




 本文详细介绍了顺序表的概念、基本操作和优化,包括结构体的使用、初始化、插入、删除、修改和打印数据。接着讨论了单向链表、单向循环链表和双向链表,包括它们的结构、操作和优缺点。此外,还提到了内核链表的使用和遍历方法,以及如何通过内核链表提供的接口进行操作。
本文详细介绍了顺序表的概念、基本操作和优化,包括结构体的使用、初始化、插入、删除、修改和打印数据。接着讨论了单向链表、单向循环链表和双向链表,包括它们的结构、操作和优缺点。此外,还提到了内核链表的使用和遍历方法,以及如何通过内核链表提供的接口进行操作。
什么是顺序表
顺序表的本质就是个数组,顺序表是用数组来存放数据
总结成公式,顺序表应该采用如下的结构体来表示
struct 顺序表的名字
{
你想使用的某种数据类型 data[数组元素个数]; //存放真实数据的数组
int last; //标记当前顺序表(数组)中最后一个有效成员的下标
};
具体例子:
struct student
{
char name[20];
int age;
};
struct 顺序表的名字
{
struct student data[数组元素个数]; //存放真实数据的数组
//int data[数组元素个数];
//float data[数组元素个数];
int last; //标记当前顺序表(数组)中最后一个有效成员的下标
};
2.顺序表的基本操作
初始化顺序表
插入数据到顺序表
删除数据
修改数据
查询打印数据
3.顺序表的优化和扩展
优化一:数组的元素个数用宏定义代替
优化二:typedef给顺序表结构体取个别名
优化三:typedef给顺序表结构体中的数组类型取个别名(通用性好一点)
补充知识点:
结构体可以直接赋值,但是不可以直接比较
#include "myhead.h"
struct student
{
int age;
char name[20];
};
int main()
{
struct student stu1={18,"zhangsan"};
struct student stu4={19,"wangwu"};
//就算你不知道结构体变量可以直接用等于号赋值
//struct student stu2=stu1; //把刚才stu1直接赋值给stu2
//传统写法
struct student stu3;
stu3.age=stu1.age;
strcpy(stu3.name,stu1.name);
//int a=99;
//int b=a;
printf("学生年龄:%d\n",stu3.age);
printf("学生姓名:%s\n",stu3.name);
//结构体的比较 不能整体去比较 > < == != 只能把里面的元素分别比较
}
结构体指针、结构体的嵌套
#include "myhead.h"
//定义一个结构体表示书籍信息
struct bookmsg //书籍
{
char bookname[20]; //书籍名称
float bookprice; //书籍价格
};
//定义另外一个结构体表示读者
struct reader //读者
{
char readername[20]; //读者名字
struct bookmsg bookarray[10]; //每个读者最多只能借阅10本书
int age; //读者年龄
};
int main()
{
//写法一:定义普通(非指针)的结构体变量
struct reader r1;
strcpy(r1.readername,"马云");
strcpy(r1.bookarray[0].bookname,"红楼梦");
r1.bookarray[0].bookprice=55.6;
strcpy(r1.bookarray[1].bookname,"西游记");
r1.bookarray[1].bookprice=58.6;
r1.age=55;
//写法二:定义结构体指针
struct reader *r2=malloc(sizeof(struct reader));
strcpy(r2->readername,"马化腾");
strcpy(r2->bookarray[0].bookname,"水浒传");
r2->bookarray[0].bookprice=45.6;
strcpy(r2->bookarray[1].bookname,"三国演义");
r2->bookarray[1].bookprice=68.6;
r2->age=48;
}
typedef用法
#include "myhead.h"
//用法一:给基本数据类型(int double float char short........)取别名
typedef unsigned int u32;
//用法二:给数组取个别名
typedef int arrayname[10]; //给int[10]这种类型的数组取个别名叫做arrayname
//用法三:给指针取别名
typedef int *ppp; //给int *取了别名叫做ppp
int main()
{
//传统做法
unsigned int a=99;
//使用别名
u32 b=77; //等价于unsigned int b=77;
//定义整型数组
int c[10];
//使用别名
arrayname d; //d就是int[10] 等价于int d[10];
d[0]=11;
d[1]=12;
//定义指针
int *p;
ppp q; //等价于int *q;
}
顺序表的普通版本
#include "myhead.h"
//定义一个结构体来表示顺序表
struct seqlist
{
//假设顺序表用来存放整数
int data[100];
//定义一个变量标记顺序表的最后一个有效成员下标
int last;
};
//顺序表的初始化
struct seqlist *seqlist_init()
{
//struct seqlist mylist; //栈空间不太合适,原因栈空间函数调用完毕就自动释放了
struct seqlist *mylist=malloc(sizeof(struct seqlist)); //堆空间
//清空数组
bzero(mylist->data,sizeof(mylist->data));
//初始化有效成员下标
mylist->last=-1;
return mylist; //此时mylist不会释放
}
//插入数据 -->尾插(顺序表/数组的最后面插入)
int seqlist_insert(struct seqlist *list,int newdata)
{
list->last++;
list->data[list->last]=newdata;
}
//查询打印顺序表中的数据
int seqlist_print(struct seqlist *list)
{
int i;
for(i=0; i<=list->last; i++)
printf("目前遍历的成员是:%d\n",list->data[i]);
}
int main()
{
//初始化顺序表
struct seqlist *mylist=seqlist_init();
//尾插一些数据
seqlist_insert(mylist,18);
seqlist_insert(mylist,28);
seqlist_insert(mylist,38);
//查询打印顺序表中的数据
seqlist_print(mylist);
}
顺序表的优化版本
#include "myhead.h"
#define N 7
//使用typedef给顺序表中的那个数组类型取个别名
typedef int datatype;
//定义一个结构体来表示顺序表
typedef struct seqlist
{
//假设顺序表用来存放整数
datatype data[N];
//定义一个变量标记顺序表的最后一个有效成员下标
int last;
}slist;
//顺序表的初始化
struct seqlist *seqlist_init()
{
//struct seqlist mylist; //栈空间不太合适,原因栈空间函数调用完毕就自动释放了
struct seqlist *mylist=malloc(sizeof(struct seqlist)); //堆空间
printf("分配的地址:%p\n",mylist);
//清空数组
bzero(mylist->data,sizeof(mylist->data));
//初始化有效成员下标
mylist->last=-1;
return mylist; //此时mylist不会释放
}
//判断顺序表是否满了
bool is_full(struct seqlist *list)
{
if(list->last>=N-1)
return true;
else
return false;
}
//判断顺序表是否空了
bool is_empty(struct seqlist *list)
{
if(list->last<0)
return true;
else
return false;
}
//插入数据 -->尾插(顺序表/数组的最后面插入)
int seqlist_insert(struct seqlist *list,datatype newdata)
{
printf("分配的地址:%p\n",list);
//判断顺序表是否满了
if(is_full(list))
{
printf("对不起,顺序表满了!\n");
return -1;
}
list->last++;
list->data[list->last]=newdata;
return 0;
}
//删除元素
int seqlist_remove(struct seqlist *list,int delnum)
{
int i,j;
int flag=0; //用来标记是否存在delnum这个数
//判断顺序表是否空了
if(is_empty(list))
{
printf("对不起,顺序表空了!\n");
return -1;
}
//找到要删除的数据
for(i=0; i<=list->last; i++)
{
if(list->data[i]==delnum) //找到了要删除的数据(只删除第一个delnum)
{
flag=1;
//后面的数据往前挪动
for(j=i; j<list->last; j++)
list->data[j]=list->data[j+1];
list->last--;
break;
}
}
//装模作样判断flag的值
if(flag==0) //说明flag没有发生任何变化--》delnum不存在
{
printf("对不起,没有你给定的删除数据!\n");
return -1;
}
}
//修改顺序表中的数据
int seqlist_update(struct seqlist *list,int oldnum,int newnum)
{
int i;
int flag=0; //用来标记是否存在oldnum这个数
//找到要修改的数据
for(i=0; i<=list->last; i++)
{
if(list->data[i]==oldnum) //找到了要修改的数据(只修改第一个oldnum)
{
flag=1;
list->data[i]=newnum;
break;
}
}
//装模作样判断flag的值
if(flag==0) //说明flag没有发生任何变化--》oldnum不存在
{
printf("对不起,没有你给定的修改数据!\n");
return -1;
}
}
//查询打印顺序表中的数据
int seqlist_print(struct seqlist *list)
{
int i;
for(i=0; i<=list->last; i++)
printf("目前遍历的成员是:%d\n",list->data[i]);
}
int main()
{
//初始化顺序表
struct seqlist *mylist=seqlist_init();
printf("分配的地址:%p\n",mylist);
//尾插一些数据
seqlist_insert(mylist,18);
seqlist_insert(mylist,18);
seqlist_insert(mylist,18);
seqlist_insert(mylist,28);
seqlist_insert(mylist,18);
seqlist_insert(mylist,38);
seqlist_insert(mylist,48);
seqlist_print(mylist);
//删除数据
//seqlist_remove(mylist,18);
//修改数据
printf("修改之后======================\n");
seqlist_update(mylist,28,78);
//查询打印顺序表中的数据
seqlist_print(mylist);
//释放堆空间 --》顺序表的销毁
free(mylist);
return 0;
}
顺序表中存放结构体变量
#include "myhead.h"
#define N 7
//定义学生结构体
struct student
{
char name[20];
int age;
};
//使用typedef给顺序表中的那个数组类型取个别名
typedef struct student datatype;
//定义一个结构体来表示顺序表
typedef struct seqlist
{
//假设顺序表用来存放整数
datatype data[N];
//定义一个变量标记顺序表的最后一个有效成员下标
int last;
}slist;
//顺序表的初始化
struct seqlist *seqlist_init()
{
//struct seqlist mylist; //栈空间不太合适,原因栈空间函数调用完毕就自动释放了
struct seqlist *mylist=malloc(sizeof(struct seqlist)); //堆空间
//清空数组
bzero(mylist->data,sizeof(mylist->data));
//初始化有效成员下标
mylist->last=-1;
return mylist; //此时mylist不会释放
}
//判断顺序表是否满了
bool is_full(struct seqlist *list)
{
if(list->last>=N-1)
return true;
else
return false;
}
//判断顺序表是否空了
bool is_empty(struct seqlist *list)
{
if(list->last<0)
return true;
else
return false;
}
//插入数据 -->尾插(顺序表/数组的最后面插入)
int seqlist_insert(struct seqlist *list,datatype newdata)
{
//判断顺序表是否满了
if(is_full(list))
{
printf("对不起,顺序表满了!\n");
return -1;
}
list->last++;
list->data[list->last]=newdata; //结构体变量可以直接赋值
return 0;
}
//删除元素
int seqlist_remove(struct seqlist *list,datatype delnum)
{
int i,j;
int flag=0; //用来标记是否存在delnum这个数
//判断顺序表是否空了
if(is_empty(list))
{
printf("对不起,顺序表空了!\n");
return -1;
}
//找到要删除的数据
for(i=0; i<=list->last; i++)
{
if((strcmp(list->data[i].name,delnum.name)==0) && (list->data[i].age==delnum.age)) //找到了要删除的数据(只删除第一个delnum)
{
flag=1;
//后面的数据往前挪动
for(j=i; j<list->last; j++)
list->data[j]=list->data[j+1];
list->last--;
break;
}
}
//装模作样判断flag的值
if(flag==0) //说明flag没有发生任何变化--》delnum不存在
{
printf("对不起,没有你给定的删除数据!\n");
return -1;
}
}
//修改顺序表中的数据
int seqlist_update(struct seqlist *list,datatype oldnum,datatype newnum)
{
int i;
int flag=0; //用来标记是否存在oldnum这个数
//找到要修改的数据
for(i=0; i<=list->last; i++)
{
if((strcmp(list->data[i].name,oldnum.name)==0) && (list->data[i].age==oldnum.age)) //找到了要修改的数据(只修改第一个oldnum)
{
flag=1;
list->data[i]=newnum;
break;
}
}
//装模作样判断flag的值
if(flag==0) //说明flag没有发生任何变化--》oldnum不存在
{
printf("对不起,没有你给定的修改数据!\n");
return -1;
}
}
//查询打印顺序表中的数据
int seqlist_print(struct seqlist *list)
{
int i;
for(i=0; i<=list->last; i++)
{
printf("学生姓名:%s\n",list->data[i].name);
printf("学生年龄:%d\n",list->data[i].age);
}
}
int main()
{
struct student stu1={"张三",18};
struct student stu2={"李四",19};
struct student stu3={"王五",17};
struct student stu4={"赵六",20};
struct student stu5={"孙八",21};
struct student stu6={"钱九",22};
//初始化顺序表
struct seqlist *mylist=seqlist_init();
//尾插一些数据
seqlist_insert(mylist,stu1);
seqlist_insert(mylist,stu2);
seqlist_insert(mylist,stu3);
//删除数据
//seqlist_remove(mylist,stu2);
//seqlist_print(mylist);
//修改数据
printf("修改之后======================\n");
seqlist_update(mylist,stu1,stu6);
//查询打印顺序表中的数据
seqlist_print(mylist);
//释放堆空间 --》顺序表的销毁
free(mylist);
return 0;
}
单向链表
1.什么是链表(单向链表)
diss(鄙视)一下数组(顺序表)的缺陷
第一:数组在定义的时候需要确定元素个数,一旦确定了无法修改(不够灵活)
int array[10000]
第二:数组的存储空间必须是一整块连续的内存区域,对于内存的要求比较高,使用效率低
第三:数组中间插入数据,或者删除数据很麻烦(需要挪动数据)
链表可以完美地解决以上三个问题
链表的原理:
总结成公式/模型
struct 链表的名字
{
//数据域 --》存放真实数据的那个变量就是数据域
int data; //数据域,存放整数
//指针域 --》存放下一个数据在内存中的首地址
struct 链表的名字 *next;
};
理论概念:
头结点:链表中起始位置(初始化链表的时候)的那个节点就是头结点
头结点有两种写法:
写法一:头结点中不存放任何有效数据(空的头结点,不要错误的理解成头结点为NULL)
实际开发中绝大部分情况下都是使用空的头结点(原因是程序员最开始根本就不知道究竟要往头结点中存放啥玩意)
写法二:头结点中存放有效数据(非空头结点)
普通结点:你使用malloc给链表结构体指针分配了堆空间,此时堆空间就表示一个节点
2.单链表的基本操作
单链表的初始化
增删改查
单链表的销毁
什么时候销毁链表:程序结束的时候
为什么要销毁链表:因为之前你插入的所有结点都是使用堆空间,堆空间需要程序员主动调用free去释放的
3.单链表学习方法
方法一:通过画图去理解指针之间的关系(如果不画图,容易把指针之间的指向关系弄混淆)
方法二:画图的时候,一条路走不通,可以调整顺序
方法三:一个指针搞不定,用两个指针(一前一后,精诚合作)
4.写代码,看代码,找bug的方法经验
第一个:看代码的时候,取特殊值代入代码中,配合画图去理解
第二个:自己写代码,可以用伪代码帮助你理清思路
什么是伪代码?
可以用文字代替真实代码,帮助你理解代码的框架思路
单链表的基本操作
#include "myhead.h"
//定义一个结构体来表示单链表
struct siglelist
{
//数据域--》存放整数
int data;
//指针域--》存放下一个数据在内存中的首地址
struct siglelist *next;
};
//封装单链表的初始化--》初始化链表的头结点(表头)
struct siglelist *list_init()
{
struct siglelist *head=malloc(sizeof(struct siglelist));
//演示头结点中存放有效数据
head->data=18;
head->next=NULL;
return head; //返回头结点指针
}
//尾插数据
int list_insert_tail(struct siglelist *head,int newdata)
{
//给新的结点分配堆空间
struct siglelist *newnode=malloc(sizeof(struct siglelist));
newnode->data=newdata; //数据域
newnode->next=NULL; //指针域
//把newnode代表的结点插入到head表示的链表尾部
//head->next=newnode; 错误的写法,每一次新的结点都存放到head的后面(不是链表的尾部)
//找到链表的尾部
struct siglelist *p=head; //p用来找到链表的最后面的那个结点位置
while(p->next!=NULL) //只要p后面的结点不为NULL,循环继续
{
p=p->next; //循环成立,p就往后挪动
}
p->next=newnode;
}
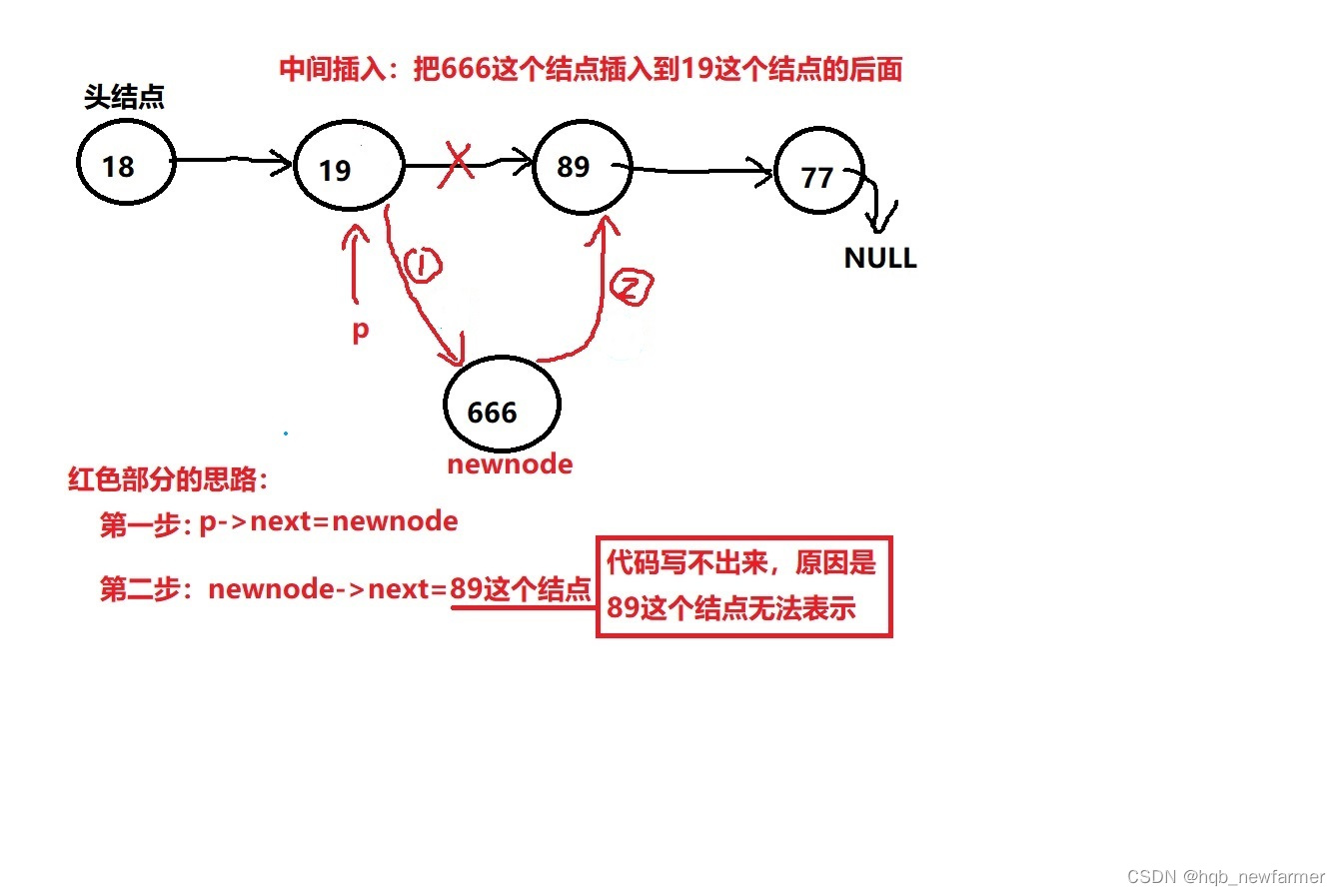
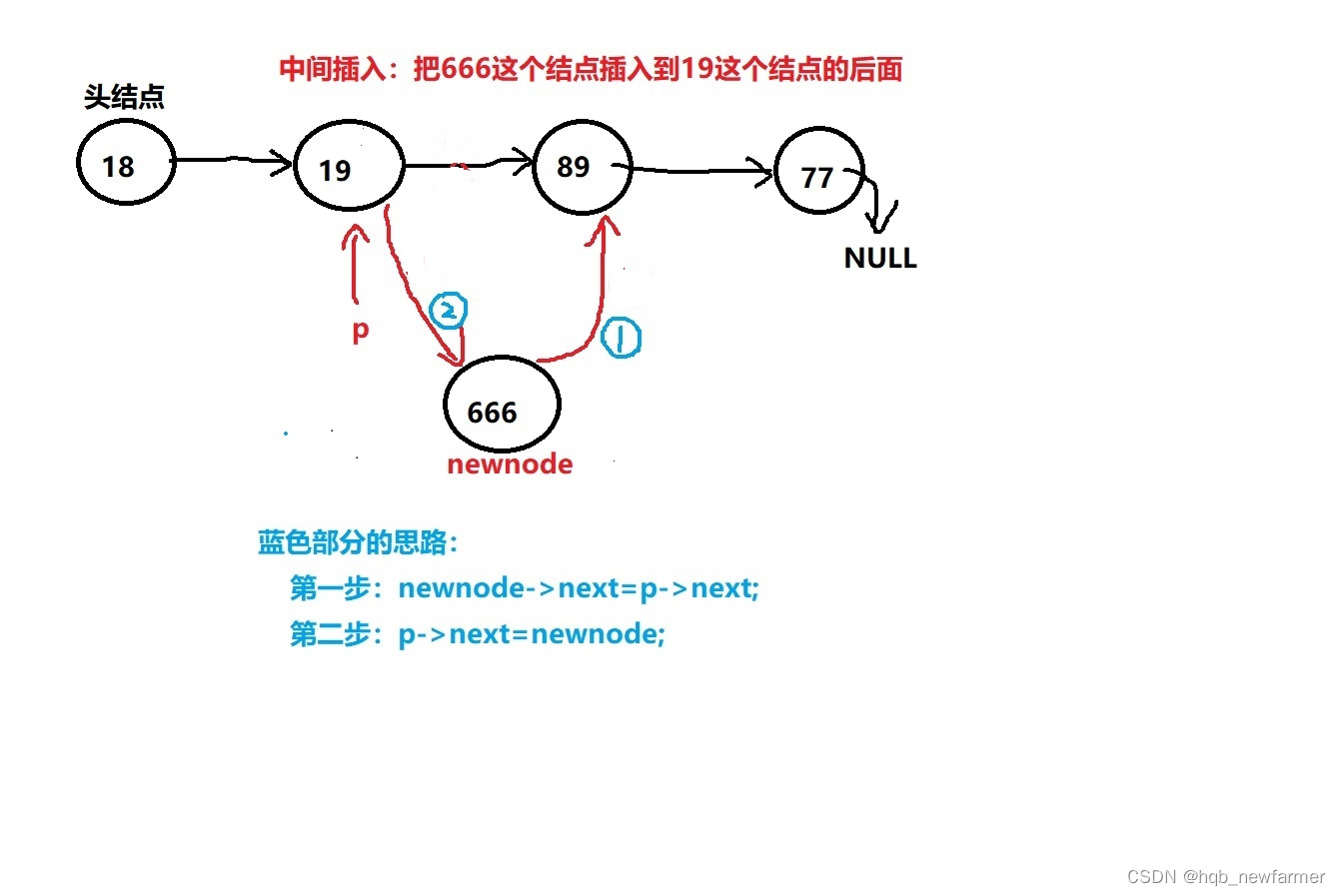
//中间插入数据 --》把newdata插入到链表中somedata所代表的那个结点的后面
int list_insert_mid(struct siglelist *head,int somedata,int newdata)
{
//第一步:找到somedata对应的结点
struct siglelist *p=head;
while(p->next!=NULL)
{
p=p->next;
if(p->data==somedata)
break; //找到就退出循环
}
//循环结束的时候p指向的就是somedata对应的结点
//把新的结点插入到p的后面
//准备新的结点
struct siglelist *newnode=malloc(sizeof(struct siglelist));
newnode->data=newdata;
newnode->next=NULL;
//照着彭老师单链表中间插入图示分析写代码
newnode->next=p->next;
p->next=newnode;
}
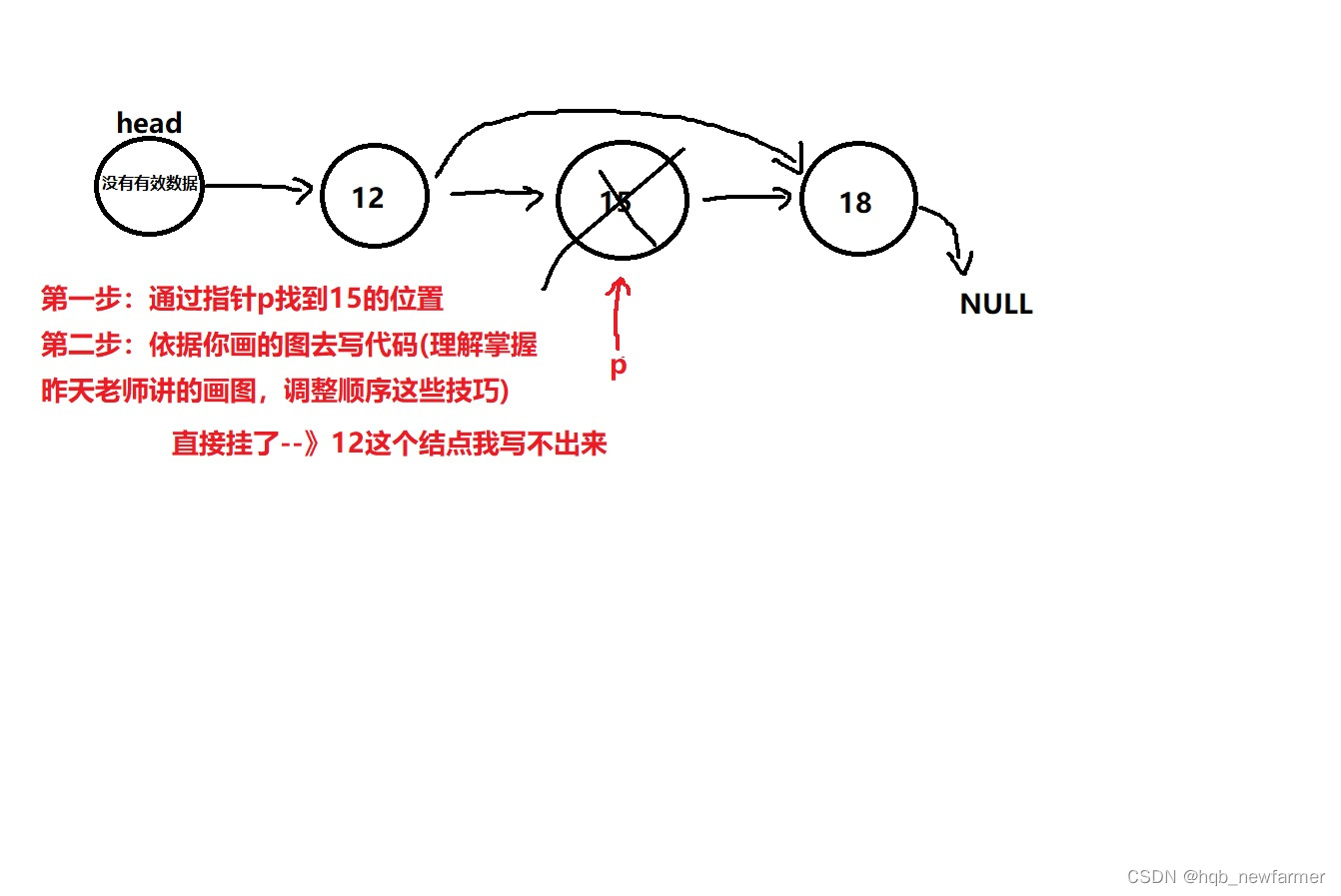
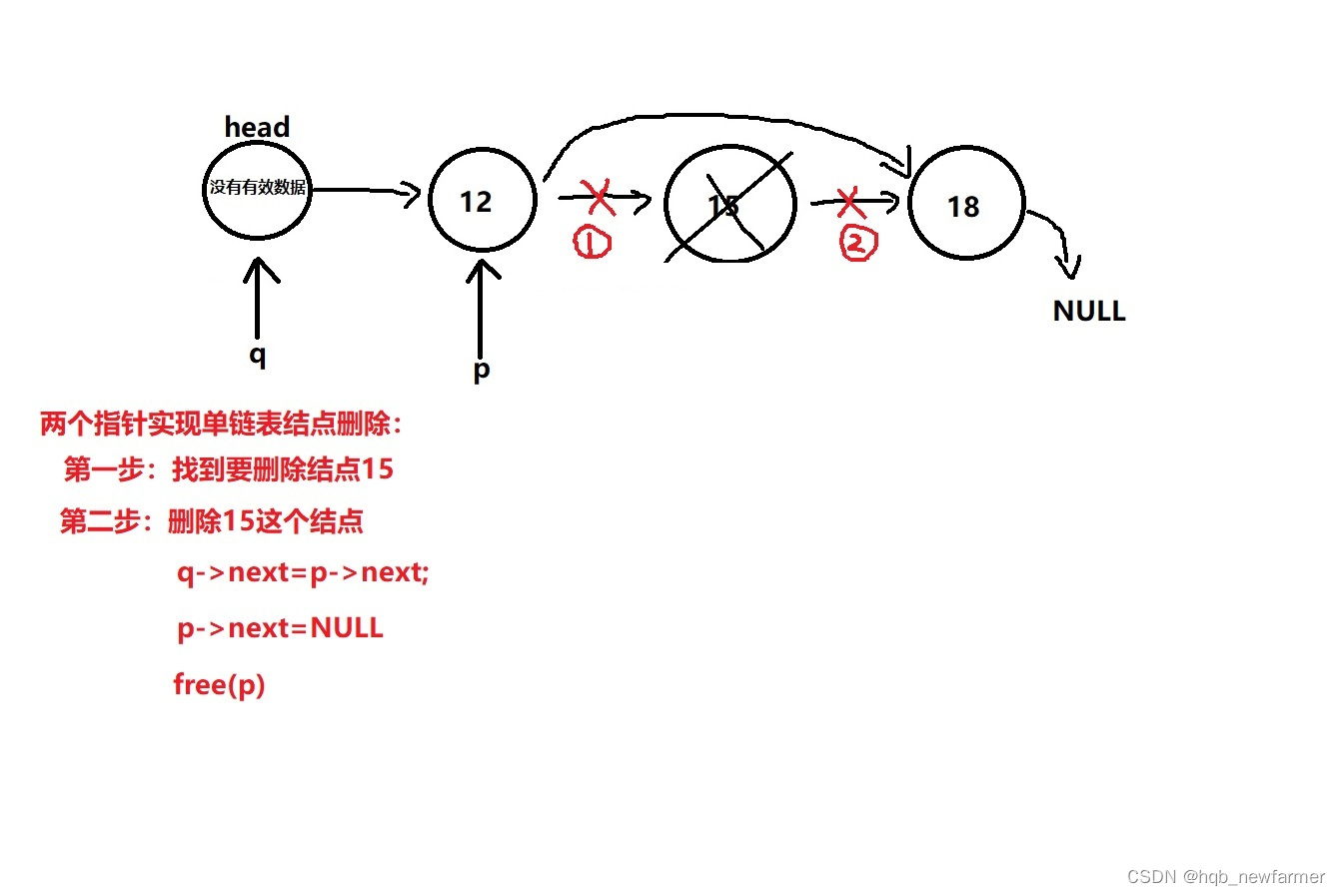
//链表的删除
//把delnum这个数据对应的结点从head表示的链表中删除
int list_delete(struct siglelist *head,int delnum)
{
//定义两个指针一前一后配合遍历链表
struct siglelist *q=head;
struct siglelist *p=head->next;
//遍历链表找到要删除的结点
while(p->next!=NULL)
{
if(p->data==delnum)
break; //找到了就退出循环
//没有找到,p和q同时往后挪动
p=p->next;
q=q->next;
}
//单独判断最后一个结点就行了
if(p->next==NULL && p->data!=delnum)
{
printf("对不起,你要删除的数据%d不存在!\n",delnum);\
return -1;
}
//删除对应的结点
q->next=p->next;
p->next=NULL;
free(p);
return 0;
}
//链表修改结点数据
int list_update(struct siglelist *head,int oldnum,int newnum)
{
//找到oldnum对应的结点
struct siglelist *p=head;
while(p->next!=NULL)
{
p=p->next;
if(p->data==oldnum)
break; //找到了就退出循环
}
//把oldnum对应的结点中的数据改成newnum
p->data=newnum;
return 0;
}
//打印链表信息
int list_print(struct siglelist *head)
{
struct siglelist *p=head; //p指向链表的表头
printf("遍历的数据是:%d\n",p->data);
while(p->next!=NULL) //只要p后面的结点不为NULL,循环继续
{
p=p->next;
printf("遍历的数据是:%d\n",p->data);
}
}
//单链表的销毁
int list_destroy(struct siglelist *head)
{
struct siglelist *p;
//循环删除头结点后面的结点
while(head->next!=NULL)
{
p=head->next; //p指向第一个有效结点
head->next=p->next;
p->next=NULL;
free(p); //p已经是野指针
}
//循环结束的时候,就只剩下头结点没有删除
free(head);
return 0;
}
int main()
{
//初始化链表的表头
struct siglelist *myhead=list_init();
//struct siglelist *otherhead=list_init(); 创建另外一个链表
//尾插数据到链表中
list_insert_tail(myhead,19);
list_insert_tail(myhead,89);
list_insert_tail(myhead,77);
//中间插入数据
list_insert_mid(myhead,19,666);
//打印数据
list_print(myhead);
//删除89
list_delete(myhead,100);
printf("=============删除以后=============\n");
list_print(myhead);
//修改数据
//list_update(myhead,77,177);
//printf("=============修改以后=============\n");
//list_print(myhead);
//单链表的销毁
list_destroy(myhead);
return 0;
}
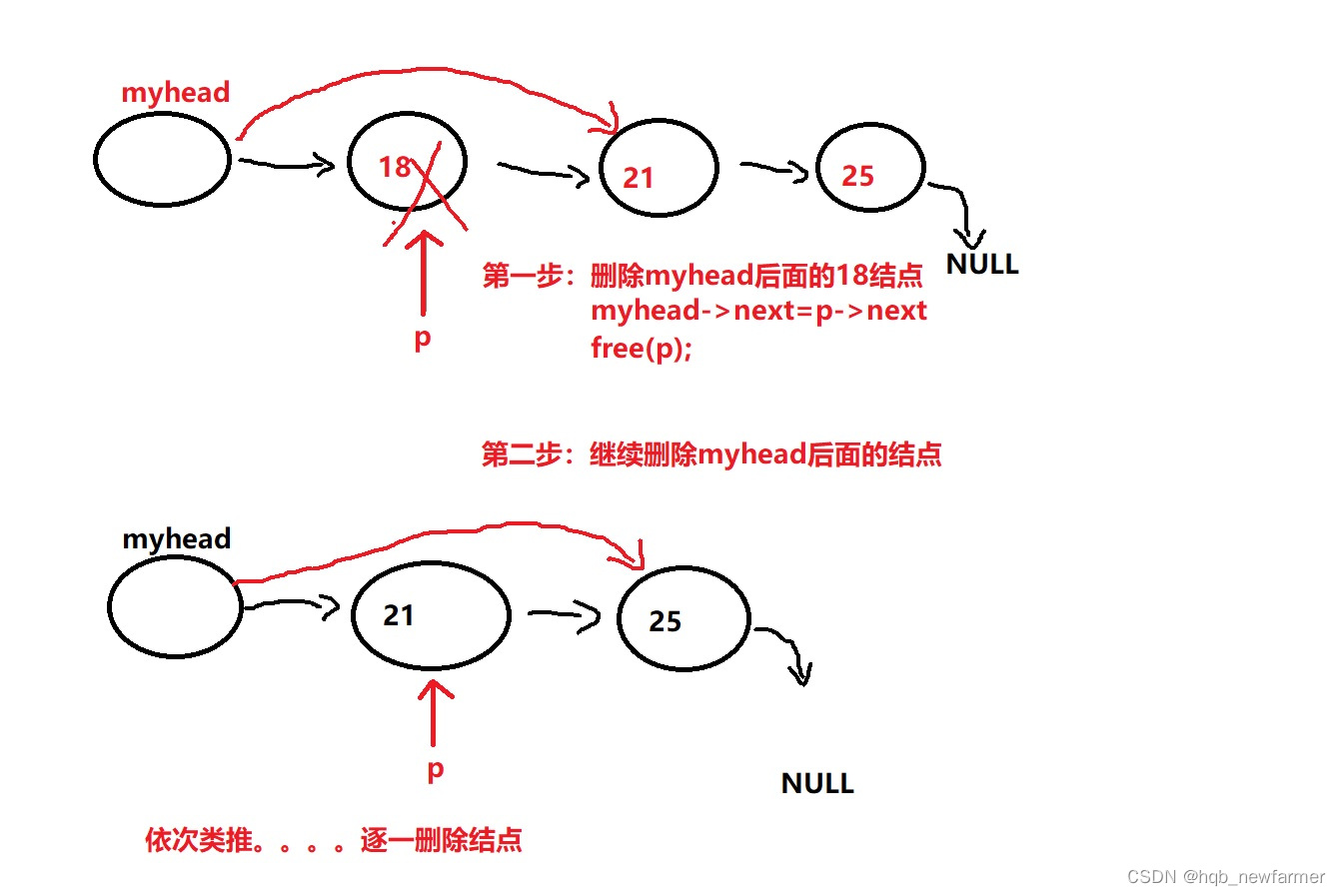
其中面试最常问的是中间插入节点,以及删除某个节点,由图可以直观反映出来
单链表的销毁
单向循环链表
1.对比普通的单链表
普通的单链表:收尾不相接
while(p->next!=NULL)
p=p->next;
单向循环链表:首尾相接
while(p->next!=头结点)
p=p->next;
2.表示单向循环链表
struct 单向循环链表
{
//数据域
//指针域
};
单向循环链表基本操作
#include "myhead.h"
//定义一个结构体来表示单向循环链表
struct siglelist
{
//数据域--》存放整数
int data;
//指针域--》存放下一个数据在内存中的首地址
struct siglelist *next;
};
//封装单向循环链表的初始化--》初始化链表的头结点(表头)
struct siglelist *list_init()
{
struct siglelist *head=malloc(sizeof(struct siglelist));
//头结点里面不打算存放数据
head->next=head;
return head; //返回头结点指针
}
//尾插数据
int list_insert_tail(struct siglelist *head,int newdata)
{
//给新的结点分配堆空间
struct siglelist *newnode=malloc(sizeof(struct siglelist));
newnode->data=newdata; //数据域
newnode->next=NULL; //指针域
//把newnode代表的结点插入到head表示的链表尾部
//找到链表的尾部
struct siglelist *p=head; //p用来找到链表的最后面的那个结点位置
while(p->next!=head) //只要p后面的结点不为头结点,循环继续
{
p=p->next; //循环成立,p就往后挪动
}
//尾插新结点
p->next=newnode;
newnode->next=head;
return 0;
}
//中间插入数据 --》把newdata插入到链表中somedata所代表的那个结点的后面
int list_insert_mid(struct siglelist *head,int somedata,int newdata)
{
//第一步:找到somedata对应的结点
struct siglelist *p=head;
while(p->next!=head)
{
p=p->next;
if(p->data==somedata)
break; //找到就退出循环
}
//循环结束的时候p指向的就是somedata对应的结点
//把新的结点插入到p的后面
//准备新的结点
struct siglelist *newnode=malloc(sizeof(struct siglelist));
newnode->data=newdata;
newnode->next=NULL;
//照着彭老师单链表中间插入图示分析写代码
newnode->next=p->next;
p->next=newnode;
}
//链表的删除
//把delnum这个数据对应的结点从head表示的链表中删除
int list_delete(struct siglelist *head,int delnum)
{
//定义两个指针一前一后配合遍历链表
struct siglelist *q=head;
struct siglelist *p=head->next;
//遍历链表找到要删除的结点
while(p->next!=head)
{
if(p->data==delnum)
break; //找到了就退出循环
//没有找到,p和q同时往后挪动
p=p->next;
q=q->next;
}
//单独判断最后一个结点
if(p->next==head && p->data!=delnum)
{
printf("对不起,没有你要删除的数据%d\n",delnum);
return -1;
}
//删除对应的结点
q->next=p->next;
p->next=NULL;
free(p);
return 0;
}
//链表修改结点数据
int list_update(struct siglelist *head,int oldnum,int newnum)
{
//找到oldnum对应的结点
struct siglelist *p=head;
while(p->next!=head)
{
p=p->next;
if(p->data==oldnum)
break; //找到了就退出循环
}
//把oldnum对应的结点中的数据改成newnum
p->data=newnum;
return 0;
}
//打印链表信息
int list_print(struct siglelist *head)
{
struct siglelist *p=head; //p指向链表的表头
while(p->next!=head) //只要p后面的结点不为头结点,循环继续
{
p=p->next;
printf("遍历的数据是:%d\n",p->data);
}
}
//单链表的销毁
int list_destroy(struct siglelist *head)
{
struct siglelist *p;
//循环删除头结点后面的结点
while(head->next!=head)
{
p=head->next; //p指向第一个有效结点
head->next=p->next;
p->next=NULL;
free(p); //p已经是野指针
}
//循环结束的时候,就只剩下头结点没有删除
free(head);
return 0;
}
int main()
{
//初始化链表的表头
struct siglelist *myhead=list_init();
//尾插数据到链表中
list_insert_tail(myhead,19);
list_insert_tail(myhead,89);
list_insert_tail(myhead,77);
//中间插入数据
list_insert_mid(myhead,19,666);
list_print(myhead);
//删除数据
list_delete(myhead,111);
printf("===========删除之后===========\n");
//打印数据
list_print(myhead);
//销毁链表
list_destroy(myhead);
return 0;
}
双向链表
1.什么是双向链表
在普通单向链表的基础上,再增加一个指针(该指针用来指向前面一个结点的地址)
2.表示双向链表
struct 双向链表
{
//数据域
//指针域
};
比如:创建一个存放整数的双向链表
struct doublelist
{
//数据域
int data;
//指针域
struct doublelist *next; //保存当前结点后面的那个结点的地址
struct doublelist *prev; //保存当前结点前面的那个结点的地址
}
3.基本操作
初始化
增删改查
销毁
#include "myhead.h"
//定义一个结构体表示双向链表
struct doublelist
{
//数据域
int data;
//指针域
struct doublelist *next;
struct doublelist *prev;
};
//双向链表的初始化
struct doublelist *list_init()
{
//给头结点分配堆空间
struct doublelist *head=malloc(sizeof(struct doublelist));
//初始化头结点中的指针域
head->next=NULL;
head->prev=NULL;
return head;
}
//尾插
int list_insert_tail(struct doublelist *head,int newdata)
{
//准备好新的结点
struct doublelist *newnode=malloc(sizeof(struct doublelist));
newnode->data=newdata;
newnode->next=NULL;
newnode->prev=NULL;
//找到链表的尾部
struct doublelist *p=head;
while(p->next!=NULL)
p=p->next;
//尾插
p->next=newnode;
newnode->prev=p;
}
/* int a=55;
int b=55;
int *p=&a;
int *q=&b;
if(p==q) 错误了p和q存放的地址肯定不同啊
*/
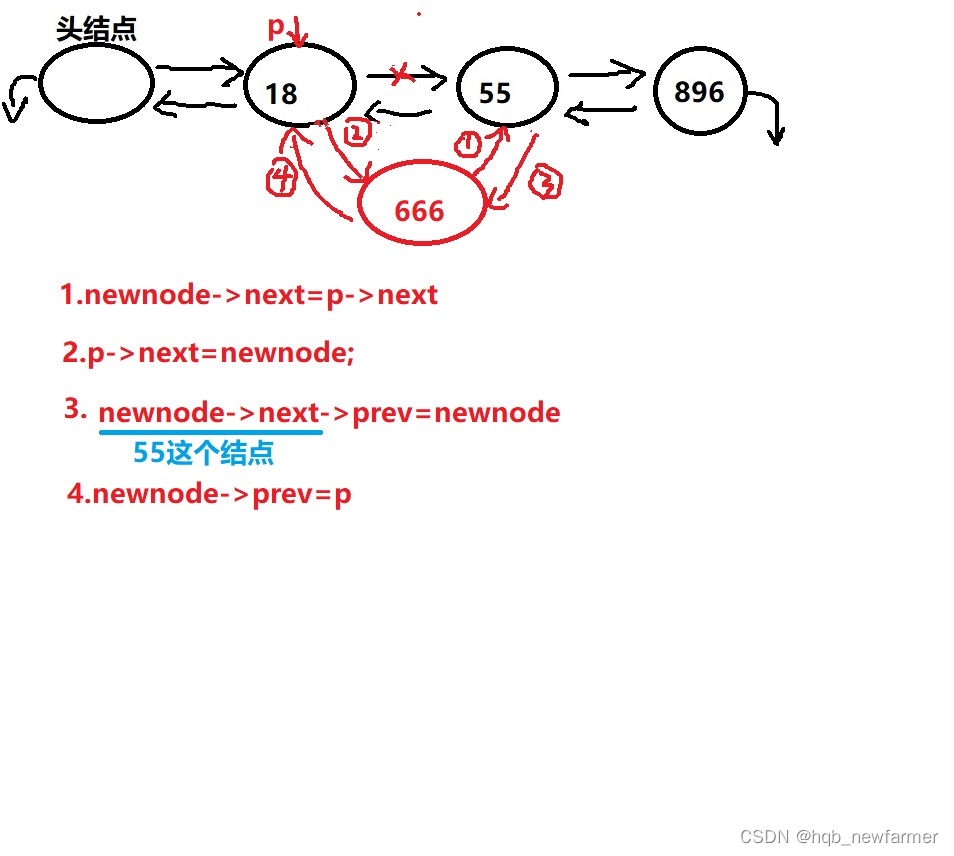
//中间插入-->newdata插入到olddata代表的那个结点的后面
int list_insert_mid(struct doublelist *head,int olddata,int newdata)
{
//找到老数据对应的结点
struct doublelist *p=head;
while(p->next!=NULL)
{
p=p->next;
if(p->data==olddata) //找到了就结束循环
break;
}
//准备好新的结点
struct doublelist *newnode=malloc(sizeof(struct doublelist));
newnode->data=newdata;
newnode->next=NULL;
newnode->prev=NULL;
//把新的结点插入到p指向的结点的后面
newnode->next=p->next;
p->next=newnode;
newnode->next->prev=newnode;
newnode->prev=p;
}
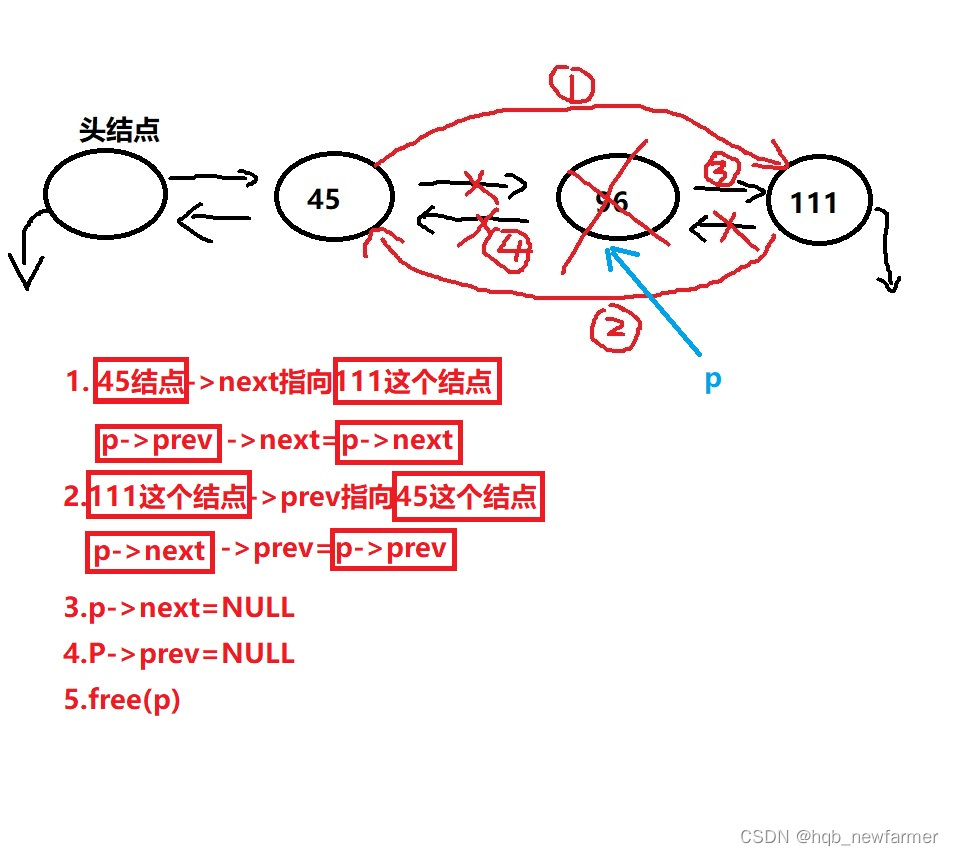
//删除结点
int list_remove(struct doublelist *head,int delnum)
{
//找到需要删除的数据
struct doublelist *p=head;
while(p->next!=NULL)
{
if(p->data==delnum) //只要找到需要删除的数据,就不断的删除
{
//在删除该结点之前,把这个结点后面的那个结点地址做个备份(方便等一会删除p以后,p可以顺利地重新指向新的位置)
struct doublelist *q=p->next;
//删除结点--》中间位置的结点
p->prev->next=p->next;
p->next->prev=p->prev;
p->next=NULL;
p->prev=NULL;
free(p); //此时p变成了野指针
//更新p的位置
p=q;
}
else
p=p->next;
}
//经过仔细分析--》发现上面的循环漏掉了最后一个结点
//单独判断p指向最后一个结点这种情况
if(p->next==NULL && p->data==delnum)
{
p->prev->next=NULL;
p->prev=NULL;
free(p);
return 0;
}
return 0;
}
//打印
int list_print(struct doublelist *head)
{
struct doublelist *p=head;
while(p->next!=NULL)
{
p=p->next;
printf("当前遍历的结点中数据是:%d\n",p->data);
}
}
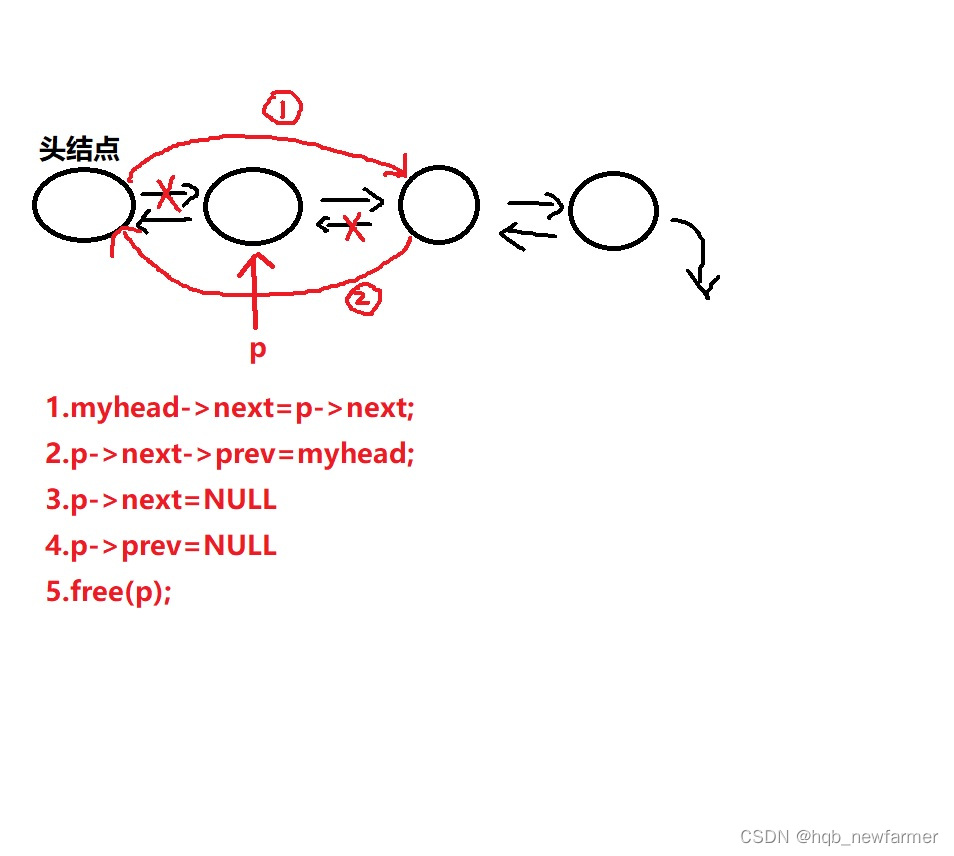
//链表的销毁
int list_destroy(struct doublelist *head)
{
struct doublelist *p;
//循环删除头结点后面的那个结点(紧挨着头结点的那个结点)
while(head->next!=NULL)
{
//更新p
p=head->next;
//由于最后一个结点删除代码跟中间位置结点写法不同
//单独判断最后一个结点
if(p->next==NULL) //说明此时p已经到了最后一个结点的位置
{
head->next=NULL;
p->prev=NULL;
free(p);
return 0;
}
//说明p指向的是中间位置的结点
head->next=p->next;
p->next->prev=head;
p->next=NULL;
p->prev=NULL;
free(p); //p就是野指针
}
//循环结束的时候,头结点后面的所有结点都删除完毕
//单独释放头结点即可
free(head);
return 0;
}
int main()
{
//初始化链表
struct doublelist *myhead=list_init();
//尾插一些数据
list_insert_tail(myhead,18);
list_insert_tail(myhead,18);
list_insert_tail(myhead,38);
list_insert_tail(myhead,18);
list_insert_tail(myhead,18);
list_insert_tail(myhead,18);
list_insert_tail(myhead,18);
//中间插入
list_insert_mid(myhead,38,666);
list_print(myhead);
printf("===========删除之后==========\n");
//删除重复的结点
list_remove(myhead,18);
//打印
list_print(myhead);
//销毁链表
list_destroy(myhead);
return 0;
}
双向链表节点的删除、插入以及销毁
双向循环链表
1.特点
要求:最后一个结点的next指针指向头结点
头结点的prev指针指向最后一个结点
#include "myhead.h"
//定义一个结构体表示双向循环链表
struct doublelist
{
//数据域
int data;
//指针域
struct doublelist *next;
struct doublelist *prev;
};
//双向循环链表的初始化
struct doublelist *list_init()
{
//给头结点分配堆空间
struct doublelist *head=malloc(sizeof(struct doublelist));
//初始化头结点中的指针域
head->next=head;
head->prev=head;
return head;
}
//尾插
int list_insert_tail(struct doublelist *head,int newdata)
{
//准备好新的结点
struct doublelist *newnode=malloc(sizeof(struct doublelist));
newnode->data=newdata;
newnode->next=NULL;
newnode->prev=NULL;
//找到链表的尾部
struct doublelist *p=head;
while(p->next!=head)
p=p->next;
//尾插
p->next=newnode;
newnode->prev=p;
newnode->next=head;
head->prev=newnode;
return 0;
}
//中间插入-->newdata插入到olddata代表的那个结点的后面
int list_insert_mid(struct doublelist *head,int olddata,int newdata)
{
//找到老数据对应的结点
struct doublelist *p=head;
while(p->next!=head)
{
p=p->next;
if(p->data==olddata) //找到了就结束循环
break;
}
//准备好新的结点
struct doublelist *newnode=malloc(sizeof(struct doublelist));
newnode->data=newdata;
newnode->next=NULL;
newnode->prev=NULL;
//把新的结点插入到p指向的结点的后面
newnode->next=p->next;
p->next=newnode;
newnode->next->prev=newnode;
newnode->prev=p;
return 0;
}
//删除结点
int list_remove(struct doublelist *head,int delnum)
{
//找到需要删除的数据
struct doublelist *p=head;
while(p->next!=head)
{
if(p->data==delnum) //只要找到需要删除的数据,就不断的删除
{
//在删除该结点之前,把这个结点后面的那个结点地址做个备份(方便等一会删除p以后,p可以顺利地重新指向新的位置)
struct doublelist *q=p->next;
//删除结点--》中间位置的结点
p->prev->next=p->next;
p->next->prev=p->prev;
p->next=NULL;
p->prev=NULL;
free(p); //此时p变成了野指针
//更新p的位置
p=q;
}
else
p=p->next;
}
//经过仔细分析--》上面的循环漏掉了最后一个结点
//单独判断p指向最后一个结点这种情况
if(p->next==head && p->data==delnum)
{
p->prev->next=head;
head->prev=p->prev;
p->prev=NULL;
p->next=NULL;
free(p);
return 0;
}
return 0;
}
//打印
int list_print(struct doublelist *head)
{
struct doublelist *p=head;
while(p->next!=head)
{
p=p->next;
printf("当前遍历的结点中数据是:%d\n",p->data);
}
}
//链表的销毁
int list_destroy(struct doublelist *head)
{
struct doublelist *p;
//循环删除头结点后面的那个结点(紧挨着头结点的那个结点)
while(head->next!=head)
{
//更新p
p=head->next;
//由于最后一个结点删除代码跟中间位置结点写法不同
//单独判断最后一个结点
if(p->next==head) //说明此时p已经到了最后一个结点的位置
{
printf("删除最后一个结点%d\n",p->data);
p->prev->next=head;
head->prev=p->prev;
p->prev=NULL;
p->next=NULL;
return 0;
}
//说明p指向的是中间位置的结点
head->next=p->next;
p->next->prev=head;
p->next=NULL;
p->prev=NULL;
printf("删除中间位置的某个结点%d\n",p->data);
free(p); //p就是野指针
}
//循环结束的时候,头结点后面的所有结点都删除完毕
//单独释放头结点即可
free(head);
return 0;
}
int main()
{
//初始化双向循环链表
struct doublelist *myhead=list_init();
//尾插一些数据
list_insert_tail(myhead,18);
list_insert_tail(myhead,18);
list_insert_tail(myhead,38);
list_insert_tail(myhead,18);
list_insert_tail(myhead,18);
list_insert_tail(myhead,18);
list_insert_tail(myhead,18);
//中间插入
list_insert_mid(myhead,18,56);
//打印
list_print(myhead);
//删除重复的18
//list_remove(myhead,18);
//printf("==========删除之后============\n");
//list_print(myhead);
//销毁链表
list_destroy(myhead);
return 0;
}
内核链表
1.概念
内核链表是在linux系统的内核源码中使用得比较多的一种链表
内核链表的本质就是个双向循环链表
内核链表只能在linux系统中使用,其他系统不能使用(内核链表是linux内核专门设计出来存储内核中需要访问的数据)
2.特点
内核链表把指针操作封装好了,那么程序员就不用操心指针使用的问题(不需要画图了)
3.原理
用结构体表示内核链表
在linux系统的头文件中有定义一个结构体,该结构体专门用来存放指针域中的两个指针的
struct list_head //不是程序员自定义的,是系统中本来就有的
{
struct list_head *next, *prev;
};
struct 内核链表 //是我们程序员自定义的,用来存放真实的数据
{
//数据域 --》你需要存放的真实数据
//指针域 --》重点区分指针域跟普通双向循环链表写法的区别
struct list_head mypoint; //不要定义成指针
}
类似于如下写法
struct 内核链表 //是我们程序员自定义的,用来存放真实的数据
{
//数据域 --》你需要存放的真实数据
//指针域 --》重点区分指针域跟普通双向循环链表写法的区别
struct list_head *next;
struct list_head *prev;
}
内核链表把数据域和指针域做了分离
大结构体:指的就是你自定义的用来表示内核链表的那个结构体struct 内核链表
小结构体:指的就是struct list_head
4.对比普通的双向循环链表
区别一:普通双向循环链表,指针操作需要程序员自己画图去写,而且普通双向循环链表中的指针域也是自己定义的
内核链表指针操作不需要自己画图去写,指针域也是直接使用struct list_head来表示
区别二:普通双向循环链表中的next和prev指针是用来指向整个结点
内核链表的next和prev不是指向整个结点的,它们指向的是后面一个结点,或者前面一个结点中的(小结构体)struct list_head
5.内核链表提供的接口函数
(1)初始化指针域中的指针
INIT_LIST_HEAD(ptr) //带参数的宏定义
参数:ptr --》你要初始化的那个结点中的小结构体指针
(2)内核链表插入
void list_add_tail(struct list_head *new, struct list_head *head)
参数:把new代表的结点插入到head表示的内核链表的尾部
void list_add(struct list_head *new, struct list_head *head)
参数:把new代码的结点插入到head和第一个有效结点之间
(3)遍历内核链表
list_for_each_entry(pos, head, member) //本质是个for循环
参数:pos --》大结构体指针,用来遍历内核链表
head --》头结点中的小结构体指针
member --》小结构体在大结构体中的名字
(4)删除结点
void list_del(struct list_head *entry)
参数:entry --》你要删除的那个结点对应的小结构体指针
6.扩展知识点(能听懂更好)
内核链表我自己写循环去遍历,行不行??
struct kernellist *p=myhead;
while(p->next!=myhead) //错误,无法用大结构体指针去遍历内核链表
{ //正确,应该用小结构体指针去遍历内核链表
p=p->next;
printf("当前结点数据是:%d\n",p->data);
}正确的写法,用小结构体指针去遍历内核链表
struct list_head *q=&(myhead->mypoint);
while(q->next!=&(myhead->mypoint))
{
q=q->next;
printf("当前结点数据是:%d\n",代码写不出来); //我要通过小结构体得到对应的大结构体指针,才能写出代码
}
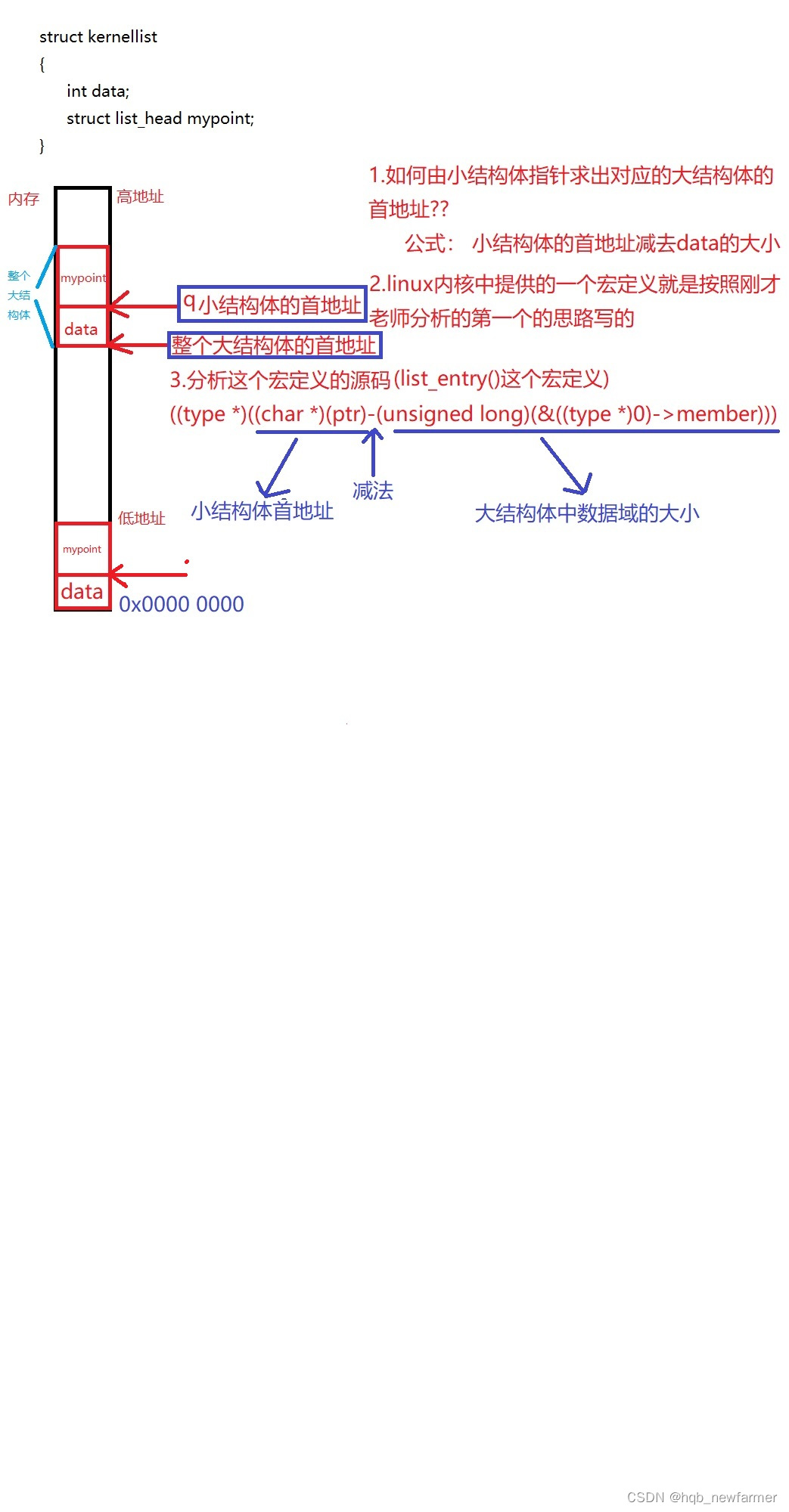
(1)linux内核提供的一个宏定义,作用是通过小结构体得到对应的大结构体的首地址
list_entry(ptr, type, member)
返回值:返回小结构体指针对应的大结构体
参数:ptr --》小结构体指针
type --》大结构体的数据类型
member --》小结构体在大结构体中的名字
这个宏定义的源码如下(很复杂):
((type *)((char *)(ptr)-(unsigned long)(&((type *)0)->member)))
简化: (char *)(ptr) --》把ptr强转成char*类型的指针,原因是指针的减法运算跟加法运算一样,加减的都是指针类型的大小
&((type *)0)->member --》等价于&((struct kernellist *)0)->mypoint 把一个大结构体保存到0地址上
(unsigned long) --》把刚才得到的0地址上的mypoint地址强转成整数
假如这么改写,会不会好理解一些
struct kernellist *test=0x00000000000;
&(test->mypoint)
内核链表的使用
#include "myhead.h"
#include "kernel_list.h" //内核链表的头文件
//定义一个结构体来表示内核链表
struct kernellist
{
//数据域 --》你想存放什么类型的数据,你就定义对应类型的变量即可
int data;
//指针域
struct list_head mypoint; //该结构体是系统头文件中已经定义好的,用来存放next和prev指针的
};
//内核链表初始化
struct kernellist *list_init()
{
struct kernellist *head=malloc(sizeof(struct kernellist));
//初始化指针域
INIT_LIST_HEAD(&(head->mypoint));
return head;
}
int main()
{
//初始化一个内核链表
struct kernellist *myhead=list_init();
//准备三个新的结点
struct kernellist *newnode1=malloc(sizeof(struct kernellist));
newnode1->data=18;
INIT_LIST_HEAD(&(newnode1->mypoint));
struct kernellist *newnode2=malloc(sizeof(struct kernellist));
newnode2->data=28;
INIT_LIST_HEAD(&(newnode2->mypoint));
struct kernellist *newnode3=malloc(sizeof(struct kernellist));
newnode3->data=38;
INIT_LIST_HEAD(&(newnode3->mypoint));
//尾插一些数据
//list_add_tail(newnode1,myhead); //经典错误
//list_add_tail(&(newnode1->mypoint),&(myhead->mypoint));
//list_add_tail(&(newnode2->mypoint),&(myhead->mypoint));
//list_add_tail(&(newnode3->mypoint),&(myhead->mypoint));
//把新结点插入到myhead和第一个有效结点之间
list_add(&(newnode1->mypoint),&(myhead->mypoint));
list_add(&(newnode2->mypoint),&(myhead->mypoint));
list_add(&(newnode3->mypoint),&(myhead->mypoint));
//删除结点
list_del(&(newnode2->mypoint));
//遍历内核链表
struct kernellist *p;
list_for_each_entry(p,&(myhead->mypoint),mypoint)
{
printf("当前我遍历的结点中的数据是:%d\n",p->data);
}
}
自己动手实现内核链表的遍历
#include "myhead.h"
#include "kernel_list.h" //内核链表的头文件
//定义一个结构体来表示内核链表
struct kernellist
{
//数据域 --》你想存放什么类型的数据,你就定义对应类型的变量即可
int data;
//指针域
struct list_head mypoint; //该结构体是系统头文件中已经定义好的,用来存放next和prev指针的
};
//内核链表初始化
struct kernellist *list_init()
{
struct kernellist *head=malloc(sizeof(struct kernellist));
//初始化指针域
INIT_LIST_HEAD(&(head->mypoint));
return head;
}
int main()
{
//初始化一个内核链表
struct kernellist *myhead=list_init();
//准备三个新的结点
struct kernellist *newnode1=malloc(sizeof(struct kernellist));
newnode1->data=18;
INIT_LIST_HEAD(&(newnode1->mypoint));
struct kernellist *newnode2=malloc(sizeof(struct kernellist));
newnode2->data=28;
INIT_LIST_HEAD(&(newnode2->mypoint));
struct kernellist *newnode3=malloc(sizeof(struct kernellist));
newnode3->data=38;
INIT_LIST_HEAD(&(newnode3->mypoint));
//尾插一些数据
//list_add_tail(newnode1,myhead); //经典错误
//list_add_tail(&(newnode1->mypoint),&(myhead->mypoint));
//list_add_tail(&(newnode2->mypoint),&(myhead->mypoint));
//list_add_tail(&(newnode3->mypoint),&(myhead->mypoint));
//把新结点插入到myhead和第一个有效结点之间
list_add(&(newnode1->mypoint),&(myhead->mypoint));
list_add(&(newnode2->mypoint),&(myhead->mypoint));
list_add(&(newnode3->mypoint),&(myhead->mypoint));
//删除结点
//list_del(&(newnode2->mypoint));
//遍历内核链表--》利用小结构体指针去遍历内核链表
struct list_head *p=&(myhead->mypoint);
while(p->next!=&(myhead->mypoint))
{
p=p->next;
//把小结构体指针转换成对应的大结构体指针
struct kernellist *bigp=list_entry(p,struct kernellist,mypoint);
printf("此时遍历的内核链表中的数据是:%d\n",bigp->data);
}
}


















 2213
2213

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











