



------在学习c语言,本篇主要为大家讲解:
一、结构体

C语言中的结构体(struct)与数组一样,是一种复合数据类型,不过数组是相同类型元素的集合而结构体的元素类型可以不同,它允许你将多个不同或相同类型的变量组合成一个单一的类型。结构体通常用于表示复杂的数据结构,例如学生信息、书籍信息等。
1.结构体的定义与使用
首先结构体的使用需要对其进行定义
格式如下:
struct 结构体名 {
类型 成员变量名;
类型 成员变量名;
...
};
那么,如何使用我们定义过的结构体呢?
--》1.“.”操作符意为访问某一个(结构体)
stu3.name = "DH";
stu3.age = 200;
stu3.score = 100;
数组的成员可以有很多种:标量,数组,指针,甚至其他结构体
2.结构体数组
结构体数组是将相同类型的结构体变量组合在一起的一种方式。这在处理需要存储多个相同类型对象的场景中非常有用,比如一个班级中多个学生的信息
#include <stdio.h>
#include <string.h>
// 定义一个结构体类型 Student
struct Student {
char name[50];
int age;
float score;
};
int main() {
// 创建一个结构体数组,包含3个学生的信息
struct Student students[3];
// 给结构体数组的每个元素赋值
strcpy(students[0].name, "张三");
students[0].age = 20;
students[0].score = 95.5;
strcpy(students[1].name, "李四");
students[1].age = 22;
students[1].score = 88.0;
strcpy(students[2].name, "王五");
students[2].age = 19;
students[2].score = 92.5;
// 遍历结构体数组并打印每个学生的信息
for (int i = 0; i < 3; i++) {
printf("学生 %d:\n", i + 1);
printf("姓名: %s\n", students[i].name);
printf("年龄: %d\n", students[i].age);
printf("分数: %.2f\n", students[i].score);
}
return 0;
}
结果为: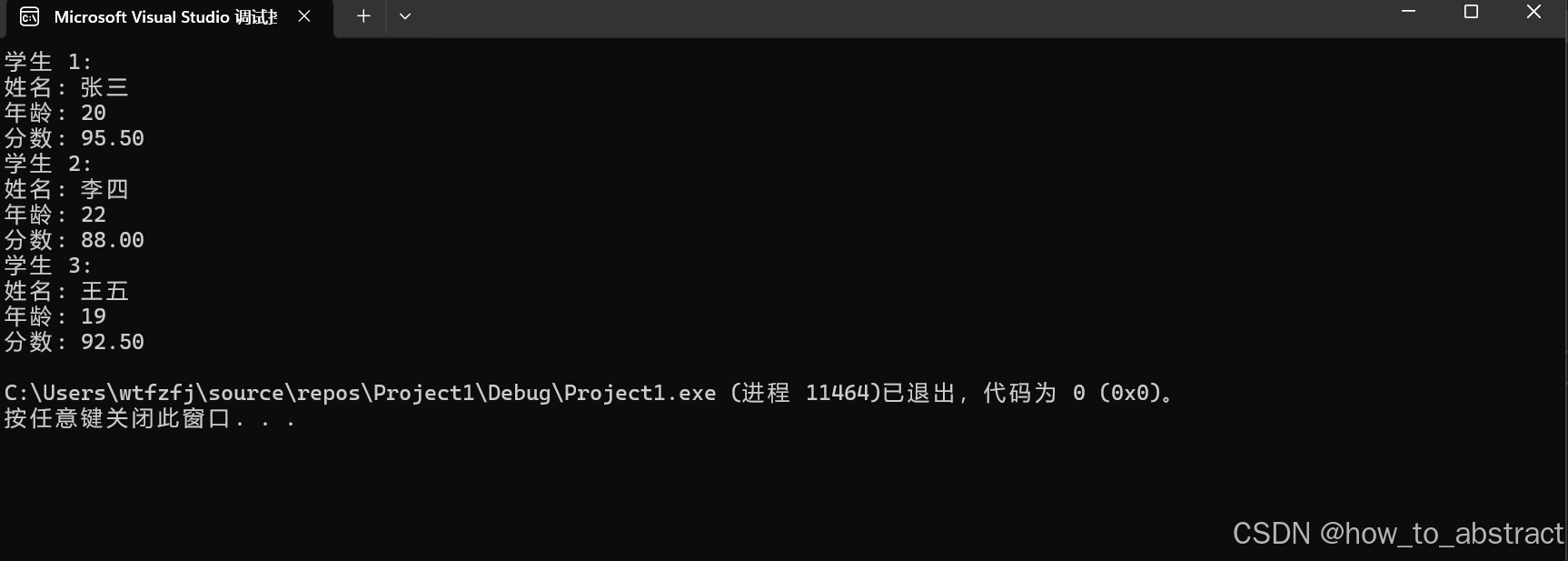
struct Student:定义了一个名为Student的结构体类型,包含三个成员:name(字符数组,用于存储名字),age(整数,用于存储年龄),score(浮点数,用于存储分数)struct Student students[3];:声明一个名为students的数组,它可以存储3个Student类型的结构体。
数组的非字符数组类型可以直接可以=赋值
字符类型则需要strcpy将其赋进去
strcpy:

有点抽象[doge],我们画图理解一下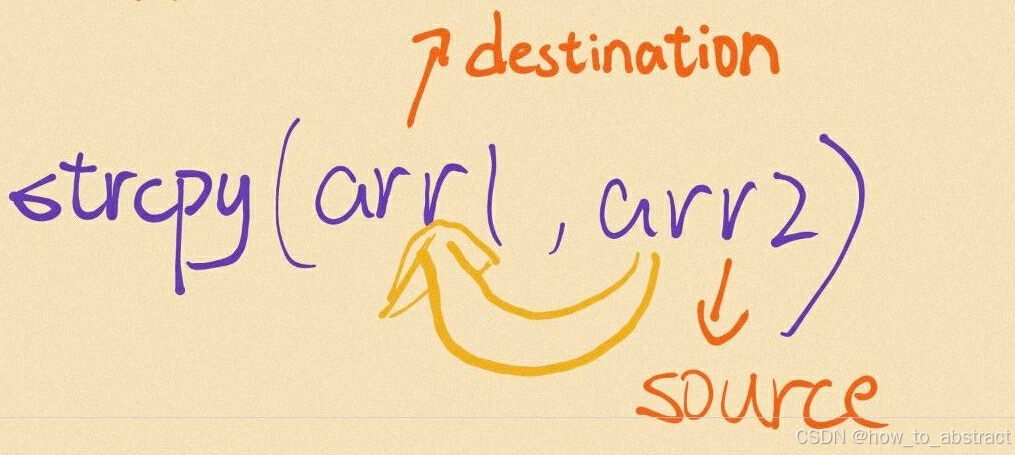
即为将arr2的元素覆盖到arr1中,注意,是覆盖
另提一嘴,上面提到遍历这一词,通常指的是按照一定的顺序访问数组、链表或其他集合中的每个元素。对于结构体数组,我们通常使用循环结构(如for循环、while循环或do-while循环)来遍历数组中的每个元素
3.结构体指针
可以通过指针访问结构体中的成员
格式:
struct 结构体名 *指针变量名;
struct Student stu;
struct Student *ptr = &stu; // ptr指向stu的地址
这里只是访问了这个结构体,那么,如何访问结构体中的元素呢?
(*ptr).name = "DH";
有点麻烦,我们还有"->"箭头操作符直接访问其成员 eg:
ptr->name = "DH"
下面,我通过一段实例来帮助大家熟悉(仔细看注释)
#include <stdio.h>
#include <string.h>
struct Student {
char name[50];
int age;
float score;
};
int main() {
struct Student stu = {"张三", 20, 95.5}; // 定义并初始化一个结构体变量
struct Student *ptr = &stu; // 定义一个指向结构体的指针,并让它指向stu的地址
// 使用结构体指针访问成员
ptr->age = 21; // 等同于 (*ptr).age = 21
strcpy(ptr->name, "李四"); // 使用strcpy函数修改name成员
// 打印结构体成员的信息
printf("姓名: %s\n", ptr->name); // 使用结构体指针访问name成员
printf("年龄: %d\n", ptr->age); // 使用结构体指针访问age成员
printf("分数: %.2f\n", ptr->score); // 使用结构体指针访问score成员
return 0;
}
结构体指针给出了一种更加灵活的方式去操作和传递复杂的数据结构,特别是一些大型的结构体
使用指针还可以在堆上动态分配结构体,这允许在运行时决定需要多少个结构体实例,以及在不再需要时释放内存。
4.结构体嵌套结构体
结构体嵌套结构体是指一个结构体作为另一个结构体的成员。这种嵌套结构体非常有用,可以创建复杂的数据结构,以模拟现实世界中的实体及其关系。
例如,我们可能需要在结构中存储实体员工的地址。而地址也可以包含其他信息,例如街道编号,城市,地区和密码。因此,要存储员工的地址,我们需要将员工的地址存储到一个单独的结构中,并将该结构的地址嵌套到该结构的员工中。
#include <stdio.h>
#include <string.h>
// 定义一个结构体表示地址信息
typedef struct {
char street[50];
char city[30];
char state[30];
char zipCode[10];
} Address;
// 定义一个结构体表示员工信息,其中包含一个地址结构体作为成员
typedef struct {
char name[50];
int age;
float salary;
Address address; // 嵌套的地址结构体
} Employee;
int main() {
// 创建一个员工结构体实例并初始化
Employee emp = {
"John Doe",
30,
50000.0,
{"123 Main St", "Anytown", "CA", "12345"} // 初始化嵌套的地址结构体
};
// 访问嵌套的地址结构体的成员
printf("Employee Name: %s\n", emp.name);
printf("Employee Age: %d\n", emp.age);
printf("Employee Salary: %.2f\n", emp.salary);
printf("Employee Address:\n");
printf("\tStreet: %s\n", emp.address.street);
printf("\tCity: %s\n", emp.address.city);
printf("\tState: %s\n", emp.address.state);
printf("\tZip Code: %s\n", emp.address.zipCode);
return 0;
}
上述代码用到了typedef关键字
它可以帮助我们简化使用结构体的过程,如上:使用typedef简化复杂类型后我们只需要输入Employee就可以替代struct Employee这个复杂的结构体,增加了代码的可读性,赶紧用起来!
5.结构体充当函数参数
这里可分为:传值调用和传址调用
顾名思义:一个传递的是结构体中元素的值,一个传递的是结构体中元素的地址
那么它们都有什么区别呢?
如果不想修改主函数中的数据,用值传递,反之用地址传递
以之前写过的swap函数举例
void swap(int a,int b)
{int temp;
temp=a;
a=b;
b=temp;
}
这样由于实参的地址未改变,而形参在函数结束时生命周期就已经结束,所以就达不到交换两个元素的目的,我们可以通过运用指针将实参的地址传进去
eg:
void swap(int *a, int *b) {
int temp = *a;
*a = *b;
*b = temp;
}
此外,因为函数传参是参数压栈,直接传值会导致性能不佳
(压栈我们在下一节内存中进行介绍)
二、数据的存储
1.数据类型介绍(其实已近在之前的笔记中讲过了[doge])
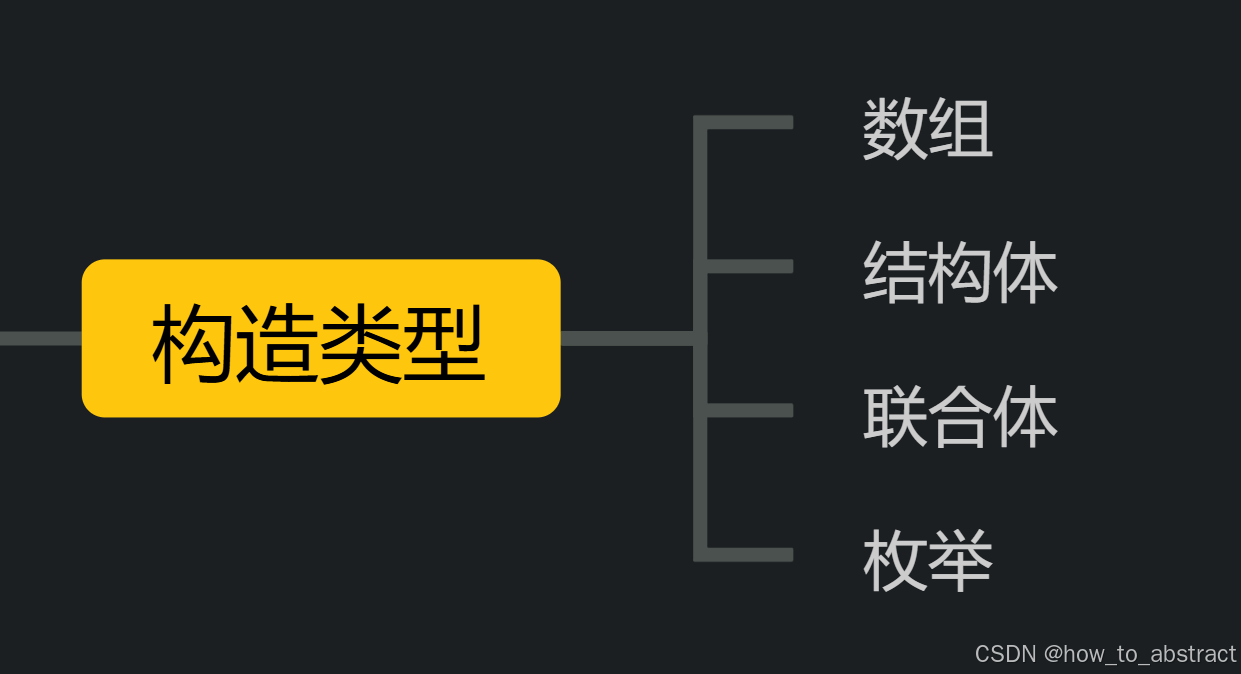
数据类型主要分为内置类型和构造类型,其中内置类型分为整型和浮点型,构造类型分为数组类型、结构体类型、枚举类型、指针类型和空类型。
signed -- 有符号类型(当未标明为无符号类型时,默认为有符号类型)
unsigned -- 无符号类型
unsigned 在 C 语言中是一个关键字,用来指定一个变量其值域为非负数。使用 unsigned 可以确保变量只能取正值(包括零)。
整形家族:
char (占1个字节,字符的本质是ASCII码值,是整形,)
signed char
char 是signed char还是unsigned char,C语言标准是未定义的,取决于编译器的实现。
short (占2个字节)
unsigned short [int]
signed short [int]–>short
int (占4个字节)
unsigned int
signed int–>int
long (占4/8个字节,在32位的平台上是4个字节,在64位平台上是8个字节)
unsigned long [int]
signed long [int]–>long
浮点数家族:
float (占4个字节)
double (占8个字节)
构造类型:
数组类型
注意:int arr[10]的类型是去掉数组名的那一部分,即:int [10]
结构体类型 struct
枚举类型 enum
联合类型 union
指针类型:
*name
空类型:
void表示空类型(无类型)
通常应用于函数的返回类型、函数的参数、指针类型。
例如下面的函数:
/第一个void 表示函数不会返回值
/第二个void 表示函数不需要传任何参数
void test(void)
{
}
2.整型在内存中的存储
在计算机中,整数(整形)的存储涉及到二进制表示和字节序(大端或小端)。
在计算机用机器数的最高位存放符号,正数为0,负数为1。
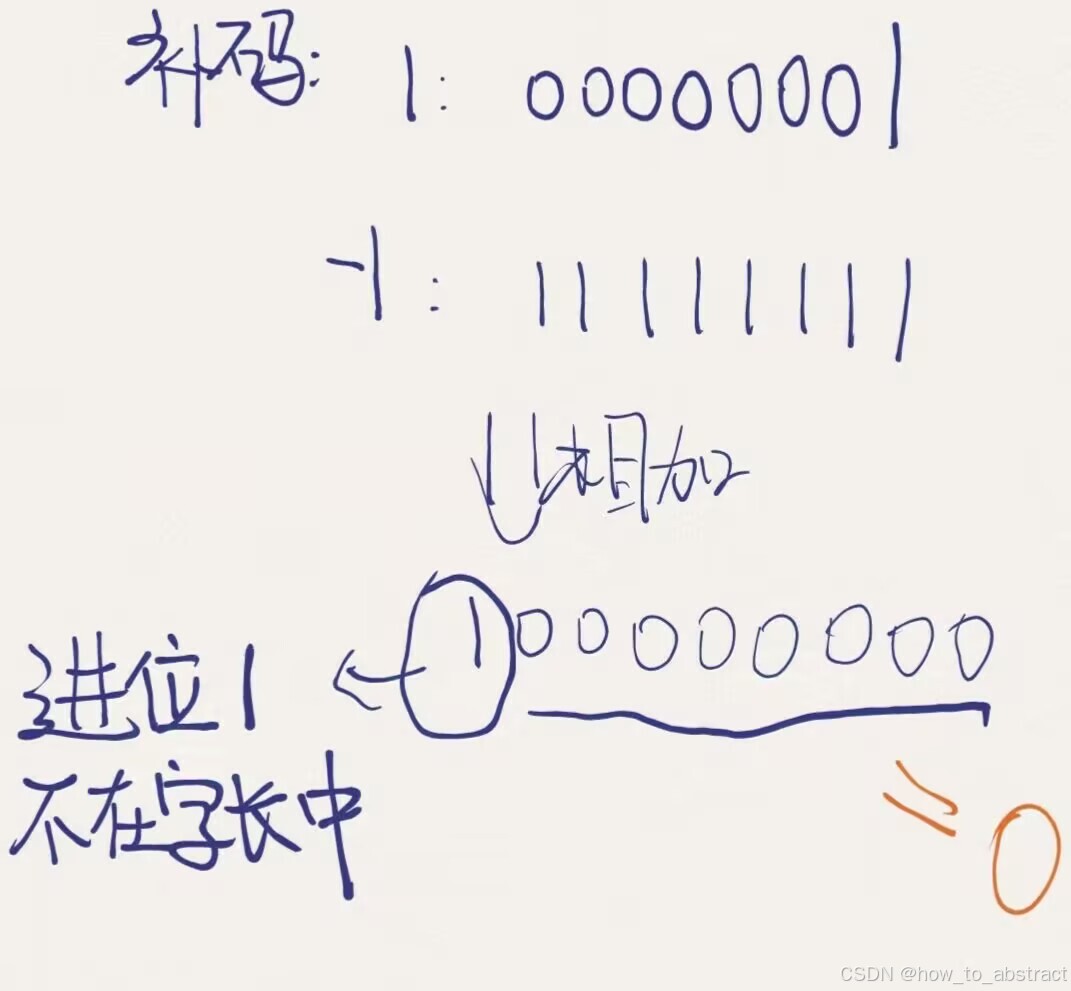
十进制中的数 +3 ,计算机字长为8位,转换成二进制就是0000 0011。如果是 -3 ,就是 100 00011 。
那么,这里的 0000 0011 和 1000 0011 就是机器数。也就是它的原码
原码是人脑最容易理解和计算的表示方式。
正数的原码,反码,补码都是它本身,而负数的反码和补码都需要自己计算
反码:
负数的反码是在其原码的基础上,符号位不变,其余各个位取反。
[+1] = [0000 0001]原= [0000 0001]反
[-1] = [1000 0001]原= [1111 1110]反
补码:
负数的补码是在其原码的基础上,符号位不变,其余各位取反,最后+1。(也即在反码的基础上+1)
[+1] = [0000 0001]原= [0000 0001]反= [0000 0001]补
[-1] = [1000 0001]原= [1111 1110]反= [1111 1111]补
我们为啥要学习原反补??
因为计算机是没有减法器的,我们想实现减法只能用加法来实现
eg:若我们想实现1-1=0:


大端字节序
在大端字节序中,一个多字节值的最高有效字节(MSB)存储在最低的内存地址处,而最低有效字节(LSB)存储在最高的内存地址处。换句话说,大端字节序将最重要的字节放在前面。
示例: 假设有一个16位的二进制数 0x1234:
- 在大端字节序中,内存布局如下:
其中地址 数据 0x00 0x12 0x01 0x340x12是最高有效字节,0x34是最低有效字节。
小端字节序
在小端字节序中,一个多字节值的最低有效字节(LSB)存储在最低的内存地址处,而最高有效字节(MSB)存储在最高的内存地址处。换句话说,小端字节序将最不重要的字节放在前面。
示例: 假设同一个16位的二进制数 0x1234:
在小端字节序中,内存布局如下:
地址 数据
0x00 0x34
0x01 0x12
其中 0x34 是最低有效字节,0x12 是最高有效字节。
3.浮点型在内存中的存储
任意一个二进制浮点数V可以表示成下面的形式: NUM = (-1) ^ s * M * 2 ^ E
- (-1)^S表示符号位,当S=0,V为正数;当S=1,V为负数。
- M表示有效数字,大于等于1,小于2。
- 2^E表示偏移的指数位。
很抽象是不是,我们可以看图进一步了解:

- 符号位:1位,表示数值的正负,0表示正数,1表示负数。
- 指数位:8位,用于表示数值的范围。实际存储的指数值需要加上一个偏移量(127),以得到实际的指数值。
- 尾数位:23位,表示数值的精度。这23位实际上表示的是1.M...的形式,其中M是尾数的二进制表示,省略了最前面的1(因为在二进制中,尾数总是以1开始的,所以这个1是隐含的)。
这种存储方式允许浮点数在计算机中高效地存储和计算,但也有一些限制,比如精度损失和不能表示所有的实数(比如某些分数)
三、构造类型(补充)
在前面的学习中,我们学习了数组,结构体这样的可以自己创造的数据类型,接着,我们继续介绍剩余的联合体和共用体
1.联合体(union)
声明格式如下:
union [union名] {
成员1类型 成员1名;
成员2类型 成员2名;
...
成员n类型 成员n名;
} 联合变量名;
联合体与结构体有许多相似之处:联合体(union)和结构体(struct)同样可以包含很多种数据类型和变量。但区别也很明显:
-
内存占用:
- 联合体:所有成员共享同一块内存空间。因此,联合体的大小等于其最大成员的大小。
- 结构体:每个成员都有自己的内存空间。结构体的大小是所有成员大小的总和,通常会有填充(padding)以满足对齐要求
-
成员访问:
- 联合体:成员可以被访问,但同时只能有一个成员被有效使用。
- 结构体:所有成员都可以被独立访问,并且可以同时使用.
- 3.使用场景:联合体:适用于需要节省空间或处理不同数据类型但在同一时间只需要一种类型的场景。
- 结构体:适用于需要将多个相关数据项组合在一起,并且每个数据项都需要独立存储的场景。
联合体在内存占用空间的计算:
#include<stdio.h>
union sizeTest{
int a;
double b;
};
main(){
union sizeTest unionA;
union sizeTest unionB;
union sizeTest unionC;
printf("the initial address of unionA is %p\n",&unionA);
printf("the initial address of unionB is %p\n",&unionB);
printf("the initial address of unionC is %p\n",&unionC);
}
输出结果为:
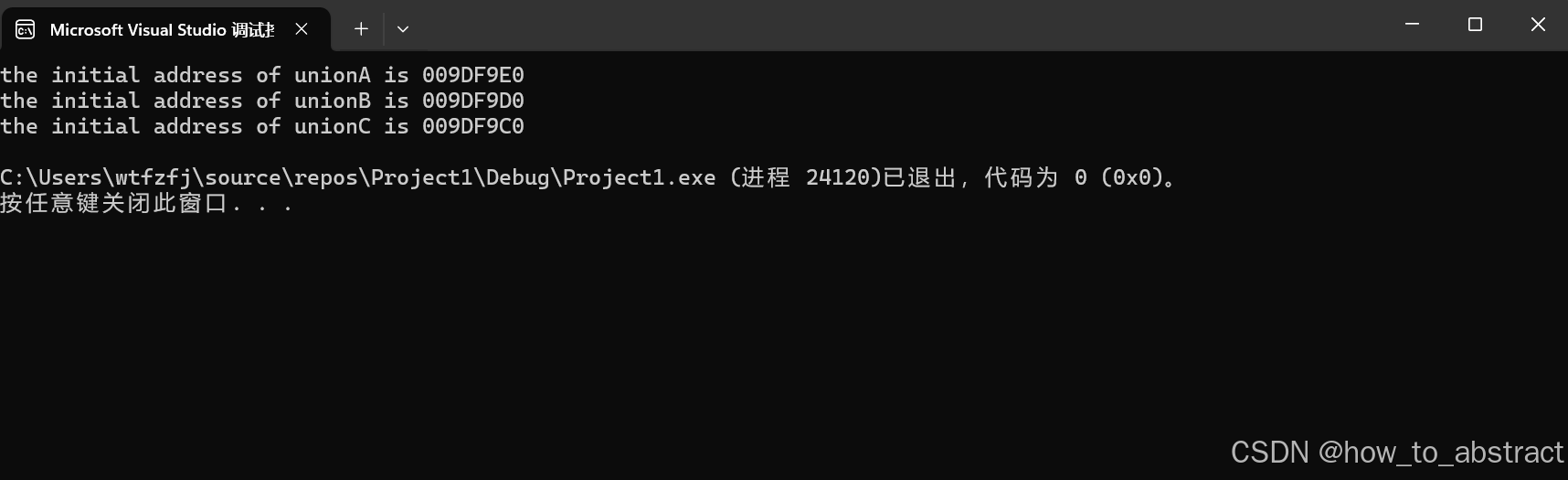
联合体所占的空间并非struct结构体的简单相加,它遵守以下几个规则:
-
最大成员大小:联合体的大小至少与其最大的成员的大小一样大。
-
内存对齐:编译器可能会要求联合体的总大小必须是某个特定数(通常是2、4或8字节)的倍数,这称为“对齐”。这意味着即使最大的成员不需要这么多空间,联合体的大小也可能因为对齐要求而增加。
-
填充:如果成员的大小不是对齐单位的倍数,编译器可能会在成员之间或联合体的末尾添加填充字节,以确保联合体的大小满足对齐要求。
-
未使用的空间:由于联合体在同一时间只能使用一个成员,所以其他成员所占用的空间在任何时候都是未使用的。
2.枚举类型(enum)
枚举允许你为一组整数值赋予有意义的名称。枚举类型通过enum关键字定义,可以提高代码的可读性和可维护性。
格式如下:
enum 枚举名 {
枚举值1,
枚举值2,
...
枚举值n
};
#include <stdio.h>
// 定义枚举类型
enum Weekday {
Sunday,
Monday,
Tuesday,
Wednesday,
Thursday,
Friday,
Saturday
};
int main() {
// 声明枚举变量
enum Weekday today;
// 给变量赋值
today = Tuesday;
// 打印结果
printf("Today is %d: %s\n", today, today == Tuesday ? "Tuesday" : "Other day");
return 0;
}
上述定义了一个枚举类型Weekday
默认每一个元素对应的数字是由0开始的,当然你也可以修改其对应数字(在这之后的元素从这开始计数)
#include <stdio.h>
// 定义枚举类型并显式指定值
enum Weekday {
Sunday = 1, // 将Sunday的值设置为1
Monday = 2, // 将Monday的值设置为2
Tuesday = 3, // 将Tuesday的值设置为3
Wednesday = 4,// 将Wednesday的值设置为4
Thursday = 5, // 将Thursday的值设置为5
Friday = 6, // 将Friday的值设置为6
Saturday = 7 // 将Saturday的值设置为7
};
int main() {
// 声明枚举变量
enum Weekday today;
// 给变量赋值
today = Tuesday;
// 打印结果
printf("Today is %d: %s\n", today, today == 3 ? "Tuesday" : "Other day");
return 0;
}
在这个例子中,我们为enum Weekday中的每个元素显式地指定了整数值。这样,Sunday的值为1,Monday的值为2,依此类推,直到Saturday的值为7。
枚举的作用:
提高代码可读性:使用枚举可以提高代码的可读性和可维护性。通过为常量赋予有意义的名称,可以使代码更加清晰和易于理解。枚举常量是预定义的,只能从枚举类型中选择,这样可以避免使用不相关的或无效的值。
限定取值范围:枚举可以限定变量或参数的取值范围。通过使用枚举类型,可以确保变量只能赋值为枚举常量中的一个,从而减少错误和不一致性。这对于需要特定选项或状态的场景非常有用。
提供类型安全检查:枚举类型是静态类型,在编译时进行类型检查。这意味着在使用枚举常量时,编译器可以检查是否使用了正确的类型和值,从而减少一些常见的编程错误。
增加可扩展性:枚举可以很容易地扩展和添加新的常量。当需要增加新的选项或状态时,只需在枚举定义中添加新的常量即可,而不需要修改现有的代码。
这一篇笔记到这就结束了,下一篇主要是讲C语言算法以及刷题心得

















 1209
1209

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









