用 到 高 斯 分 布
为什么必须是高斯分布(最大熵原理)
数学证明的核心思路
变分法与拉格朗日乘数法
我们要解决的是一个约束优化问题:
目标:最大化微分熵
H=−∫p(x)logp(x) dx H = -\int p(x) \log p(x) \, dx H=−∫p(x)logp(x)dx
约束条件:
-
归一化约束:
∫p(x) dx=1 \int p(x) \, dx = 1 ∫p(x)dx=1
-
均值约束:
∫x p(x) dx=μ \int x \, p(x) \, dx = \mu ∫xp(x)dx=μ
-
方差约束:
∫(x−μ)2p(x) dx=σ2 \int (x-\mu)^2 p(x) \, dx = \sigma^2 ∫(x−μ)2p(x)dx=σ2
构造拉格朗日函数:
L=−∫p(x)logp(x) dx−lambda1(∫p(x) dx−1)−λ2(∫xp(x) dx−μ)−λ3(∫(x−μ)2p(x) dx−σ2)\mathcal{L} = -\int p(x) \log p(x)\, dx - lambda_1 \left( \int p(x)\, dx - 1 \right) - \lambda_2 \left( \int x p(x)\, dx - \mu \right) - \lambda_3 \left( \int (x-\mu)^2 p(x)\, dx - \sigma^2 \right) L=−∫p(x)logp(x)dx−lambda1(∫p(x)dx−1)−λ2(∫xp(x)dx−μ)−λ3(∫(x−μ)2p(x)dx−σ2)
对 p(x)p(x)p(x) 做变分并令其为零:
δLδp=−logp(x)−1−λ1−λ2x−λ3(x−μ)2=0 \frac{\delta \mathcal{L}}{\delta p} = -\log p(x) - 1 - \lambda_1 - \lambda_2 x - \lambda_3 (x-\mu)^2 = 0 δpδL=−logp(x)−1−λ1−λ2x−λ3(x−μ)2=0
解得:
p(x)=exp(−1−λ1−λ2x−λ3(x−μ)2) p(x) = \exp \left( -1 - \lambda_1 - \lambda_2 x - \lambda_3 (x-\mu)^2 \right) p(x)=exp(−1−λ1−λ2x−λ3(x−μ)2)
通过约束条件解出拉格朗日乘数,最终得到:
p(x)=12πσ2exp (−(x−μ)22σ2) p(x) = \frac{1}{\sqrt{2\pi \sigma^2}} \exp \!\left(-\frac{(x-\mu)^2}{2\sigma^2}\right) p(x)=2πσ21exp(−2σ2(x−μ)2)
这正是高斯分布。
为什么不是其他分布?
-
数学唯一性
变分法给出的解是唯一的,在约束条件下满足最大熵的概率分布形式只能是高斯。 -
指数族一般结论
- 给定矩约束时,最大熵分布必定属于指数族
- 约束前两个矩(均值与方差) ⇒ 高斯分布
- 其他矩约束则对应其他分布(如拉普拉斯分布、指数分布等)
-
常见反例的限制
- 均匀分布:只能在有界区间上定义,不能满足实数轴上方差有限的条件
- 指数分布:只有一个参数,不能同时满足均值和方差两个独立约束
- 拉普拉斯分布:最大熵条件对应 L1L^1L1 约束(绝对偏差),而不是方差
- t 分布:重尾,方差可能不存在,不满足有限方差约束
多元情况推广
对于多元情况,约束为:
-
均值:
E[X]=μ \mathbb{E}[X] = \mu E[X]=μ
-
协方差矩阵:
Cov[X]=Σ \text{Cov}[X] = \Sigma Cov[X]=Σ
同样的变分过程得到:
p(x)∝exp (−12(x−μ)⊤Σ−1(x−μ)) p(x) \propto \exp \!\left(-\tfrac{1}{2} (x-\mu)^\top \Sigma^{-1} (x-\mu)\right) p(x)∝exp(−21(x−μ)⊤Σ−1(x−μ))
即 多元高斯分布。
高斯分布是最大熵分布,这不是偶然,而是数学必然:
- 在均值与方差已知的条件下,只有高斯分布能实现最大熵。
- 这也解释了:
中心极限定理的信息论解释:
- 多个独立信息源的叠加自然趋向于高斯分布
- 这不是偶然,而是熵最大化的必然结果
- 自然界"选择"了信息熵最大的状态
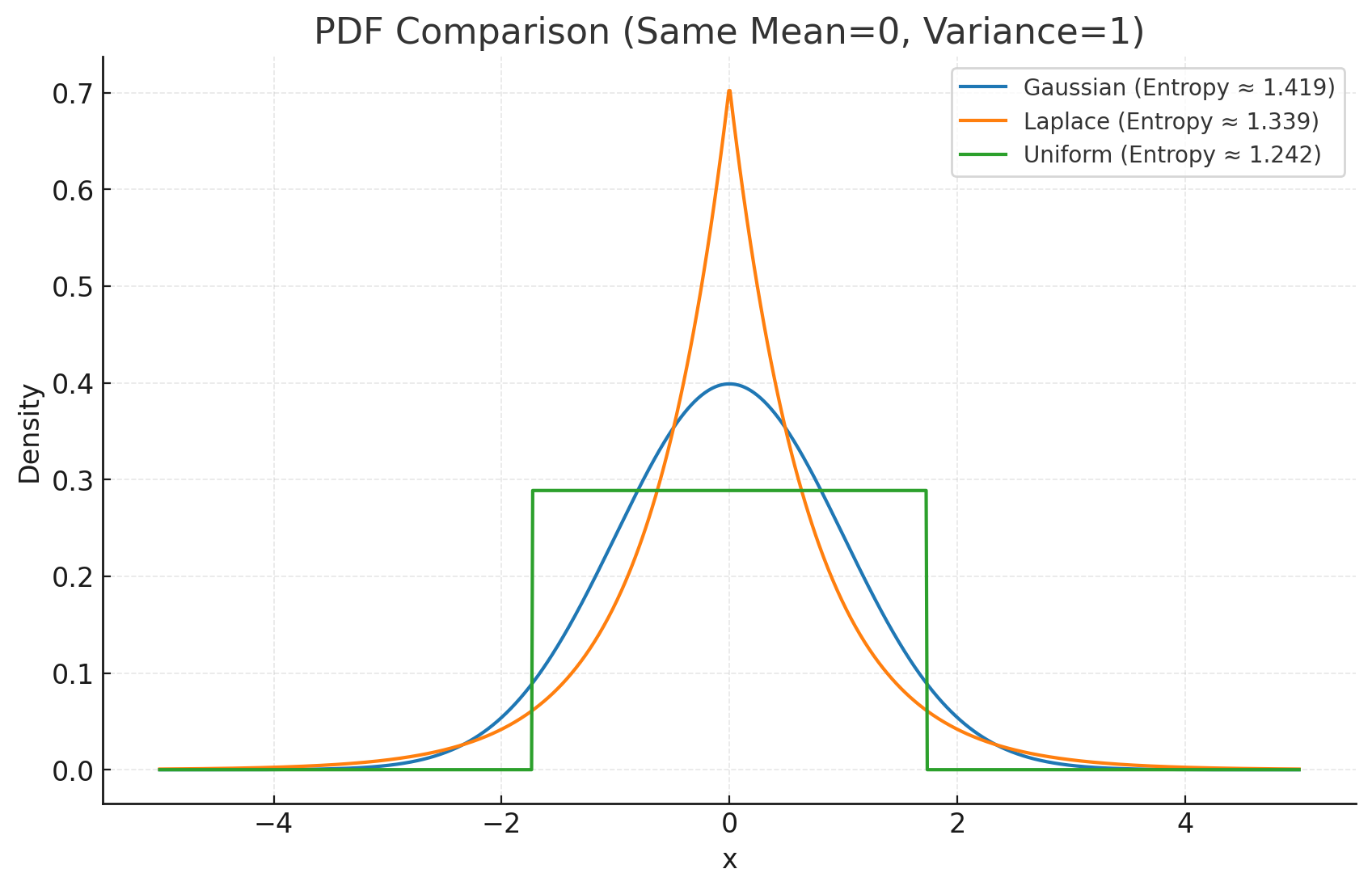
这张图展示了 高斯分布、拉普拉斯分布、均匀分布 在相同均值(0)和方差(1)下的概率密度函数 (PDF),并标注了对应的熵值:
- 高斯分布 (Gaussian):熵最大
- 拉普拉斯分布 (Laplace):熵较小,因为分布在中心更尖锐,两侧更厚尾
- 均匀分布 (Uniform):熵比拉普拉斯大,但仍小于高斯,因为尾部突然截断
👉 直观结论:在给定均值和方差约束下,高斯分布的熵始终最大,因此是“最不确定”、信息量最丰富的分布。
[!NOTE]
Δ2=(x−μ)TΣ−1(x−μ)\Delta^2=(x-\mu)^{\mathrm{T}} \Sigma^{-1}(x-\mu)Δ2=(x−μ)TΣ−1(x−μ)
其中,量 Δ\DeltaΔ 称为 μ\boldsymbol{\mu}μ 到 x\boldsymbol{x}x 的马哈拉诺比斯距离(Mahalanobis distance)。当 Σ\boldsymbol{\Sigma}Σ 为单位矩阵时,它退化为欧氏距离。高斯分布在 x\boldsymbol{x}x 空间的曲面上是常数,因为该二次型为常数。
首先,注意可以不失一般性地假设矩阵 Σ\boldsymbol{\Sigma}Σ 为对称矩阵,因为任何非对称的成分都会从指数中消失(见习题3.11)。考虑协方差矩阵的特征方程:
Σui=λiui\boldsymbol{\Sigma} \boldsymbol{u}_i=\lambda_i \boldsymbol{u}_iΣui=λiui
高斯分布的几何形式
一维高斯分布的几何形状
一维高斯分布 N(μ,σ2)N(\mu, \sigma^2)N(μ,σ2) 的概率密度函数为:
p(x)=12πσ2exp (−(x−μ)22σ2) p(x) = \frac{1}{\sqrt{2\pi\sigma^2}} \exp \!\left( -\frac{(x-\mu)^2}{2\sigma^2} \right) p(x)=2πσ21exp(−2σ2(x−μ)2)
几何特征:
-
钟形曲线:关于均值 μ\muμ 对称
-
拐点:在 x=μ±σx = \mu \pm \sigmax=μ±σ 处有拐点
-
68-95-99.7 规则:
- 约 68% 的数据在 μ±σ\mu \pm \sigmaμ±σ 内
- 约 95% 的数据在 μ±2σ\mu \pm 2\sigmaμ±2σ 内
- 约 99.7% 的数据在 μ±3σ\mu \pm 3\sigmaμ±3σ 内
多元高斯分布的几何形状
多元高斯分布的概率密度函数为:
p(x)=1(2π)n/2∣Σ∣1/2exp (−12(x−μ)⊤Σ−1(x−μ)) p(x) = \frac{1}{(2\pi)^{n/2} |\Sigma|^{1/2}} \exp \!\left( -\tfrac{1}{2} (x-\mu)^\top \Sigma^{-1} (x-\mu) \right) p(x)=(2π)n/2∣Σ∣1/21exp(−21(x−μ)⊤Σ−1(x−μ))
等概率密度面
指数项中的二次型:
Δ2=(x−μ)TΣ−1(x−μ)\Delta^2=(x-\mu)^{\mathrm{T}} \Sigma^{-1}(x-\mu)Δ2=(x−μ)TΣ−1(x−μ)
定义了等概率密度面。
二维情况(n=2):椭圆
(x1−μ1)2σ12+(x2−μ2)2σ22+交叉项=c\frac{(x_1-\mu_1)^2}{\sigma_1^2} + \frac{(x_2-\mu_2)^2}{\sigma_2^2} + \text{交叉项} = cσ12(x1−μ1)2+σ22(x2−μ2)2+交叉项=c
三维情况(n=3):椭球面
(x1−μ1)2σ12+(x2−μ2)2σ22+(x3−μ3)2σ32+交叉项=c\frac{(x_1-\mu_1)^2}{\sigma_1^2} + \frac{(x_2-\mu_2)^2}{\sigma_2^2} + \frac{(x_3-\mu_3)^2}{\sigma_3^2} + \text{交叉项} = cσ12(x1−μ1)2+σ22(x2−μ2)2+σ32(x3−μ3)2+交叉项=c
高维情况:超椭球面
核心思想:
- 高斯分布的概率密度完全由马哈拉诺比斯距离的平方 Δ2\Delta^2Δ2 决定
- 相同 Δ2\Delta^2Δ2 值的所有点具有相同的概率密度
- 这些点构成了椭球面族,这就是等概率密度曲面
-
二维情况:
- 当 Σ=σ2I\Sigma = \sigma^2 IΣ=σ2I 时:等概率线是同心圆
- 当 Σ\SigmaΣ 为对角矩阵时:等概率线是椭圆,且轴与坐标轴平行
- 当 Σ\SigmaΣ 是一般矩阵时:等概率线是旋转的椭圆
-
三维情况:
等概率密度面是椭球面,其形状与方向由协方差矩阵 Σ\SigmaΣ 决定。
协方差矩阵的几何意义
协方差矩阵的特征值分解:Σ=QΛQ⊤\Sigma = Q \Lambda Q^\topΣ=QΛQ⊤
- 特征向量 QQQ:决定椭圆/椭球的主轴方向
- 特征值 Λ\LambdaΛ:决定各主轴的伸展程度
- 第 iii 个特征值 λi\lambda_iλi 对应第 iii 个主轴的方差
几何变换视角
多元高斯分布可以视为标准正态分布 N(0,I)N(0, I)N(0,I) 经过以下变换:
- 平移:x→x+μx \to x + \mux→x+μ(改变中心)
- 线性变换:x→Axx \to A xx→Ax,其中 AA⊤=ΣAA^\top = \SigmaAA⊤=Σ(改变形状和方向)
实际意义
这种几何形式使得多元高斯分布:
- 直观可视化:椭圆/椭球直观展示数据分布
- 参数解释:协方差矩阵直接对应几何形状
- 计算便利:许多推导和计算可转化为几何问题
- 应用广泛:如聚类分析、PCA、卡尔曼滤波等都依赖这种几何理解
马哈拉诺比斯距离的含义
基本定义
Δ2=(x−μ)TΣ−1(x−μ)\Delta^2=(x-\mu)^{\mathrm{T}} \Sigma^{-1}(x-\mu)Δ2=(x−μ)TΣ−1(x−μ)
这个距离衡量的是点 x 到分布中心 μ 的"标准化"距离:
几何直觉:
- 不是简单的欧氏距离,而是考虑了数据分布形状的距离
- 在数据变化大的方向上,相同的物理距离对应更小的马哈拉诺比斯距离
- 在数据变化小的方向上,相同的物理距离对应更大的马哈拉诺比斯距离
与欧氏距离的关系
当 Σ = I(单位矩阵)时:
Δ2=(x−μ)T(x−μ)=∥x−μ∥2\Delta^2 = (x-\mu)^{\mathrm{T}}(x-\mu) = \|x-\mu\|^2Δ2=(x−μ)T(x−μ)=∥x−μ∥2
这正是欧氏距离的平方!
一般情况下:
马哈拉诺比斯距离 = 在"拉直"数据后的欧氏距离
等概率密度曲面
为什么是常数曲面?
多元高斯分布的概率密度函数:
p(x)∝exp(−12Δ2)p(x) \propto \exp\left(-\frac{1}{2}\Delta^2\right)p(x)∝exp(−21Δ2)
关键观察:
- 当 Δ2=c\Delta^2 = cΔ2=c(常数)时,p(x)=常数p(x) = \text{常数}p(x)=常数
- 因此等概率密度面就是 Δ2=c\Delta^2 = cΔ2=c 的曲面
- 这些曲面是同心的椭球面
几何形状
- 二维:椭圆族
- 三维:椭球面族
- 高维:超椭球面族
协方差矩阵的特征分解
特征方程
Σui=λiui\Sigma u_i = \lambda_i u_iΣui=λiui
这告诉我们:
- 特征向量 uiu_iui:椭球的主轴方向
- 特征值 λi\lambda_iλi:对应主轴方向的方差大小
几何解释
坐标变换视角:
设 Σ=UΛUT\Sigma = U\Lambda U^TΣ=UΛUT,其中:
- U=[u1,u2,...,un]U = [u_1, u_2, ..., u_n]U=[u1,u2,...,un]:特征向量矩阵
- Λ=diag(λ1,λ2,...,λn)\Lambda = \text{diag}(\lambda_1, \lambda_2, ..., \lambda_n)Λ=diag(λ1,λ2,...,λn):特征值对角矩阵
新坐标系:
令 y=UT(x−μ)y = U^T(x-\mu)y=UT(x−μ),则:
Δ2=yTΛ−1y=∑i=1nyi2λi\Delta^2 = y^T\Lambda^{-1}y = \sum_{i=1}^n \frac{y_i^2}{\lambda_i}Δ2=yTΛ−1y=i=1∑nλiyi2
这是标准椭球方程!
具体例子
二维情况
假设:
Σ=[4222]\Sigma = \begin{bmatrix} 4 & 2 \\ 2 & 2 \end{bmatrix}Σ=[4222]
特征值分解:
- λ1=5.236\lambda_1 = 5.236λ1=5.236,u1=[0.8510.526]u_1 = \begin{bmatrix} 0.851 \\ 0.526 \end{bmatrix}u1=[0.8510.526]
- λ2=0.764\lambda_2 = 0.764λ2=0.764,u2=[−0.5260.851]u_2 = \begin{bmatrix} -0.526 \\ 0.851 \end{bmatrix}u2=[−0.5260.851]
几何意义:
- 椭圆的长轴方向:u1u_1u1,半轴长度:λ1=2.29\sqrt{\lambda_1} = 2.29λ1=2.29
- 椭圆的短轴方向:u2u_2u2,半轴长度:λ2=0.87\sqrt{\lambda_2} = 0.87λ2=0.87
- 椭圆相对于坐标轴旋转了约 32°32°32°
为什么协方差矩阵可以假设为对称?
数学原因
对于任意矩阵 AAA,在二次型 xTAxx^TAxxTAx 中:
xTAx=xT(A+AT2)xx^TAx = x^T\left(\frac{A + A^T}{2}\right)xxTAx=xT(2A+AT)x
关键点:
- 只有对称部分 A+AT2\frac{A + A^T}{2}2A+AT 影响二次型的值
- 非对称部分 A−AT2\frac{A - A^T}{2}2A−AT 对二次型没有贡献
为什么非对称成分会"消失".
任意矩阵的对称分解
对于任意方阵 AAA,都可以唯一分解为:
A=A+AT2+A−AT2=Asym+AskewA = \frac{A + A^T}{2} + \frac{A - A^T}{2} = A_{\text{sym}} + A_{\text{skew}}A=2A+AT+2A−AT=Asym+Askew
其中:
- Asym=A+AT2A_{\text{sym}} = \frac{A + A^T}{2}Asym=2A+AT 是对称部分
- Askew=A−AT2A_{\text{skew}} = \frac{A - A^T}{2}Askew=2A−AT 是反对称部分
二次型中反对称部分的贡献
对于任意向量 v=x−μv = x - \muv=x−μ,计算二次型:
vTAv=vT(Asym+Askew)v=vTAsymv+vTAskewvv^T A v = v^T (A_{\text{sym}} + A_{\text{skew}}) v = v^T A_{\text{sym}} v + v^T A_{\text{skew}} vvTAv=vT(Asym+Askew)v=vTAsymv+vTAskewv
关键计算:
vTAskewv=vT(A−AT2)vv^T A_{\text{skew}} v = v^T \left(\frac{A - A^T}{2}\right) vvTAskewv=vT(2A−AT)v
=12(vTAv−vTATv)= \frac{1}{2}(v^T A v - v^T A^T v)=21(vTAv−vTATv)
=12(vTAv−(vTATv)T)= \frac{1}{2}(v^T A v - (v^T A^T v)^T)=21(vTAv−(vTATv)T)
=12(vTAv−vTAv)=0= \frac{1}{2}(v^T A v - v^T A v) = 0=21(vTAv−vTAv)=0
结论:反对称矩阵的二次型恒等于零!
物理直觉
协方差矩阵 Σij=Cov(Xi,Xj)\Sigma_{ij} = \text{Cov}(X_i, X_j)Σij=Cov(Xi,Xj) 天然满足对称矩阵:
Σij=Cov(Xi,Xj)=Cov(Xj,Xi)=Σji\Sigma_{ij} = \text{Cov}(X_i, X_j) = \text{Cov}(X_j, X_i) = \Sigma_{ji}Σij=Cov(Xi,Xj)=Cov(Xj,Xi)=Σji
二次型理论
这个结果是二次型理论的基本结果:
- 二次型 xTAxx^T A xxTAx 完全由 AAA 的对称部分决定
- 反对称部分对二次型没有任何影响
- 这在优化理论、微分几何等领域都有重要应用
线性代数视角
在线性代数中:
- 对称矩阵:可以表示椭球、抛物面等二次曲面
- 反对称矩阵:表示旋转、剪切等保距变换
- 在二次型中,只有"形状"信息(对称部分)重要,"旋转"信息(反对称部分)被忽略
考虑协方差矩阵:
Σ=[4334]\Sigma = \begin{bmatrix} 4 & 3 \\ 3 & 4 \end{bmatrix}Σ=[4334]
数据的"椭圆云":
- 数据点不是随机散布的
- 而是形成一个椭圆形的云团
- 椭圆有长轴和短轴方向
主轴方向的具体含义
第一主轴(长轴)
- 方向:数据变化最大的方向
- 特点:沿这个方向,数据点分散得最开
- 对应:最大特征值 λ1\lambda_1λ1 的特征向量 u1u_1u1
第二主轴(短轴)
- 方向:数据变化次大的方向(与第一主轴垂直)
- 特点:沿这个方向,数据点相对聚集
- 对应:第二大特征值 λ2\lambda_2λ2 的特征向量 u2u_2u2
高维情况
在 nnn 维空间中有 nnn 个主轴方向:
- u1u_1u1:第1主轴(方差最大)
- u2u_2u2:第2主轴(方差次大)
- …
- unu_nun:第n主轴(方差最小)
为什么会有这些方向?
变量间的相关性
根本原因:变量之间的相关关系产生了方向性
举例:
身高 vs 体重数据:
- 两者正相关 → 数据沿对角线方向延伸
- 如果完全无关 → 数据呈圆形分布,无明显方向
[!NOTES]
讲一讲核密度和K近邻 来估计密度函数
好的,我由浅入深地讲解这个基本原理,以及它如何成为核密度估计和K近邻密度估计的理论基础。
第一层:直觉理解
最简单的类比
想象你在一个黑暗的房间里,想知道某个位置的人群密度有多高:
方法1: 在那个位置画一个圆圈,数数圈内有多少人
方法2: 站在那个位置,看看最近的10个人距离你有多远
这就是密度估计的两种基本思路!
核心直觉
密度高的地方 = 附近样本点多的地方
第二层:数学化这个直觉
基本设定
- 有N个数据点:x1,x2,...,xNx_1, x_2, ..., x_Nx1,x2,...,xN
- 想知道某个位置x处的密度p(x)p(x)p(x)有多大
关键洞察
如果我们在点x周围画一个小区域R\mathcal{R}R:
区域内的概率=∫Rp(x)dx\text{区域内的概率} = \int_{\mathcal{R}} p(x)dx区域内的概率=∫Rp(x)dx
这是什么意思?
- 就像掷飞镖,这个积分告诉我们"飞镖落在这个区域内的概率是多少"
- 如果这个区域密度很高,概率就大;密度低,概率就小
第三层:从概率到计数
核心转换
现在关键来了!我们有N个实际的数据点,这些点落在区域R\mathcal{R}R内的期望个数是:
E[区域内点的个数]=N×P\mathbb{E}[\text{区域内点的个数}] = N \times PE[区域内点的个数]=N×P
其中P=∫Rp(x)dxP = \int_{\mathcal{R}} p(x)dxP=∫Rp(x)dx
为什么?
- 每个点落入区域的概率是P
- 有N个独立的点
- 所以期望总数 = N × P
这就像扔N次硬币,每次正面概率是P,期望正面次数就是NP。
第四层:反推密度
关键反推
如果实际观察到区域内有K个点,那么:
K≈NPK \approx NPK≈NP
所以:
P≈KNP \approx \frac{K}{N}P≈NK
最终密度估计
如果区域很小,密度在区域内近似常数:
P=∫Rp(x)dx≈p(x)×VP = \int_{\mathcal{R}} p(x)dx \approx p(x) \times VP=∫Rp(x)dx≈p(x)×V
其中V是区域体积。
因此:
p(x)≈PV≈KNVp(x) \approx \frac{P}{V} \approx \frac{K}{NV}p(x)≈VP≈NVK
这就是密度估计的万能公式!
第五层:两种不同的实现策略
现在我们有了公式p(x)≈KNVp(x) \approx \frac{K}{NV}p(x)≈NVK,但K和V怎么确定呢?
策略1:固定V,数K(核密度估计的思路)
- 做法: 固定一个区域大小V(比如半径为h的圆)
- 数K: 统计这个固定区域内有多少个样本点
- 问题: 在样本稀少的地方,K可能为0,估计很不稳定
策略2:固定K,算V(K近邻的思路)
- 做法: 固定要找的近邻个数K(比如最近的5个点)
- 算V: 计算包含这K个点需要多大的区域
- 优势: 保证了统计的稳定性,因为总是有K个点
第六层:具体算法实现
核密度估计的完整实现
不是简单的数点,而是加权平均:
p^(x)=1N∑i=1N1hK(x−xih)\hat{p}(x) = \frac{1}{N} \sum_{i=1}^{N} \frac{1}{h} K\left(\frac{x - x_i}{h}\right)p^(x)=N1i=1∑Nh1K(hx−xi)
为什么这样做?
- K(⋅)K(\cdot)K(⋅)是核函数,给不同距离的点不同权重
- 距离x近的点权重大,远的点权重小
- h控制"近"的定义(带宽)
K近邻的完整实现
p^(x)=kN⋅Vk(x)\hat{p}(x) = \frac{k}{N \cdot V_k(x)}p^(x)=N⋅Vk(x)k
其中Vk(x)V_k(x)Vk(x)是包含x的k个最近邻所需的区域体积。
第七层:为什么这个基础理论如此重要?
统一的理论框架
这个p(x)≈KNVp(x) \approx \frac{K}{NV}p(x)≈NVK公式揭示了:
- 所有密度估计方法的本质:都是在平衡K和V
- 偏差-方差权衡:
- V太小(或K太小)→ 方差大,估计不稳定
- V太大(或K太大)→ 偏差大,过度平滑
- 维数灾难的根源:高维空间中,要么V很大,要么K很小
算法设计的指导
- 核密度估计:通过选择合适的核函数和带宽来平衡
- K近邻:通过选择合适的K值来平衡
基于这个图片内容,我来详细讲解核密度估计技术的具体实现过程和关键概念。
核密度估计的构建过程
第一步:定义基础区域和核函数
超小立方体的定义:
对于希望确定概率密度的点x,将区域R\mathcal{R}R取为以点x为中心的超小立方体。
Parzen窗核函数:
k(u)={1,∣ui∣≤1/2, i=1,⋯ ,D0,其他k(\mathbf{u}) = \begin{cases}
1, & |\mathbf{u}_i| \leq 1/2, \; i=1,\cdots,D \\
0, & \text{其他}
\end{cases}k(u)={1,0,∣ui∣≤1/2,i=1,⋯,D其他
核函数的几何意义:
- 这是一个以原点为中心的单位立方体
- 在立方体内函数值为1,外部为0
- 这种核函数称为Parzen窗(Parzen window)
第二步:计算区域内的点数
点数统计公式:
K=∑n=1Nk(x−xnh)(1)K = \sum_{n=1}^{N} k\left(\frac{\mathbf{x} - \mathbf{x}_n}{h}\right) \quad (1)K=n=1∑Nk(hx−xn)(1)
公式解释:
- 如果数据点xn\mathbf{x}_nxn位于以点x为中心、边长为h的立方体内
- 那么k((x−xn)/h)k((\mathbf{x}-\mathbf{x}_n)/h)k((x−xn)/h)将为1,否则为0
- K就是该立方体内数据点的总数
第三步:密度估计公式
最终密度估计:
p(x)=1N∑n=1N1hDk(x−xnh)(3.183)p(\mathbf{x}) = \frac{1}{N} \sum_{n=1}^{N} \frac{1}{h^D} k\left(\frac{\mathbf{x} - \mathbf{x}_n}{h}\right) \quad (3.183)p(x)=N1n=1∑NhD1k(hx−xn)(3.183)
公式推导:
- 将式(1)代入基本公式p(x)=KNVp(\mathbf{x}) = \frac{K}{NV}p(x)=NVK
- D维空间中边长为h的超立方体体积:V=hDV = h^DV=hD
- 因此得到最终的密度估计公式
关键概念解析
1. 体积计算
D维超立方体体积公式:
V=hDV = h^DV=hD
这解释了为什么公式中有1hD\frac{1}{h^D}hD1项。
2. 核函数的对称性
重新解释估计过程:
利用核函数k(u)k(\mathbf{u})k(u)的对称性,我们可以不再将其视为以点x为中心的单个立方体,而是视为以N个数据点xn\mathbf{x}_nxn为中心的N个立方体的总和。
新的理解角度:
- 在每个数据点xn\mathbf{x}_nxn处放置一个边长为h的立方体
- 每个立方体对密度的贡献是1NhD\frac{1}{Nh^D}NhD1
- 点x处的总密度是所有包含x的立方体贡献的总和
从Parzen窗到一般核密度估计
Parzen窗的局限性
- 硬边界: 立方体边界处的突然截断
- 不可微: 在边界处不可导
- 视觉效果差: 产生块状的密度估计
改进方向
更平滑的核函数选择:
高斯核:
k(u)=1(2π)D/2exp(−∣u∣22)k(\mathbf{u}) = \frac{1}{(2\pi)^{D/2}} \exp\left(-\frac{|\mathbf{u}|^2}{2}\right)k(u)=(2π)D/21exp(−2∣u∣2)
Epanechnikov核:
k(u)={34(1−∣u∣2)if ∣u∣≤10otherwisek(\mathbf{u}) = \begin{cases}
\frac{3}{4}(1-|\mathbf{u}|^2) & \text{if } |\mathbf{u}| \leq 1 \\
0 & \text{otherwise}
\end{cases}k(u)={43(1−∣u∣2)0if ∣u∣≤1otherwise
核密度估计的一般形式
通用公式
p^(x)=1N∑n=1N1hDK(x−xnh)\hat{p}(\mathbf{x}) = \frac{1}{N} \sum_{n=1}^{N} \frac{1}{h^D} K\left(\frac{\mathbf{x} - \mathbf{x}_n}{h}\right)p^(x)=N1n=1∑NhD1K(hx−xn)
其中K(⋅)K(\cdot)K(⋅)是任意满足∫K(u)du=1\int K(\mathbf{u})d\mathbf{u} = 1∫K(u)du=1的核函数。
核函数的一般要求
- 归一化: ∫K(u)du=1\int K(\mathbf{u})d\mathbf{u} = 1∫K(u)du=1
- 对称性: K(u)=K(−u)K(\mathbf{u}) = K(-\mathbf{u})K(u)=K(−u)
- 非负性: K(u)≥0K(\mathbf{u}) \geq 0K(u)≥0
- 单峰性: 在原点达到最大值
实际应用考虑
带宽选择
- h太小: 过拟合,估计过于粗糙
- h太大: 欠拟合,过度平滑
- 自适应选择: 使用交叉验证或插值法则
K近邻密度估计的基本思想
核心理念
固定K,让V自适应
- 预先确定近邻数量K
- 让包含这K个近邻的区域体积V根据数据自动调整
- 密度高的地方V小,密度低的地方V大
构建过程详解
第一步:距离计算
计算查询点到所有样本点的距离
对于查询点x\mathbf{x}x和训练样本{x1,x2,...,xN}\{\mathbf{x}_1, \mathbf{x}_2, ..., \mathbf{x}_N\}{x1,x2,...,xN}:
di=∣∣x−xi∣∣d_i = ||\mathbf{x} - \mathbf{x}_i||di=∣∣x−xi∣∣
常用距离度量:
- 欧几里得距离: di=∑j=1D(xj−xi,j)2d_i = \sqrt{\sum_{j=1}^D (x_j - x_{i,j})^2}di=∑j=1D(xj−xi,j)2
- 曼哈顿距离: di=∑j=1D∣xj−xi,j∣d_i = \sum_{j=1}^D |x_j - x_{i,j}|di=∑j=1D∣xj−xi,j∣
- 闵可夫斯基距离: di=(∑j=1D∣xj−xi,j∣p)1/pd_i = \left(\sum_{j=1}^D |x_j - x_{i,j}|^p\right)^{1/p}di=(∑j=1D∣xj−xi,j∣p)1/p
第二步:找到K个最近邻
排序并选择前K个
- 将所有距离{d1,d2,...,dN}\{d_1, d_2, ..., d_N\}{d1,d2,...,dN}排序
- 选择前K个最小的距离:d(1)≤d(2)≤...≤d(K)d_{(1)} \leq d_{(2)} \leq ... \leq d_{(K)}d(1)≤d(2)≤...≤d(K)
- 记录对应的样本点:{x(1),x(2),...,x(K)}\{\mathbf{x}_{(1)}, \mathbf{x}_{(2)}, ..., \mathbf{x}_{(K)}\}{x(1),x(2),...,x(K)}
第三步:确定包含区域的体积
关键:第K个近邻的距离
设第K个最近邻的距离为rK(x)=d(K)r_K(\mathbf{x}) = d_{(K)}rK(x)=d(K)
不同维度的体积计算:
一维情况:
VK(x)=2rK(x)V_K(\mathbf{x}) = 2r_K(\mathbf{x})VK(x)=2rK(x)
二维情况(圆形区域):
VK(x)=πrK(x)2V_K(\mathbf{x}) = \pi r_K(\mathbf{x})^2VK(x)=πrK(x)2
三维情况(球形区域):
VK(x)=4π3rK(x)3V_K(\mathbf{x}) = \frac{4\pi}{3} r_K(\mathbf{x})^3VK(x)=34πrK(x)3
一般d维情况(超球体):
VK(x)=πd/2Γ(d/2+1)rK(x)dV_K(\mathbf{x}) = \frac{\pi^{d/2}}{\Gamma(d/2 + 1)} r_K(\mathbf{x})^dVK(x)=Γ(d/2+1)πd/2rK(x)d
其中Γ(⋅)\Gamma(\cdot)Γ(⋅)是伽马函数。
第四步:计算密度估计
应用基本公式:
p^(x)=KN⋅VK(x)\hat{p}(\mathbf{x}) = \frac{K}{N \cdot V_K(\mathbf{x})}p^(x)=N⋅VK(x)K
具体形式:
p^(x)=K⋅Γ(d/2+1)Nπd/2rK(x)d\hat{p}(\mathbf{x}) = \frac{K \cdot \Gamma(d/2 + 1)}{N \pi^{d/2} r_K(\mathbf{x})^d}p^(x)=Nπd/2rK(x)dK⋅Γ(d/2+1)
详细算法流程## 实际应用示例
一维示例
假设有数据点:[1, 2, 3, 5, 8, 10],K=3
查询点x=4的密度估计:
- 计算距离:[3, 2, 1, 1, 4, 6]
- 排序:[1, 1, 2, 3, 4, 6]
- 第3个近邻距离:r3=2r_3 = 2r3=2
- 一维体积:V3=2×2=4V_3 = 2 \times 2 = 4V3=2×2=4
- 密度估计:p^(4)=36×4=18\hat{p}(4) = \frac{3}{6 \times 4} = \frac{1}{8}p^(4)=6×43=81
二维示例
数据点在平面上分布,查询点x=[1, 1],K=5
- 计算所有点到[1,1]的欧几里得距离
- 找到第5近的点,距离为r5=2.5r_5 = 2.5r5=2.5
- 圆形区域体积:V5=π×2.52=6.25πV_5 = \pi \times 2.5^2 = 6.25\piV5=π×2.52=6.25π
- 密度估计:p^([1,1])=5N×6.25π\hat{p}([1,1]) = \frac{5}{N \times 6.25\pi}p^([1,1])=N×6.25π5
K近邻密度估计的特点
优势
- 自适应性强: 自动适应局部数据密度
- 无参数假设: 不需要假设特定的分布形式
- 理论基础: 有收敛性保证
- 简单直观: 算法逻辑清晰易懂
局限性
- 计算复杂度高: 每次查询需要计算大量距离
- 存储需求大: 需要保存所有训练数据
- 维度灾难: 高维空间中性能下降
- 不连续: 估计函数在某些点不连续
改进方法
1. 加权K近邻
给不同距离的近邻赋予不同权重:
p^(x)=∑i=1KwiN⋅VK(x)\hat{p}(\mathbf{x}) = \frac{\sum_{i=1}^K w_i}{N \cdot V_K(\mathbf{x})}p^(x)=N⋅VK(x)∑i=1Kwi
其中wiw_iwi是第i个近邻的权重,如wi=1/diw_i = 1/d_iwi=1/di
2. 自适应K值
根据局部数据密度自动调整K值:
- 密度高的区域使用较小的K
- 密度低的区域使用较大的K
3. 降维预处理
在高维数据上:
- 先进行降维(PCA、t-SNE等)
- 在低维空间进行K近邻密度估计
这种构建过程体现了K近邻方法的核心思想:让数据本身决定每个位置的适当邻域大小,从而实现自适应的密度估计。
K近邻技术从密度估计到分类的扩展
问题设定
- 数据集包含NkN_kNk个属于类别CkC_kCk的点
- 总共有N个点:∑kNk=N\sum_k N_k = N∑kNk=N
- 目标:对新点x\mathbf{x}x进行分类
K近邻分类的核心思想
在点x\mathbf{x}x周围绘制一个恰好包含K个点的球体,不考虑这些点的类别。设这个球体:
- 体积为V
- 包含来自类别CkC_kCk的KkK_kKk个点
关键公式的推导
1. 类条件密度估计
类别CkC_kCk的条件密度:
p(x∣Ck)=KkNkV(3.187)p(\mathbf{x}|C_k) = \frac{K_k}{N_k V} \quad (3.187)p(x∣Ck)=NkVKk(3.187)
公式解释:
- 分子KkK_kKk:球体内属于类别CkC_kCk的点数
- 分母NkN_kNk:数据集中类别CkC_kCk的总点数
- 分母V:球体体积
- 这给出了在类别CkC_kCk条件下,点x\mathbf{x}x的密度估计
2. 无条件密度估计
总体密度:
p(x)=KNV(3.188)p(\mathbf{x}) = \frac{K}{NV} \quad (3.188)p(x)=NVK(3.188)
公式解释:
- K:球体内的总点数(K=∑kKkK = \sum_k K_kK=∑kKk)
- N:数据集总点数
- 这是不考虑类别标签的整体密度估计
3. 类别先验概率
类别CkC_kCk的先验概率:
p(Ck)=NkN(3.189)p(C_k) = \frac{N_k}{N} \quad (3.189)p(Ck)=NNk(3.189)
公式解释:
- 这是数据集中类别CkC_kCk的相对频率
- 反映了类别CkC_kCk在整体数据中的比例
贝叶斯分类的完整框架
贝叶斯定理的应用
利用贝叶斯定理:
p(Ck∣x)=p(x∣Ck)p(Ck)p(x)p(C_k|\mathbf{x}) = \frac{p(\mathbf{x}|C_k)p(C_k)}{p(\mathbf{x})}p(Ck∣x)=p(x)p(x∣Ck)p(Ck)
代入K近邻估计
将公式(3.187)-(3.189)代入:
p(Ck∣x)=KkNkV⋅NkNKNVp(C_k|\mathbf{x}) = \frac{\frac{K_k}{N_k V} \cdot \frac{N_k}{N}}{\frac{K}{NV}}p(Ck∣x)=NVKNkVKk⋅NNk
简化结果
p(Ck∣x)=KkK(3.190)p(C_k|\mathbf{x}) = \frac{K_k}{K} \quad (3.190)p(Ck∣x)=KKk(3.190)
这个结果非常优美!
结果的深层含义
1. 简洁性
最终的后验概率只依赖于:
- KkK_kKk:K个近邻中属于类别CkC_kCk的个数
- K:总近邻数
所有其他因素(V、N、NkN_kNk)都约掉了!
2. 直觉解释
p(Ck∣x)=K个近邻中类别k的个数总近邻数Kp(C_k|\mathbf{x}) = \frac{\text{K个近邻中类别k的个数}}{\text{总近邻数K}}p(Ck∣x)=总近邻数KK个近邻中类别k的个数
这与我们的直觉完全一致:看看邻居们都是什么类别,按比例投票。
3. 分类决策
最大后验概率准则:
C^=argmaxkp(Ck∣x)=argmaxkKk\hat{C} = \arg\max_k p(C_k|\mathbf{x}) = \arg\max_k K_kC^=argkmaxp(Ck∣x)=argkmaxKk
即:选择在K个近邻中出现次数最多的类别。
K近邻分类的实际操作
算法步骤
- 计算距离: 计算新点x\mathbf{x}x到所有训练点的距离
- 找近邻: 找出K个最近的点
- 统计投票: 统计这K个点中各类别的数量KkK_kKk
- 分类决策: 选择KkK_kKk最大的类别,或按Kk/KK_k/KKk/K给出概率
参数选择
K值的选择:
- K=1:最近邻分类,对噪声敏感
- K太大:过度平滑,可能丢失局部结构
- 常用选择:K=NK = \sqrt{N}K=N,或通过交叉验证确定
理论优势
1. 理论基础坚实
- 基于贝叶斯决策理论
- 有明确的概率解释
- 收敛性有理论保证


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









