




准备数据集及加载,ImageFolder
在很多机器学习或者深度学习的任务中,往往我们要提供自己的图片。也就是说我们的数据集不是预先处理好的,像mnist,cifar10等它已经给你处理好了,更多的是原始的图片。比如我们以猫狗分类为例。在data文件下,有两个分别为train和val的文件夹。然后train下是cat和dog两个文件夹,里面存的是自己的图片数据,val文件夹同train。这样我们的数据集就准备好了。
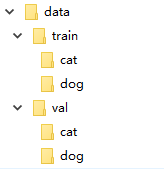
ImageFolder能够以目录名作为标签来对数据集做划分,下面是pytorch中文文档中关于ImageFolder的介绍:

#对训练集做一个变换
train_transforms = transforms.Compose([
transforms.RandomResizedCrop(224), #对图片尺寸做一个缩放切割
transforms.RandomHorizontalFlip(), #水平翻转
transforms.ToTensor(), #转化为张量
transforms.Normalize((.5, .5, .5), (.5, .5, .5)) #进行归一化
])
#对测试集做变换
val_transforms = transforms.Compose([
transforms.Resize(256),
transforms.RandomResizedCrop(224),
transforms.ToTensor(),
transforms.Normalize((.5, .5, .5), (.5, .5, .5))
])
tr 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3172
3172

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









