






现有8G的数据,其中都是无符号的int型,现有1G内存,如何对这些数据排序。
答:
首先建立一个struct将数据包起来,结构体包含数据的值及它出现的次数。需要建立一个大根堆,每个大根堆的一个数据项是这个结构体,且此结构体<数据占4字节,词频占8字节>,所以大概可以建8千万个数的大根堆,但是还需要建立一个表<数据占4字节,词频占8字节>,其中存储已经在大根堆中的数,方便二次遍历计算词频,所以大概可以建立包含K个数的大根堆。
然后开始遍历文件中的数据,每次遇到新的数字就假加入表中,及大根堆中(如遇到相同的,即表中已有的数,则跳过)。一直遍历到将大根堆填满为止,然后接下来每次遍历的数据就与大根堆堆顶进行比较,如果其大于堆顶,则跳过不管(因为要先找到前K个最小种类的数,说明这个数一定不在这个范围内,因为它大于了这个堆里的所有数),如果遇到的数x小于堆顶数y,则将堆顶y取出,表中的堆顶y也取出,将x加入大根堆后,重新维持大根堆,x也加入表中。就这样遍历完所有数后,大根堆中就存储了所有数前K个最小的种类的数(但是每个种类可能有相同的数),然后再根据表重新遍历一次原数据,在原来的哈希表中得到大根堆中每个数的词频,然后再将此词频更新到大根堆中。
可能会得到如下结果
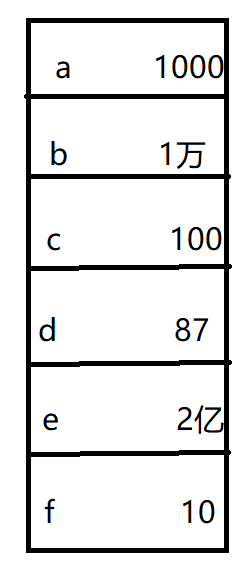
将这些数据按大根堆排序后输出到一个文件里,接下来记住这个堆里的最大值max = a;然后清空堆和哈希表,重新遍历原数据,遇到小于等于a的直接跳过,然后重新维持一个大根堆和哈希表,找到接下来K个种类最小的数,排序后输出到另一个文件中。直到最后生成了多个文件,将文件连接在一起就排序完成了。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









