







 本文介绍Hadoop日志的查看与管理方法,并详细解释如何配置Jobhistory以实现日志聚合,包括修改配置文件及启动相关服务的过程。
本文介绍Hadoop日志的查看与管理方法,并详细解释如何配置Jobhistory以实现日志聚合,包括修改配置文件及启动相关服务的过程。
(一)日志详解
进入hadoop这个目录下查看日志 (开启两个命令窗口)
#cd logs/#ls //查看
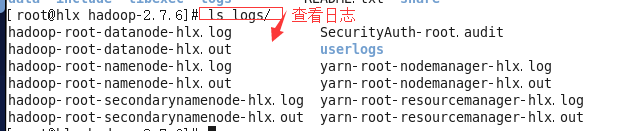
#ls

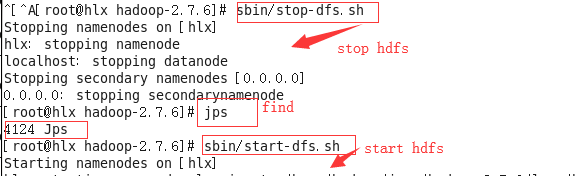
#sbin/start-dfs.sh //启动dfs
#ls //再查看日志

说明:hadoop是框架名; root用户名; datanode进程名; hadoop.log 日志后缀名;

#more hadoop-root-datanode-hadoop.log // 一行一行的查看,按Enter

#tail -f hadoop-root-datanode-hadoop.log //滚动的方式查看

写as,按Enter

#sbin/stop-dfs.sh
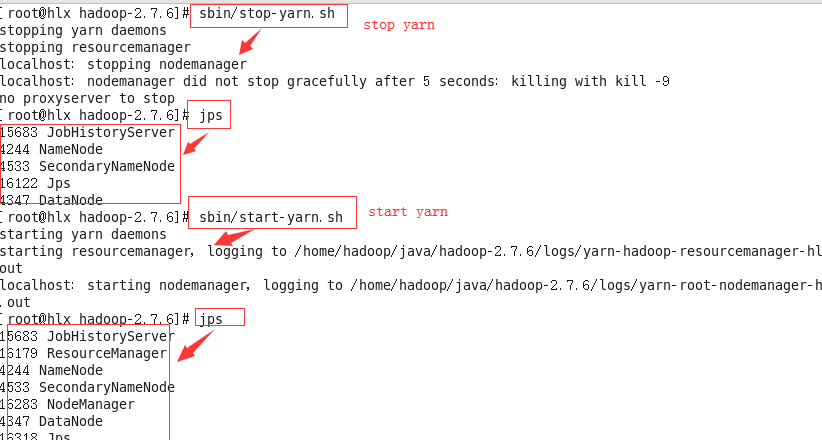
#jps
再启动yarn
#sbin/start-yarn.sh
#jps
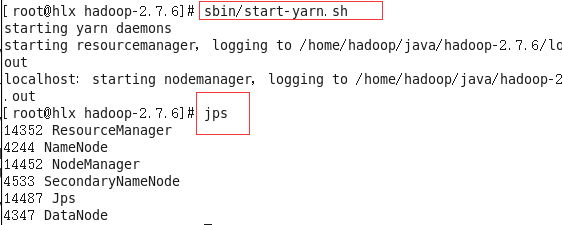
SecondaryNameNode: 辅助NameNode集群管理
ResourceManager :管理集群资源
NodeManager: 向ResourceManager申请资源
JPS 查看系统进程
NameNode 存储元数据
DataNode : 存储数据
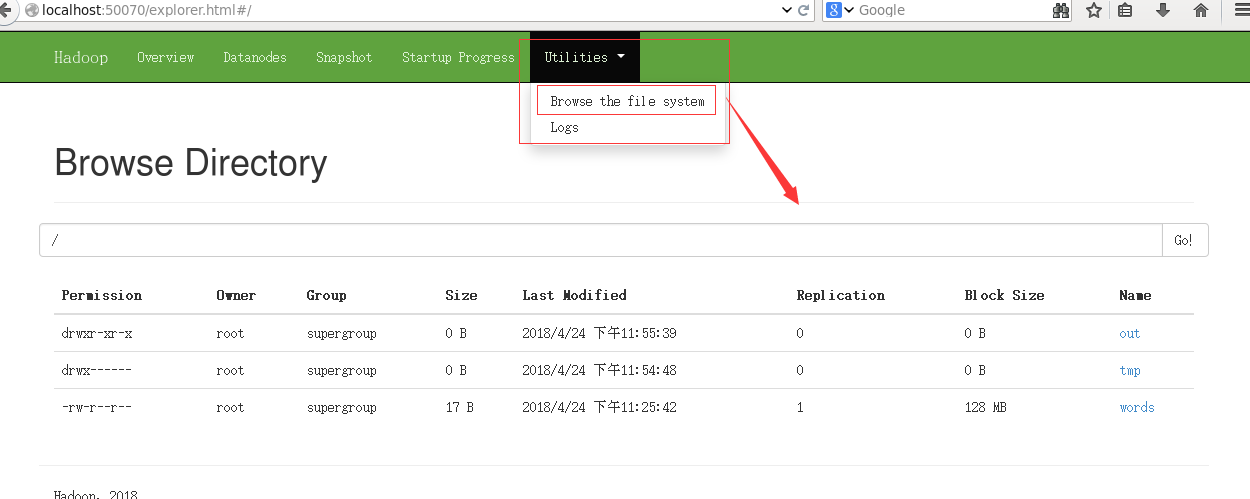
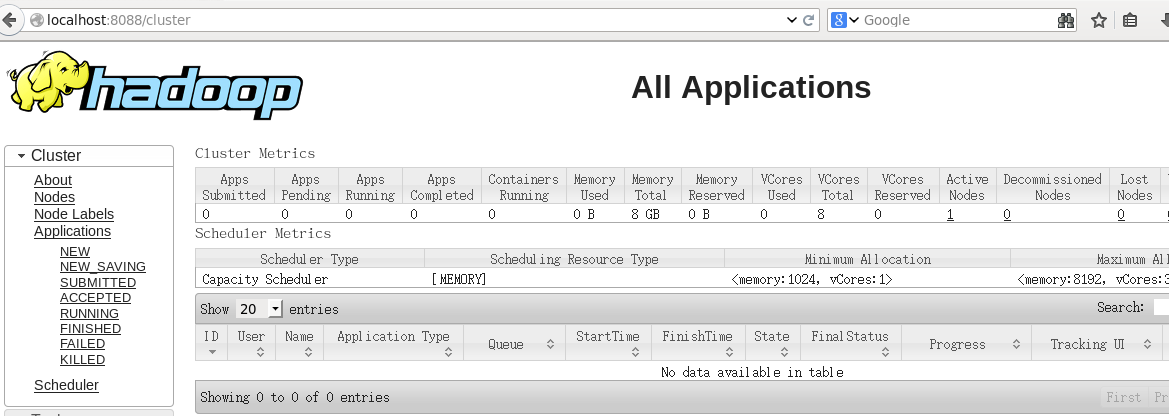
案例
#bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.6.jar
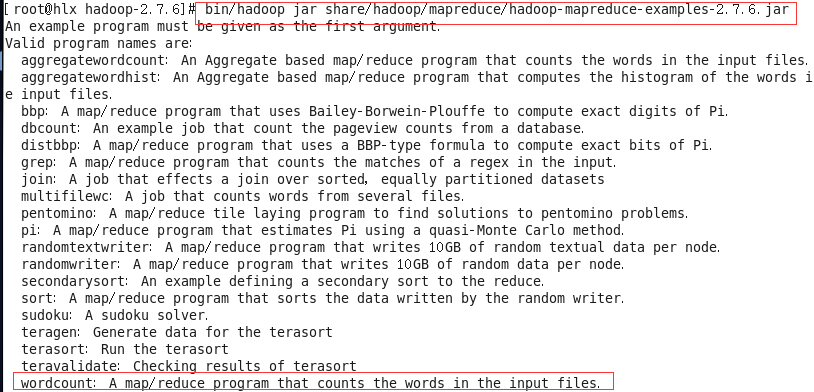
#bin/hadoop jar share/hadoop/mapreduce/hadoop-mapredude-examples-2.7.6.jar wordcount /words /out2

#cd logs
#ls
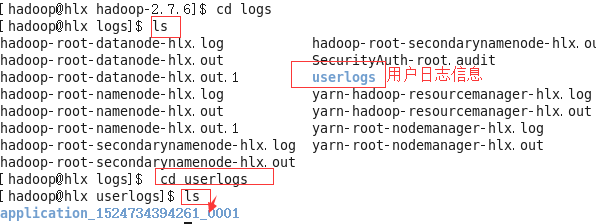
#ls
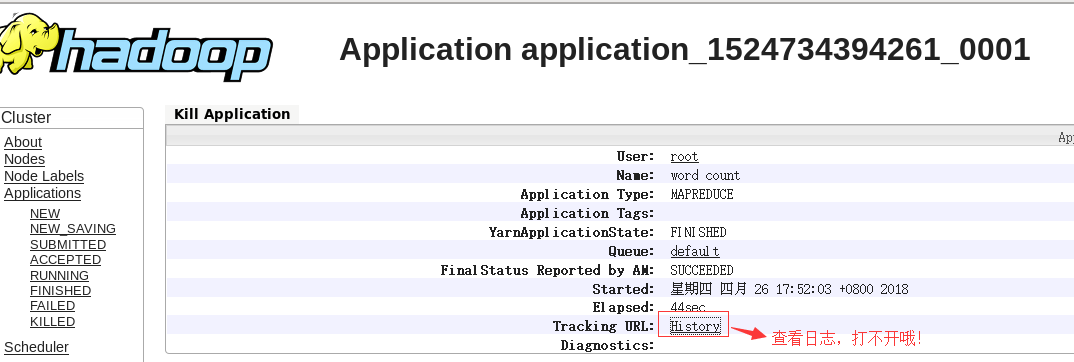
(二)Jobhistory
hlx:19888/jobhistory/job/job_15XXXx 访问不了
要启动: jobhistory
# sbin/mr-jobhistory-daemon.sh start historyserver

#jps查看系统进程
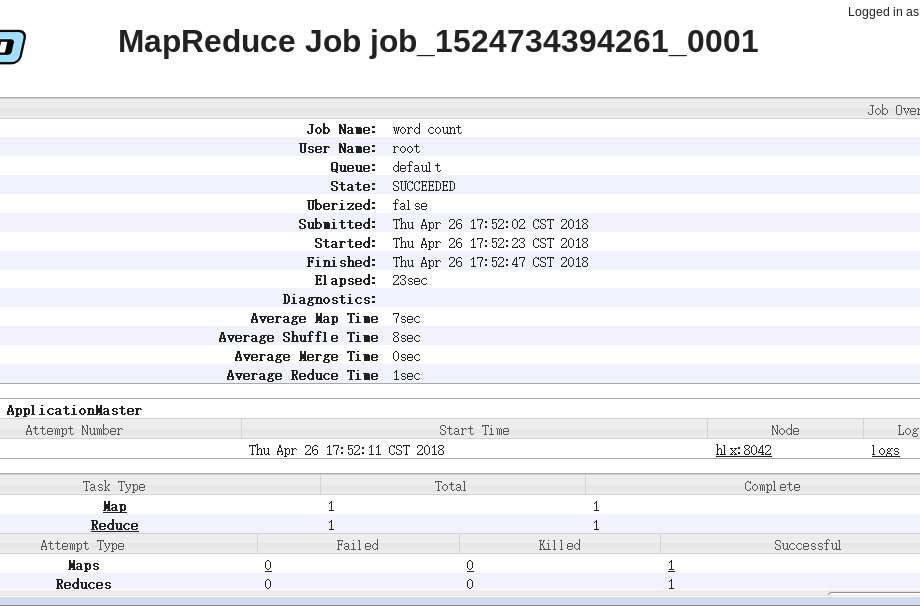
单击Map查看
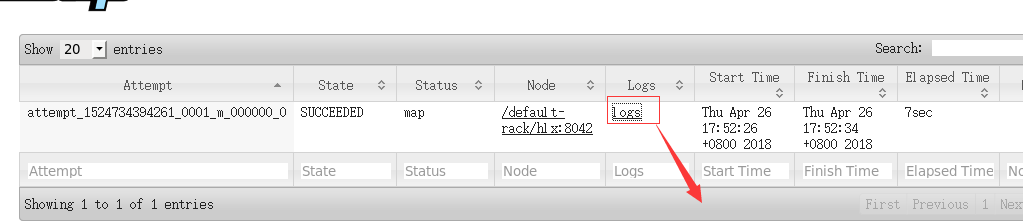
单击logs查看

默认是日志文件存储在本地,需要手动开启!
解决: http://hadoop.apache.org/docs/r2.7.6/hadoop-yarn/hadoop-yarn-common/yarn-default.xml
去查找这个aggregation
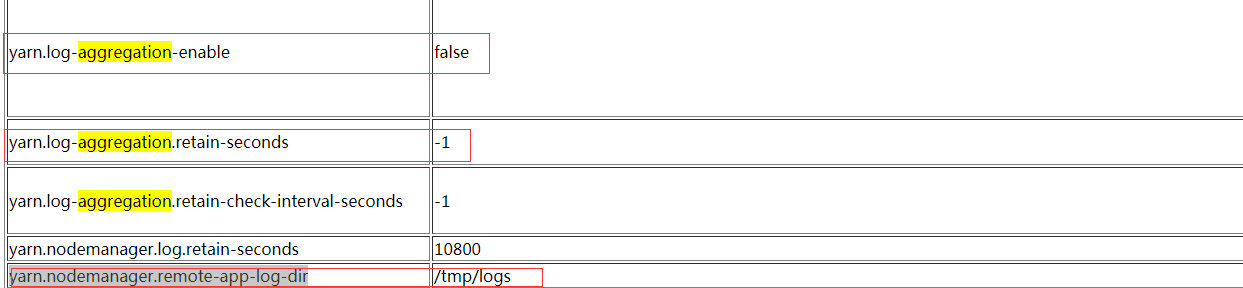
日志删除时间为7天= 7*24*60*60=604800
<!--日志启用 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!--7天就删除日志,默认是永久不删除 -->
<property>
<name>arn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
<!--修改日志目录 -->
<property>
<name>yarn.nodemanager.remote-app-log-dir</name>
<value>/logs</value>
</property>配置完成yarn-site.xml文件之后。
(1)先停止yarn 再重新启动yarn#sbin/stop-yarn.sh
#jps
#sbin/start-yarn.sh
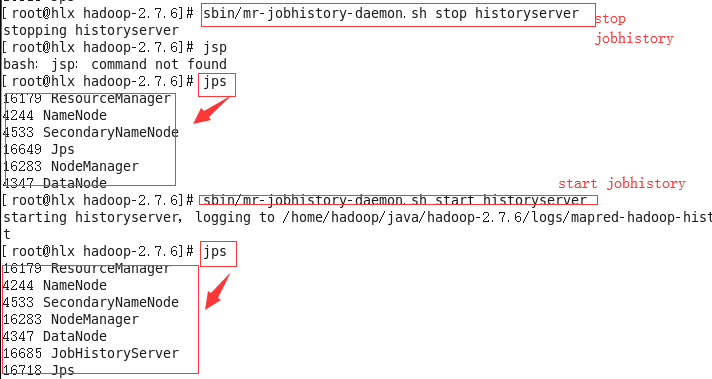
(2)先停止jobhistory 再重新启动jobhistory
#sbin/mr-jobhistory-daemon.sh stop historyserver
#jps
#sbin/mr-jobhistory-daemon.sh start historyserver
(3)再运行词频统计
#bin/hadoop jar share/hadoop/mapreduce/hadoop-mapredude-examples-2.7.6.jar wordcount /words /out4
浏览访问:yarn,jobhistory 查看logs
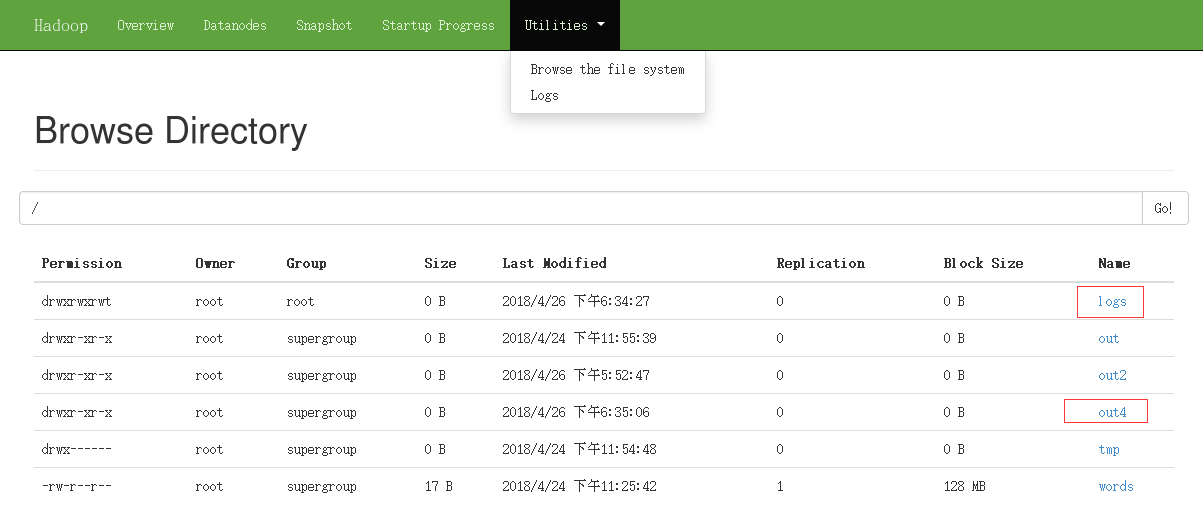
查看刚刚运行的:

http://hadoop.apache.org/docs/r2.7.6/hadoop-mapreduce-client/hadoop-mapreduce-client-core/mapred-default.xml 查找uber模式 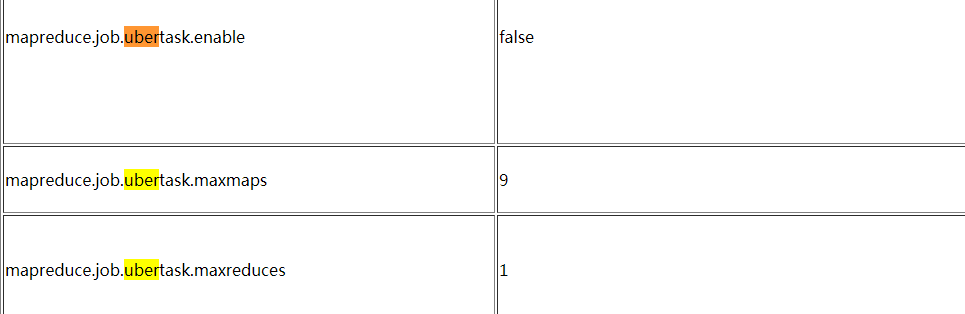
配置mapred-site.xml文件
<!-- 启动uber模式(优化小作业) -->
<property>
<name>mapreduce.job.ubertask.enable</name>
<value>true</value>
</property>
<!-- 启动uber模式的最大map数 -->
<property>
<name>mapreduce.job.ubertask.maxmaps</name>
<value>9</value>
</property>
<!-- 启动uber模式的最大mapreduce数 -->
<property>
<name>mapreduce.job.ubertask.maxreduces</name>
<value>1</value>
</property>(2)先停止yarn 再重新启动yarn
(3)先停止jobhistory 再重新启动jobhistory
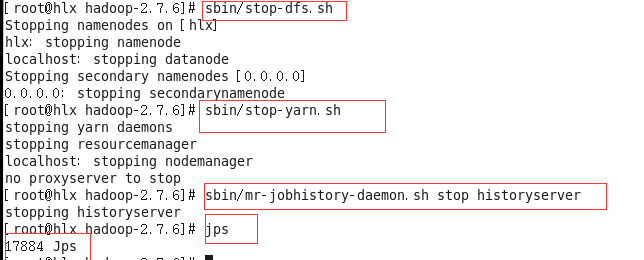
总共是6个进程哦!

#bin/hadoop jar share/hadoop/mapreduce/hadoop-mapredude-examples-2.7.6.jar wordcount /words /out5
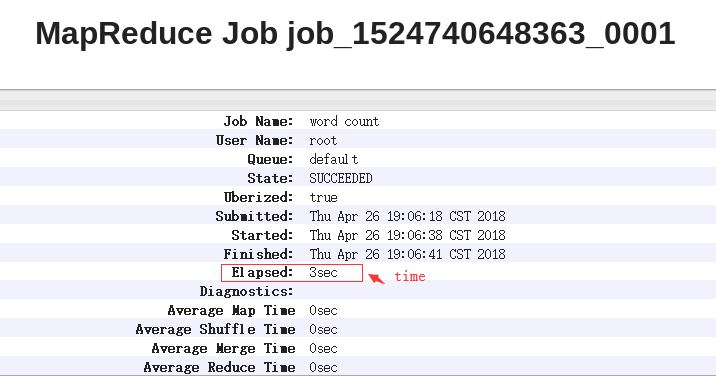
原来的运行的时间:
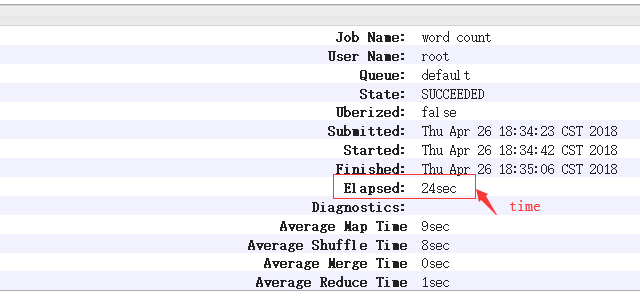
之后加上uber模式运行的时间:

















 1918
1918

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









