




 本文详细阐述了字符集、字符编码的基本概念,并介绍了输入法与软件间的字符编码交互原理。进一步探讨了Oracle数据库如何处理字符集及全球化参数,包括不同层级参数的作用与设置方法。
本文详细阐述了字符集、字符编码的基本概念,并介绍了输入法与软件间的字符编码交互原理。进一步探讨了Oracle数据库如何处理字符集及全球化参数,包括不同层级参数的作用与设置方法。
1. 字符集、字符编码、输入法
关于字符集、字符编码的问题,其实我一直比较困惑,一知半解,脑子里一团浆糊,这次借助学习Oracle字符集,理一下思路。
字符这种类型的数据和其它类型的数据如音频、视频等等,本质上,都是存储在内存或磁盘上的二进制数据,关键是程序如何解释。
这个解释字符数据的协议,就是字符集或说字符编码了。
为了理解,需要先理清定义一些概念:
字符(Glyph):生活中语言的抽象符号,它是指图形,如“a”,“β”,“我”,“ひ”等,字符是对人类而言的概念。
字体:计算机上有一个字体的概念,是字符的不同图像风格,计算机软件会给每个字符编号,然后通过这个编号搜索图像库中对应的图像,用于显示这个字符。
字符与字体的区别:例如“我”字,对人来说只要字形写对了,不管是楷书还是隶书,是大是小,写得多烂都能认出,对人来说都是一个字符“我”,字体是具体的计算机图像,“我”字隶书的图像和楷书的图像是不同的,从字体概念讲是不同的字体,一个字符可能有多个字体。
字符集:给一种或多种语言的所有字符编号(codepoint,如1,2,3,4等等),所有这些字符和编号的对应关系,称为字符集,字符集的典型例子是UNICODE,GB2312,GBK。字符集中,与字符对应的这些编号,虽然也是数字,可以转成二进制存储到计算机,但是实际应用中,计算机不是直接的存储这些编号的二进制形式,而是要对这些编号再进行一次编码,称为“字符编码”。
字符编码:对于UNICODE这种字符集,包含了全世界所有语言的所有字符,有的字符用一个字节编号(实际占用少于8bit),有的字符用两个或三个字节编号(实际占用少于16bit或24bit),那么程序读取的时候,怎么知道从内存中提取几个字节解释为一个字符呢?为解决这个问题,就发明了字符编码,就是对前面所说的字符的编码再进行编码,第一个字节中特定的位设置特定的值,告诉程序这是那种字符集,程序从而知道要读取几个字节解释为一个字符。而UTF8就是一种为UNICODE字符集设计的字符编码方案。UTF8像一列火车,每8bit(一个字节)就是一节车厢,每节车厢用特殊的比特位,告诉程序这是一列UNICODE火车。用一节或六节车厢装载一个UNICODE字符编号所占用的bit,例如:
UTF-8是一种变长字节编码方式。如果字符集中某个字符的编号占一个字节(实际少于8bit),则这个编号的UTF-8编码,是二进制最高位为0的一个字节,其它位用来装载字符编码;如果是多字节,则其第一个字节,从最高bit位开始,连续的二进制位值1的个数,决定了其UTF-8编码的字节数,其余各字节均以10开头。UTF-8最多可用到6个字节。 如表:
低内存/磁盘地址 --------------------> 高内存/磁盘地址
1字节 0xxxxxxx
2字节 110xxxxx 10xxxxxx
3字节 1110xxxx 10xxxxxx 10xxxxxx
4字节 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
5字节 111110xx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx
6字节 1111110x 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx
对于GB2312和GBK(GBK是GB2312的扩展),字符集就是字符编码,它们每个字符固定用两个字节编号,每个字符的字符编码,就是它的编号。
还有ASCII、ANSI(ANSI是ASCII的扩展),字符集就是字符编码,它们每个字符用一个字节编号。
GB2312、GBK和UNICODE都是兼容ASCII的。
UTF8这列装载字符集的火车,也可以装其它字符集的数据,但是UTF8其实是专为装载UNICODE字符集设计的。
任何软件(如操作系统、文本编辑器、sqlplus,xshell等),只要是需要处理或显示字符,就一定有一个字符编码属性,表示以哪种字符编码解释它要处理的字符串数据。
当使用输入法输入中文或其它语言字符时,输入法中存储了人的输入(键盘按键的组合)与某种字符编码的映射,而接受输入的软件(如notepad++)也有自己的字符编码属性,要想获得正确的输入,两者的字符编码必须相同,输入时输入法应该已经与“接受输入的软件”协商过了,约定使用哪种字符编码,或者,输入字符在输入法中的字符编码值,会被转为“接受输入的软件”的字符编码”,只是这个过程用户并不了解。
例如,打开notepad++文本编辑器,设置的编码为GB2312,用输入法输入‘中‘,保存文件为gb2312.txt,
再打开notepad++,设置编码为UTF8,用同样的输入法输入‘中’,保存文件为utf8.txt
用hexdump查看,两个文件保存的字节值是不一样的,因为它们使用的字符集和字符编码都不同: 
当软件打开文本文件时,需事先知道文本的字符编码,这个信息可能包含在文本文件中,如UTF-8的BOM文件头,或软件事先设定。
以正确的字符编码解读文本是第一步,如果需要将文本在屏幕显示出来,计算机会根据字符编码,到字体库找到对应的字体图像,在软件的窗口中画出来。
2. Oracle对全球化的支持
1)Oracle在创建数据库时,指定了一些数据库级别的全球化参数,这些参数决定了默认情况下,数据库以何种语言显示提示和错误信息、日期和时间的格式、字符串排序的标准。下图是全数据库级别的全球化参数:
SYS@CDB> select * from nls_database_parameters;
PARAMETER VALUE
---------------------------------------- ----------------------------------------
NLS_RDBMS_VERSION 19.0.0.0.0
NLS_NCHAR_CONV_EXCP FALSE
NLS_LENGTH_SEMANTICS BYTE
NLS_COMP BINARY
NLS_DUAL_CURRENCY $
NLS_TIMESTAMP_TZ_FORMAT DD-MON-RR HH.MI.SSXFF AM TZR
NLS_TIME_TZ_FORMAT HH.MI.SSXFF AM TZR
NLS_TIMESTAMP_FORMAT DD-MON-RR HH.MI.SSXFF AM
NLS_TIME_FORMAT HH.MI.SSXFF AM
NLS_SORT BINARY
NLS_DATE_LANGUAGE AMERICAN
NLS_DATE_FORMAT DD-MON-RR
NLS_CALENDAR GREGORIAN
NLS_NUMERIC_CHARACTERS .,
NLS_NCHAR_CHARACTERSET AL16UTF16
NLS_CHARACTERSET AL32UTF8
NLS_ISO_CURRENCY AMERICA
NLS_CURRENCY $
NLS_TERRITORY AMERICA
NLS_LANGUAGE AMERICAN
其中 NLS_CHARACTERSET 和 NLS_NCHAR_CHARACTERSET 确立了数据库存储char、varchar2、nchar、nvarchar2的二进制格式(字符编码),数据库创建后就无法更改(其实是可以更改,不过新的字符编码必须是旧字符编码的父集,如果数据库已经有数据,这个更改就算是一种数据迁移,是较大的工作量了):
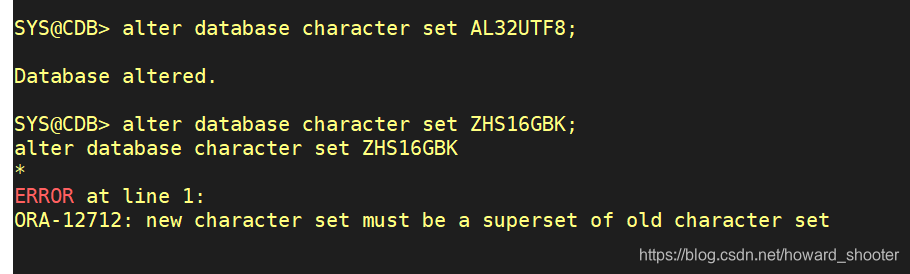
同样的NLS参数,有四个级别:数据库级别,实例级别,会话级别和语句级别,同样的参数,范畴从大到小是继承关系,小范畴继承大范畴,如果小范畴内设置了同样的参数就覆盖上一层次的参数值。
alter system set nls_language='AMERICAN' scope=spfile; 用来修改服务器端用来显示消息的语言,修改后需要服务器重启生效。
查看实例级别的NLS参数:
SYS@CDB> select * from nls_instance_parameters;
PARAMETER VALUE
---------------------------------------- ----------------------------------------
NLS_LANGUAGE ITALIAN
NLS_TERRITORY AMERICA
NLS_SORT
NLS_DATE_LANGUAGE
NLS_DATE_FORMAT
NLS_CURRENCY
NLS_NUMERIC_CHARACTERS
NLS_ISO_CURRENCY
NLS_CALENDAR
NLS_TIME_FORMAT
NLS_TIMESTAMP_FORMAT
NLS_TIME_TZ_FORMAT
NLS_TIMESTAMP_TZ_FORMAT
NLS_DUAL_CURRENCY
NLS_COMP BINARY
NLS_LENGTH_SEMANTICS BYTE
NLS_NCHAR_CONV_EXCP FALSE
在实际中,我们经常会修改会话或语句级别的NLS参数,如:
alter session set NLS_LANGUAGE="SIMPLIFIED CHINESE";
alter session set NLS_TERRITORY="JAPAN";
ALTER SESSION SET NLS_DATE_FORMAT = 'YYYY-MM-DD HH24:MI:SS';
查看会话级别的NLS参数:
SYS@CDB> select * from nls_session_parameters;
PARAMETER VALUE
---------------------------------------- ----------------------------------------
NLS_LANGUAGE SIMPLIFIED CHINESE
NLS_TERRITORY CHINA
NLS_CURRENCY ¥
NLS_ISO_CURRENCY CHINA
NLS_NUMERIC_CHARACTERS .,
NLS_CALENDAR GREGORIAN
NLS_DATE_FORMAT DD-MON-RR
NLS_DATE_LANGUAGE SIMPLIFIED CHINESE
NLS_SORT BINARY
NLS_TIME_FORMAT HH.MI.SSXFF AM
NLS_TIMESTAMP_FORMAT DD-MON-RR HH.MI.SSXFF AM
NLS_TIME_TZ_FORMAT HH.MI.SSXFF AM TZR
NLS_TIMESTAMP_TZ_FORMAT DD-MON-RR HH.MI.SSXFF AM TZR
NLS_DUAL_CURRENCY ¥
NLS_COMP BINARY
NLS_LENGTH_SEMANTICS BYTE
NLS_NCHAR_CONV_EXCP FALSE
查看会话中有效的NLS参数,包括了所有父层次的NLS参数的设置,如果本层次设置了,就按优先级覆盖。
SYS@CDB> select * from v$nls_parameters;
PARAMETER VALUE CON_ID
---------------------------------------- ---------------------------------------- ----------
NLS_LANGUAGE SIMPLIFIED CHINESE 3
NLS_TERRITORY CHINA 3
NLS_CURRENCY ¥ 3
NLS_ISO_CURRENCY CHINA 3
NLS_NUMERIC_CHARACTERS ., 3
NLS_CALENDAR GREGORIAN 3
NLS_DATE_FORMAT DD-MON-RR 3
NLS_DATE_LANGUAGE SIMPLIFIED CHINESE 3
NLS_CHARACTERSET AL32UTF8 3
NLS_SORT BINARY 3
NLS_TIME_FORMAT HH.MI.SSXFF AM 3
NLS_TIMESTAMP_FORMAT DD-MON-RR HH.MI.SSXFF AM 3
NLS_TIME_TZ_FORMAT HH.MI.SSXFF AM TZR 3
NLS_TIMESTAMP_TZ_FORMAT DD-MON-RR HH.MI.SSXFF AM TZR 3
NLS_DUAL_CURRENCY ¥ 3
NLS_NCHAR_CHARACTERSET AL16UTF16 3
NLS_COMP BINARY 3
NLS_LENGTH_SEMANTICS BYTE 3
NLS_NCHAR_CONV_EXCP FALSE 3
3. 客户端的字符编码与服务器端的字符编码
Oracle的客户端sqlpus也有字符编码属性,由客户端环境变量NLS_LANG控制,它除了决定字符编码,还决定语言和地域属性,下面绿色部分表示语言,紫色部分表示地域,红色部分表示字符编码:
export NLS_LANG=AMERICAN_AMERICA.AL32UTF8
export NLS_LANG=AMERICAN_AMERICA.ZHS16GBK
export NLS_LANG="SIMPLIFIED CHINESE"_CHINA.ZHS16GBK
export NLS_LANG="SIMPLIFIED CHINESE"_CHINA.AL32UTF8
语言属性,决定了提示和错误使用的语言,地域决定了日期格式,不过最重要的还是字符编码,如何客户端和服务器的字符编码属性不同,Oracle服务端会做映射转换。
由于有事Oracle中不存在两种字符编码的映射表,没法转换,会带来很多麻烦或困惑。
要求最好Oracle客户端和服务端的语言、地域、字符编码属性相同。
需要注意:
当我使用终端软件如xshell,连接到Linux服务器,登录到sqlplus的命令行,准备输入命令时,输入法是和xshell交互,不是和sqlplus交互。
如果xshell设置为GBK,那么xshell发给sqlplus的字符串,比如说"我",是以GBK编码的,无论sqlplus的编码设为什么。
如果NLS_LANG为ZHS16GBK,就认为发来的是GBK字符串,如果如果NLS_LANG为AL32UTF8,就认为发来的是UTF8字符串。
当sqlplus与Oracle服务端的字符编码相同时:sqlplus传给服务端的SQL,直接被服务器端解析存储,没有字符集映射转换的过程。
当sqlplus与Oracle数据库的字符编码不同时:服务器收到SQL后会对字符编码做转换:
假如sqlplus的编码是GBK,而Oracle数据库的编码是UTF8,sqlplus传给数据库一个 以GBK编码的'中' 字,值为D6D0,数据库收到D6D0后,根据客户端编码为GBK,将D6D0转为’中‘在UTF8中的编码E4B8AD,然后再存储。
下面用sqlplus做一个实验:
将xshell的编码设为GBK,sqlplus设为export NLS_LANG=AMERICAN_AMERICA.ZHS16GBK,Oracle服务端字符编码为UTF8,连接数据库执行:
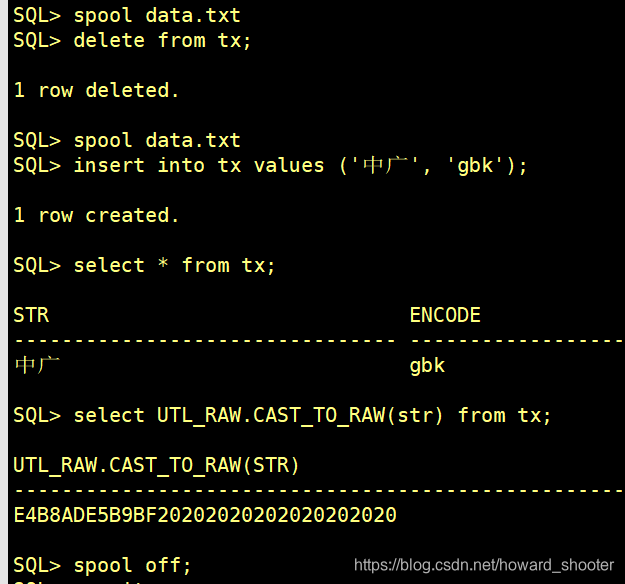
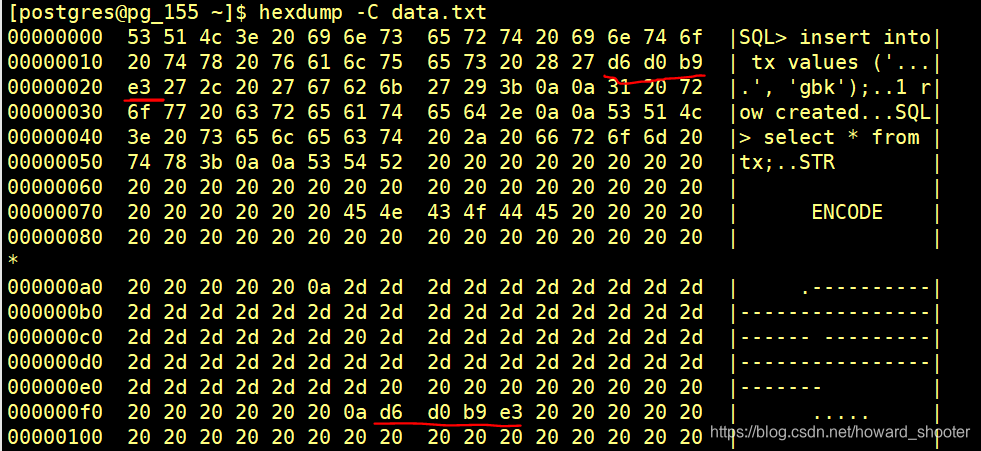
可以看到,尽管输入的’中广‘两个字是值为D6D0B9E3的GBK编码,但存储到Oracle里的RAW数据,’中广‘两个字是Unicode-UTF8编码的E4B8ADE5B9BF。只有一个可能,就是对同一个字符,Oracle数据库存储时对GBK字符集和Unicode-utf8字符集做了映射转换。
不过,为了减少出现未知问题的可能,我们是要求:终端(xshell)、sqlplus、Oracle数据库三者的字符编码是相同的。
在Oracle中不能单独设置表或字段的字符集/字符编码,所有char、varchar2、clob都使用NLS_CHARACTERSET,所有nchar、nvarchar2、nclob都使用NLS_NCHAR_CHARACTERSET。
软件间需要交换文本数据时,例如数据库之间的迁移,要注意:
- 文本字段的字符编码是否相同
- 数据库是否自动地做了同一个字符不同字符集之间的映射
不同数据库之间迁移,就是看它们的字符编码是否相同,如果都相同,就可以从一个数据库读出二进制数据,直接写入另一个数据库,如果不同,就需要转换。
4.PL/SQL Developer 导出的SQL文件,在另一个Oracle上导入后,中文乱码
迁移数据时遇到这种情况,是因为我用sqlplus导入,导入时没有设置Linux环境变量NLS_LANG,这个环境变量应设置为:
NLS_LANGUAGE_NLS_TERRITORY.NLS_CHARACTERSET,
其中NLS_LANGUAGE、NLS_TERRITORY、NLS_CHARACTERSET对应数据库中的设置,例如
export NLS_LANG=AMERICAN_AMERICA.ZHS16GBK
参考:
字符编码查看与转换的网址:
汉字字符集编码查询;中文字符集编码:GB2312、BIG5、GBK、GB18030、Unicode
gb2323 -- gbk -- gb18030 :GB2312、GBK、GB18030 这几种字符集的主要区别是什么? - 知乎


















 632
632



 到【灌水乐园】发言
到【灌水乐园】发言







