






 该博客探讨了在分布式环境中如何设计一个发号器,确保生成的序列号全局唯一、有序、可扩展,并在某些情况下支持生成无规则序列号。同时,系统允许业务方自定义序列号混淆策略,以满足不同需求。
该博客探讨了在分布式环境中如何设计一个发号器,确保生成的序列号全局唯一、有序、可扩展,并在某些情况下支持生成无规则序列号。同时,系统允许业务方自定义序列号混淆策略,以满足不同需求。
1、分布式环境下,保证每个序列号(sequence)是全系统唯一的;
2、序列号可排序,满足单调递增的规律;
3、特定场景下,能生成无规则(或者看不出规则)的序列号;
4、生成的序列号尽量短;
5、序列号可进行二次混淆,提供可扩展的interface,业务方自定义实现。
| 方案 | 介绍 |
|---|---|
| 单机数据库 | 主键ID用bigint类型,并且设置为自增、无符号 优点:(1)能够保证唯一性; (2)能够保证递增性; (3)步长固定; 缺点:不支持数据库分不分表,性能低 |
| UUID | UUID是在本地生成的,所以相对性能较高、时延低、扩展性高,完全不受分库分表的影响! 缺点:无法保证趋势递增;用32位字符串表示,占用数据库空间较大;建立索引查询效率低;可能会出现UUID重复的情况 |
| ID分组 | 1个数据库变成4个库,每个数据库设置不同的auto_increment初始值init,以及相同的增长步长step,以保证每个数据库生成的ID是不同的 缺点:丧失了ID生成的“绝对递增性”;数据库的写压力依然很大;可扩展性差; |
| segment 分段 | Redis和Mysql Redis数据结构(Hash类型) 取号的大部分操作都集中在Redis,为了保证序列号递增的原子性,取号的功能可以用Lua脚本实现。 Mysql数据结构 问题:数据中的max扩容,I/O消耗比正常发号要稍多,会遇到“尖刺” 解决:双Buffer模型 |
| SnowFlake Twitter出品 雪花算法 |
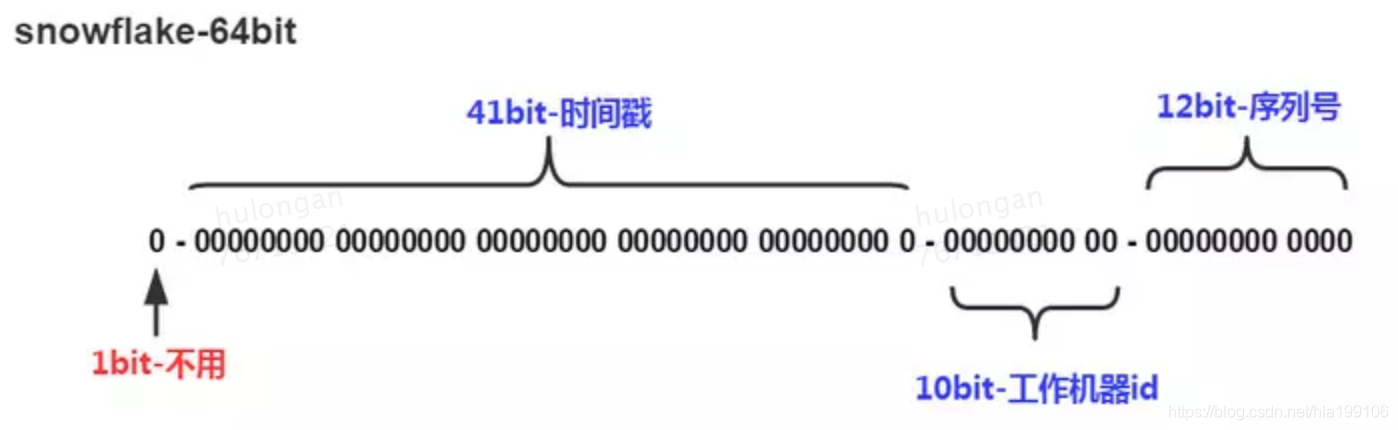
64位的整型 (1)1位:标识部分,在java中由于long的最高位是符号位,正数是0,负数是1,一般生成的ID为正数,所以为0; (2)41位:时间戳部分,这个是毫秒级的时间,一般实现上不会存储当前的时间戳,而是时间戳的差值(当前时间-固定的开始时间),这样可以使产生的ID从更小值开始;41位的时间戳可以使用69年,(1L << 41) / (1000L * 60 * 60 * 24 * 365) = 69年; (3)10位:节点部分,Twitter实现中使用前5位作为数据中心标识,后5位作为机器标识,可以部署1024个节点; (4)12位:序列号部分,支持同一毫秒内同一个节点可以生成4096个ID; 问题:机器id的怎么指定;机器id的生成规则;时钟回拨 |
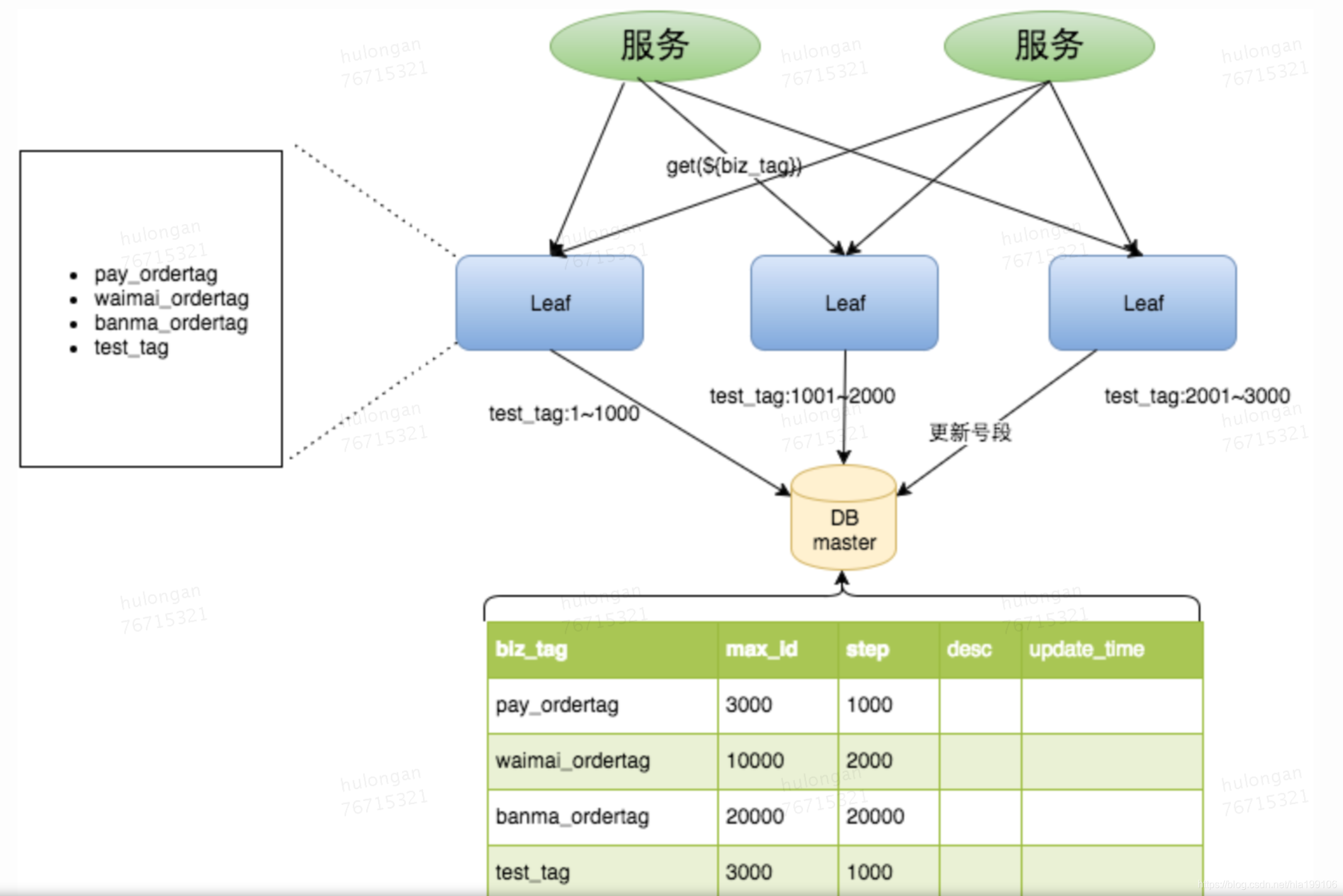
| 美团leaf发号器 | Leaf-segment数据库方案
优点:
缺点:
Leaf-snowflake 弱依赖ZooKeeper:每次会去ZK拿数据以外,也会在本机文件系统上缓存一个workerID文件 解决时钟问题: 在ZK上注册过:与ZK机器上节点做比较 在ZK上没注册过:abs( 系统时间-sum(time)/nodeSize ) < 阈值 |

















 691
691

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









