







 本文探讨了bias和variance的权衡,强调在模型选择中找到训练误差和测试误差的最佳平衡至关重要。通过联想记忆,将欠拟合(高偏差)与过拟合(高方差)形象化。引用文献指出随机森林通过增加偏差降低方差,而集成学习如bagging和boosting分别针对过拟合和欠拟合提供解决方案。
本文探讨了bias和variance的权衡,强调在模型选择中找到训练误差和测试误差的最佳平衡至关重要。通过联想记忆,将欠拟合(高偏差)与过拟合(高方差)形象化。引用文献指出随机森林通过增加偏差降低方差,而集成学习如bagging和boosting分别针对过拟合和欠拟合提供解决方案。
Bias and variance tradeoff is everywhere
- 文献中bias和varience常常出现,为了混淆,特别做一次对比,帮助记忆。
- 核心是有切当的模型复杂度,使得训练误差和测试误差得到最佳平衡,换一个说法就是欠拟合和过拟合的平衡到处都需要考虑。
联想记忆
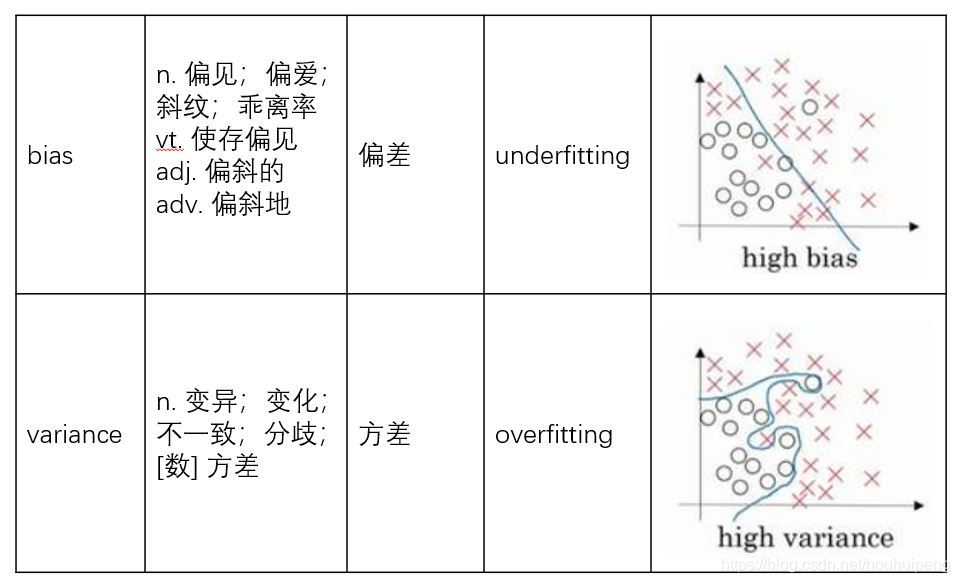
- bias短,对应下图的直线长度也短,就是欠拟合,也就是偏差太高。
- variance长,对应下图的曲线长度特别长,就是过拟合,也就是方差太高。
引用文献中的一句话:
Random Forests results in a greater tree diversity ,which trades a
higher bias for a lower variance than DecisionTree, generally yielding
an overall better model.
意思就是指,相比于决策树,随机森林用提升了偏差的代价,降低了方差,减少了过拟合(决策树的缺陷之一)。
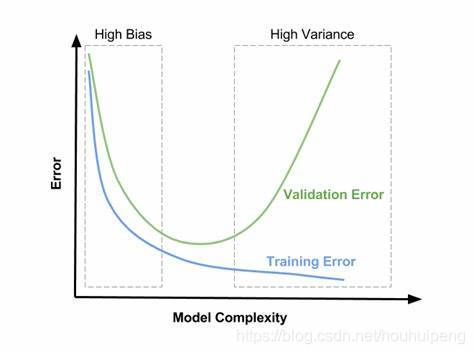
多看几个图,帮助理解记忆:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1187
1187

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









