






Storm
Storm 简介
相当于右边的电梯,实时处理数据,不是一批一批的处理数据

Storm特征
Storm是个实时的、分布式以及具备高容错的计算系统
Storm进程常驻内存
Storm数据不经过磁盘,在内存中处理
Twitter开源的分布式实时大数据处理框架,最早开源于github
2013年,Storm进入Apache社区进行孵化
2014年9月,晋级成为了Apache顶级项目
官网 http://storm.apache.org/
国内外各大网站使用,例如雅虎、阿里、百度
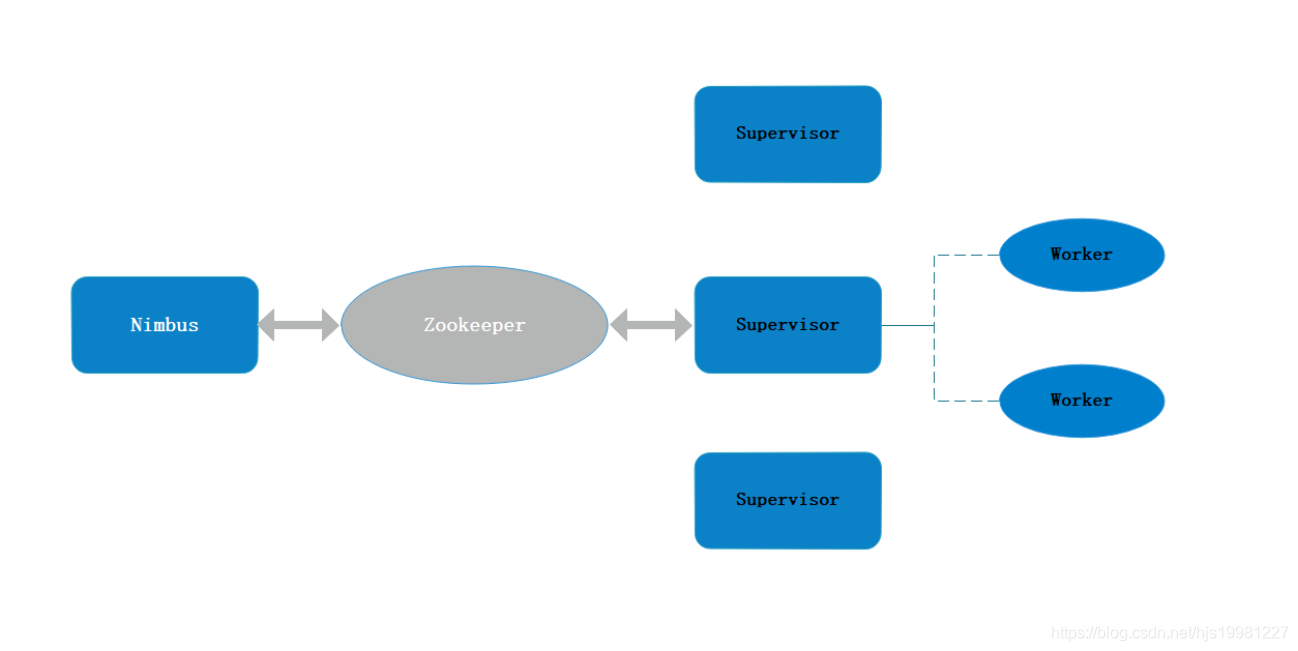
架构
Nimbus
Supervisor
Worker
编程模型
DAG (Topology)
Spout
Bolt
数据传输
ZMQ(twitter早期产品)
ZeroMQ 开源的消息传递框架,并不是一个MessageQueue
Netty
Netty是基于NIO的网络框架,更加高效。(之所以Storm 0.9版本之后使用Netty,是因为ZMQ的license和Storm的license不兼容。)
高可靠性
异常处理
消息可靠性保障机制(ACK)
可维护性
StormUI 图形化监控接口
Storm – 流式处理
流式处理(异步 与 同步)
客户端提交数据进行结算,并不会等待数据计算结果
逐条处理
例:ETL(数据清洗)extracted transform load
统计分析
例:计算PV、UV、访问热点 以及 某些数据的聚合、加和、平均等
客户端提交数据之后,计算完成结果存储到Redis、HBase、MySQL或者其他MQ当中,
客户端并不关心最终结果是多少。

Storm – 实时请求
实时请求应答服务(同步)
客户端提交数据请求之后,立刻取得计算结果并返回给客户端
Drpc
实时请求处理
例:图片特征提取

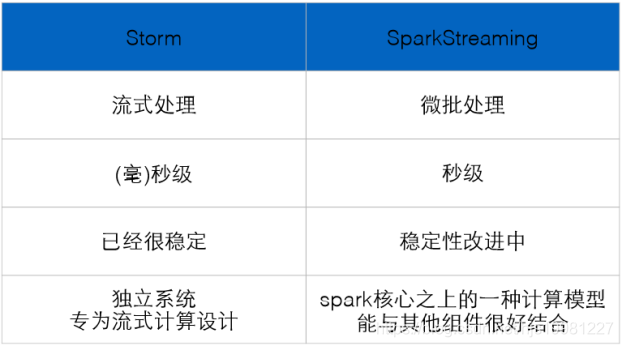
Storm:进程、线程常驻内存运行,数据不进入磁盘,数据通过网络传递。
MapReduce:为TB、PB级别数据设计的批处理计算框架。
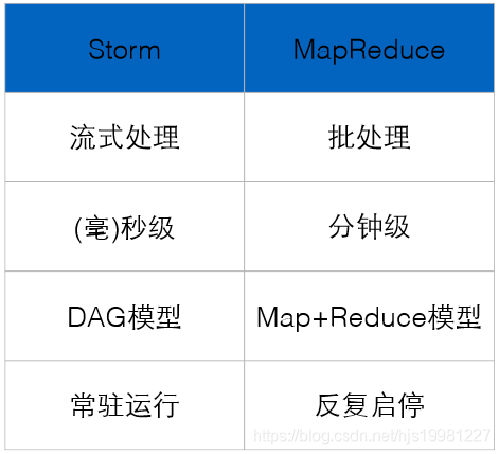
Storm:纯流式处理
专门为流式处理设计
数据传输模式更为简单,很多地方也更为高效
并不是不能做批处理,它也可以来做微批处理,来提高吞吐
Spark Streaming:微批处理
将RDD做的很小来用小的批处理来接近流式处理
基于内存和DAG可以把处理任务做的很快
Storm 计算模型
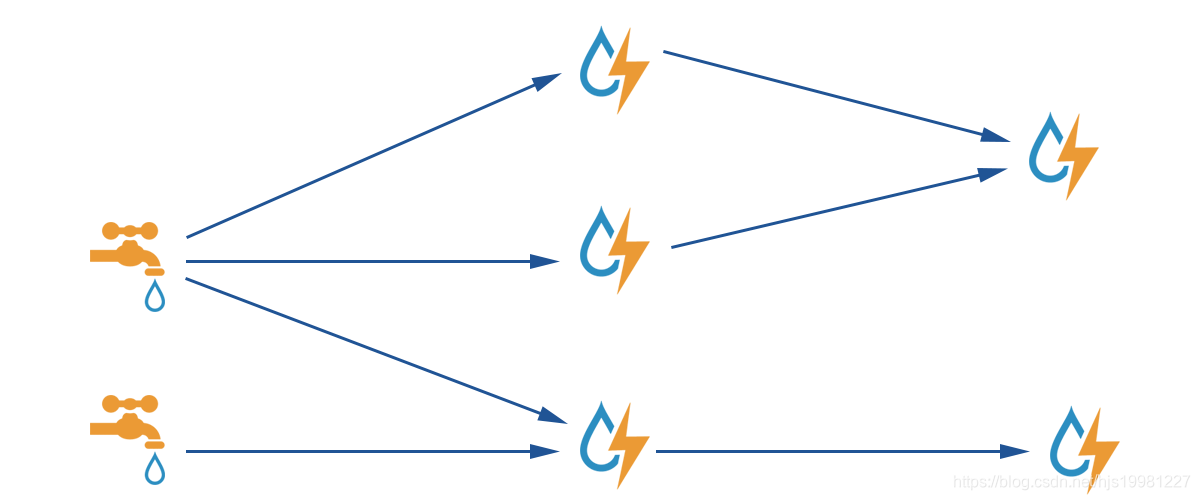
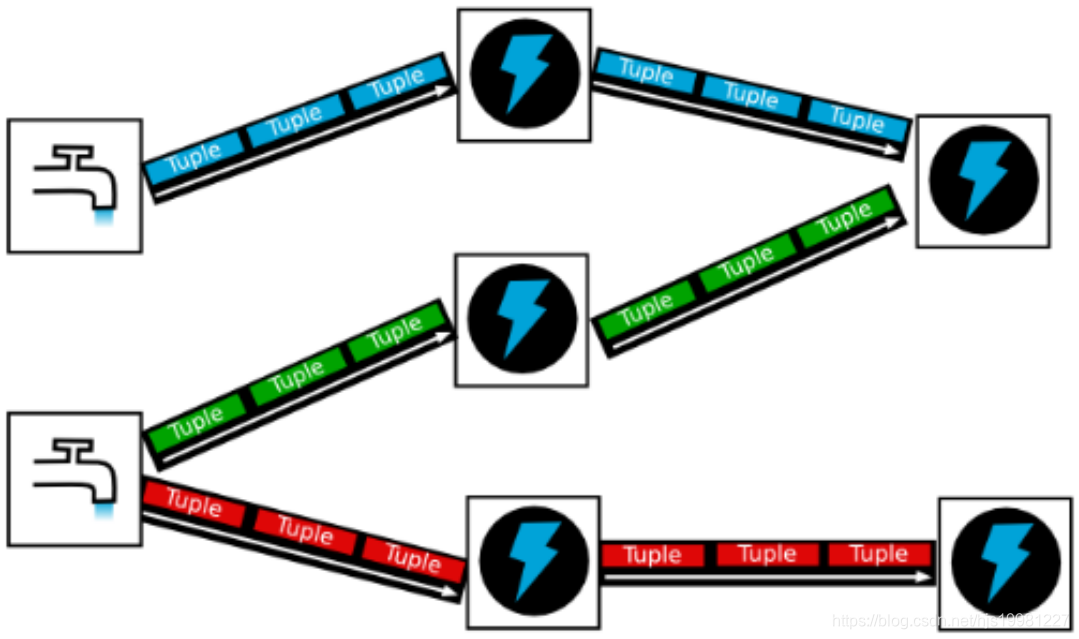
Topology – DAG有向无环图的实现
对于Storm实时计算逻辑的封装
即,由一系列通过数据流相互关联的Spout、Bolt所组成的拓扑结构
生命周期:此拓扑只要启动就会一直在集群中运行,直到手动将其kill,否则不会终止
(区别于MapReduce当中的Job,MR当中的Job在计算执行完成就会终止)
Tuple – 元组
Stream中最小数据组成单元
Stream – 数据流
从Spout中源源不断传递数据给Bolt、以及上一个Bolt传递数据给下一个Bolt,所形成的这些数据通道即叫做Stream
Stream声明时需给其指定一个Id(默认为Default)
实际开发场景中,多使用单一数据流,此时不需要单独指定StreamId

Spout – 数据源
拓扑中数据流的来源。一般会从指定外部的数据源读取元组(Tuple)发送到拓扑(Topology)中
一个Spout可以发送多个数据流(Stream)
可先通过OutputFieldsDeclarer中的declare方法声明定义的不同数据流,发送数据时通过SpoutOutputCollector中的emit方法指定数据流Id(streamId)参数将数据发送出去
Spout中最核心的方法是nextTuple,该方法会被Storm线程不断调用、主动从数据源拉取数据,再通过emit方法将数据生成元组(Tuple)发送给之后的Bolt计算
Bolt – 数据流处理组件
拓扑中数据处理均有Bolt完成。对于简单的任务或者数据流转换,单个Bolt可以简单实现;更加复杂场景往往需要多个Bolt分多个步骤完成
一个Bolt可以发送多个数据流(Stream)
可先通过OutputFieldsDeclarer中的declare方法声明定义的不同数据流,发送数据时通过SpoutOutputCollector中的emit方法指定数据流Id(streamId)参数将数据发送出去
Bolt中最核心的方法是execute方法,该方法负责接收到一个元组(Tuple)数据、真正实现核心的业务逻辑
Stream Grouping – 数据流分组(即数据分发策略)
Storm 数据累加
Storm WordCount

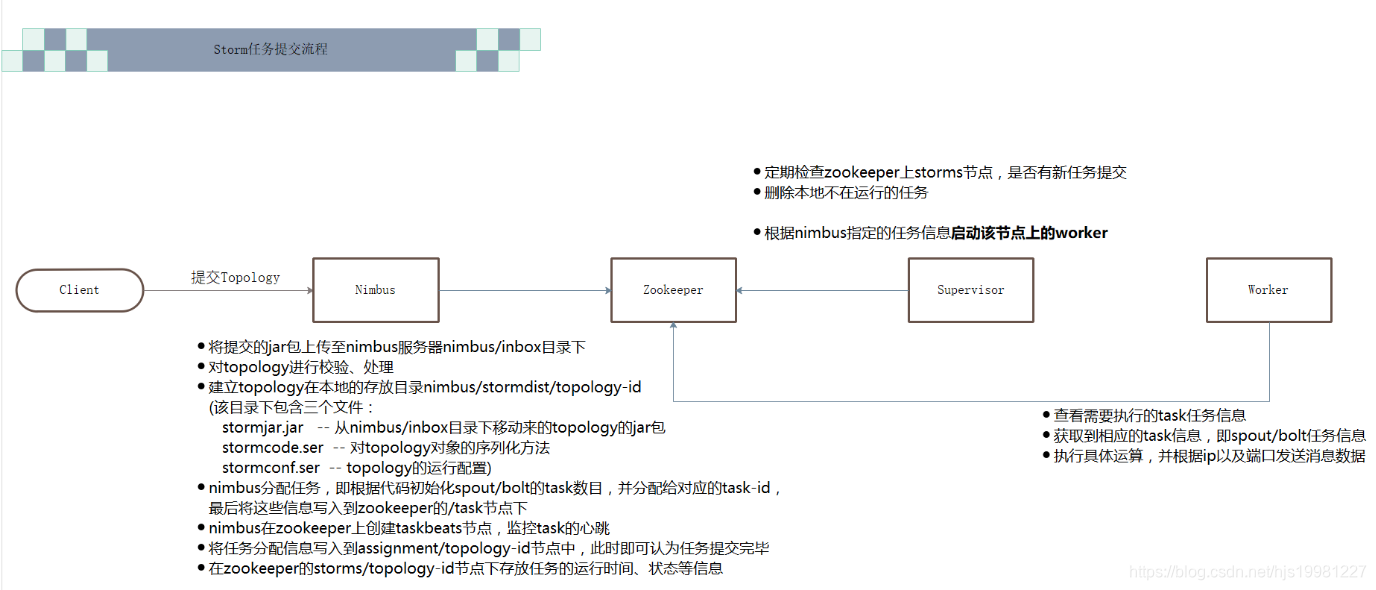
Storm 架构设计
Nimbus
资源调度
任务分配
接收jar包
Supervisor
接收nimbus分配的任务
启动、停止自己管理的worker进程(当前supervisor上worker数量由配置文件设定)
Worker
运行具体处理运算组件的进程(每个Worker对应执行一个Topology的子集)
worker任务类型,即spout任务、bolt任务两种
启动executor
(executor即worker JVM进程中的一个java线程,一般默认每个executor负责执行一个task任务)
Zookeeper
Storm 本地目录树

Storm Zookeeper目录树

Storm 单机部署
环境准备:
Java 6+
Python 2.6.6+
上传、解压安装包
在storm目录中创建logs目录
mkdir logs
./storm help
启动
启动Zookeeper
./bin/storm dev-zookeeper >> ./logs/zk.out 2>&1 &
启动Nimbus
./bin/storm nimbus >> ./logs/nimbus.out 2>&1 &
启动Storm UI
./bin/storm ui >> ./logs/ui.out 2>&1 &
启动Supervisor
./bin/storm supervisor >> ./logs/supervisor.out 2>&1 &
启动Logviewer
./bin/storm logviewer &
Storm 完全分布式部署
环境准备:
Java 6+
Python 2.6.6+
部署ZooKeeper
版本3.4.5+ (高版本Zookeeper实现了对于自身持久化数据的定期删除功能)
(autopurge.purgeInterval; autopurge.snapRetainCount)
上传、解压安装包
在storm目录中创建logs目录
$ mkdir logs
修改配置文件
storm.yaml
Yet Another Markup Language (yaml)
配置文件内容:
storm.zookeeper.servers:
- “node1”
- “node2”
- “node3”
storm.local.dir: “/tmp/storm”
nimbus.host: “node1"
supervisor.slots.ports:
- 6700
- 6701
- 6702
- 6703
分发storm
启动Zookeeper集群
在node1上启动Nimbus
./bin/storm nimbus >> ./logs/nimbus.out 2>&1 &
./bin/storm ui >> ./logs/ui.out 2>&1 &
在node2、node3上启动Supervisor
(按照配置每个Supervisor上启动4个slots)
./bin/storm supervisor >> ./logs/supervisor.out 2>&1 &
Storm UI
启动Storm UI
./storm ui >> ./logs/ui.out 2>&1 &
通过http://node1:8080/访问
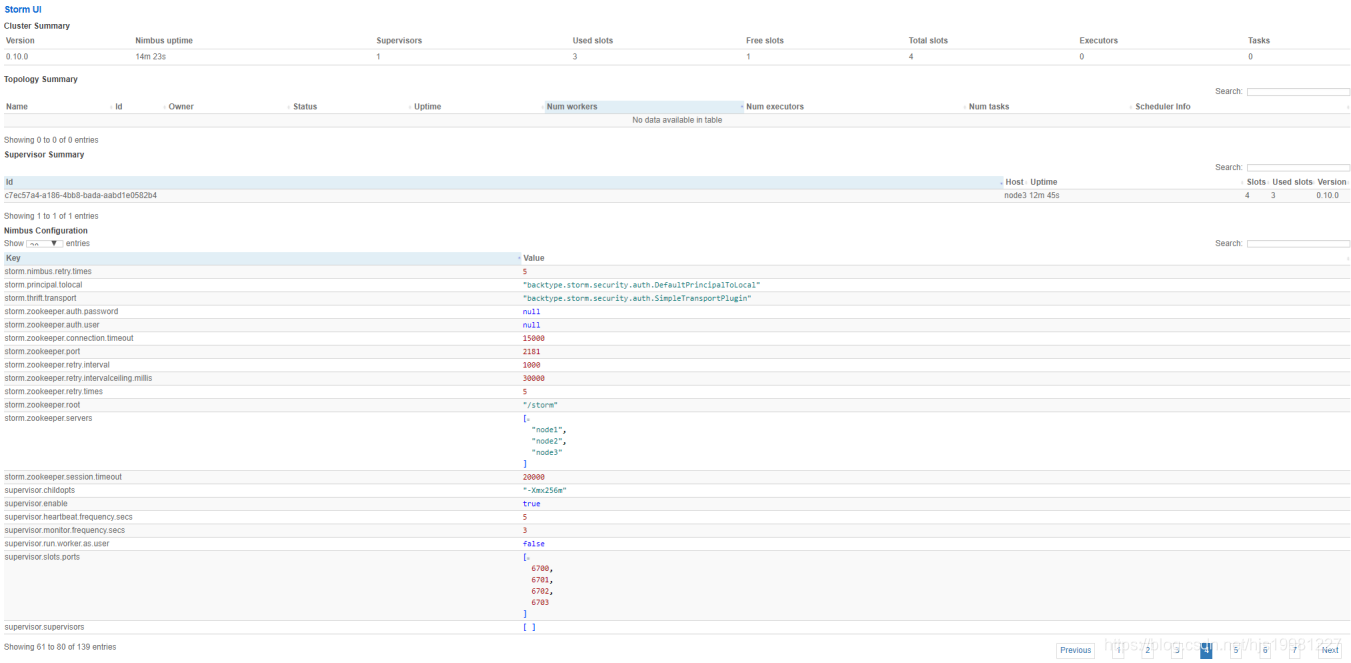
Storm – Drpc
DRPC (Distributed RPC) remote procedure call
分布式远程过程调用
DRPC 是通过一个 DRPC 服务端(DRPC server)来实现分布式 RPC 功能的。
DRPC Server 负责接收 RPC 请求,并将该请求发送到 Storm中运行的 Topology,等待接收 Topology 发送的处理结果,并将 该结果返回给发送请求的客户端。
(其实,从客户端的角度来说,DPRC 与普通的 RPC 调用并没有什么区别。)
DRPC设计目的:
为了充分利用Storm的计算能力实现高密度的并行实时计算。
(Storm接收若干个数据流输入,数据在Topology当中运行完成,然后通过DRPC将结果进行输出。)
客户端通过向 DRPC 服务器发送待执行函数的名称以及该函数的参数来获取处理结果。实现该函数的拓扑使用一个DRPCSpout 从 DRPC 服务器中接收一个函数调用流。DRPC 服务器会为每个函数调用都标记了一个唯一的 id。随后拓扑会执行函数来计算结果,并在拓扑的最后使用一个名为 ReturnResults 的 bolt 连接到 DRPC 服务器,根据函数调用的 id 来将函数调用的结果返回。
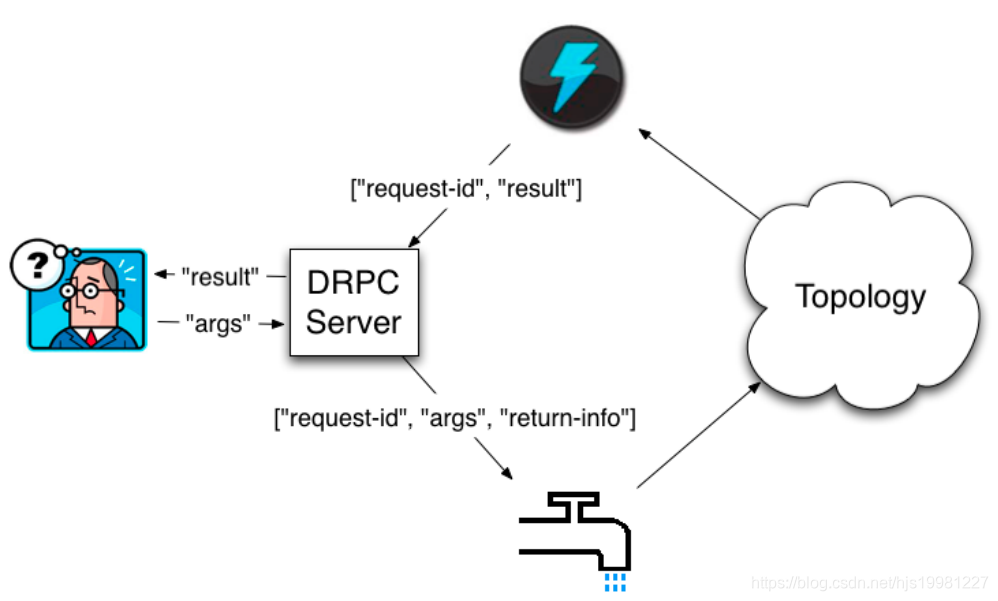
定义DRPC拓扑:
方法1:
通过LinearDRPCTopologyBuilder (该方法也过期,不建议使用)
该方法会自动为我们设定Spout、将结果返回给DRPC Server等,我们只需要将Topology实现
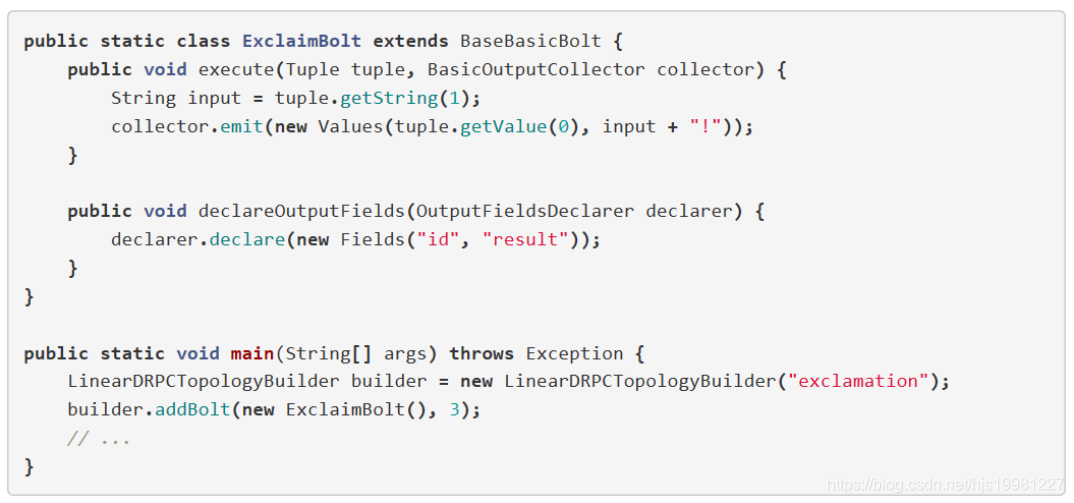
方法2:
直接通过普通的拓扑构造方法TopologyBuilder来创建DRPC拓扑
需要手动设定好开始的DRPCSpout以及结束的ReturnResults

运行模式
:本地模式

运行模式:
2、远程模式(集群模式)
修改配置文件conf/storm.yaml
drpc.servers:
- "node1“
启动DRPC Server
bin/storm drpc &
通过StormSubmitter.submitTopology提交拓扑

Flume+Kafka+Storm架构设计
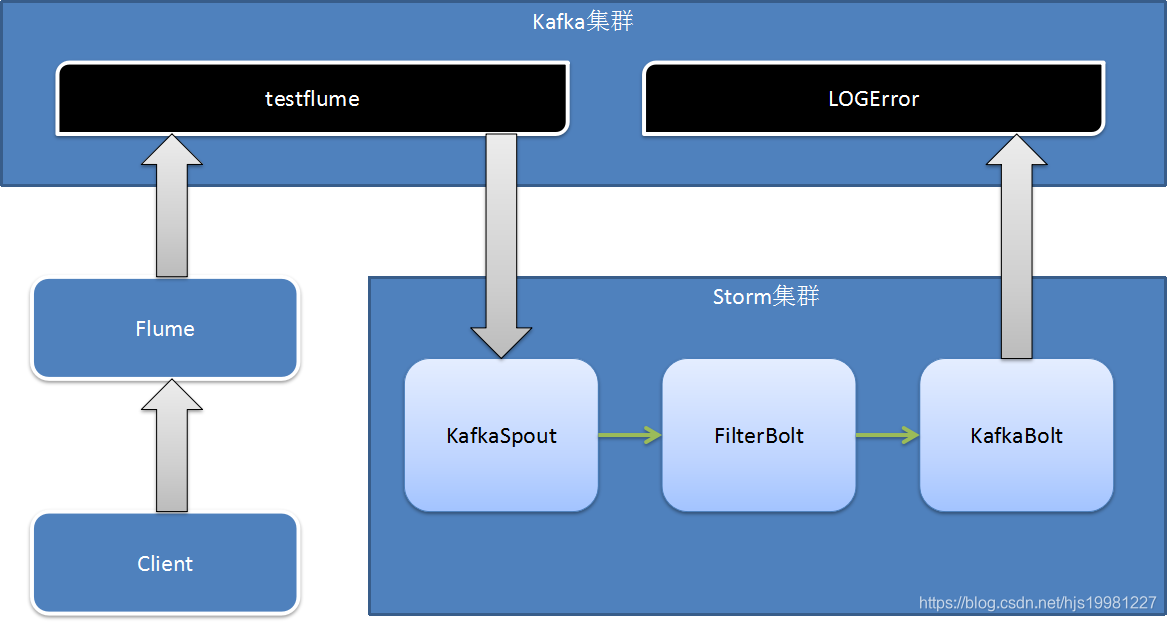
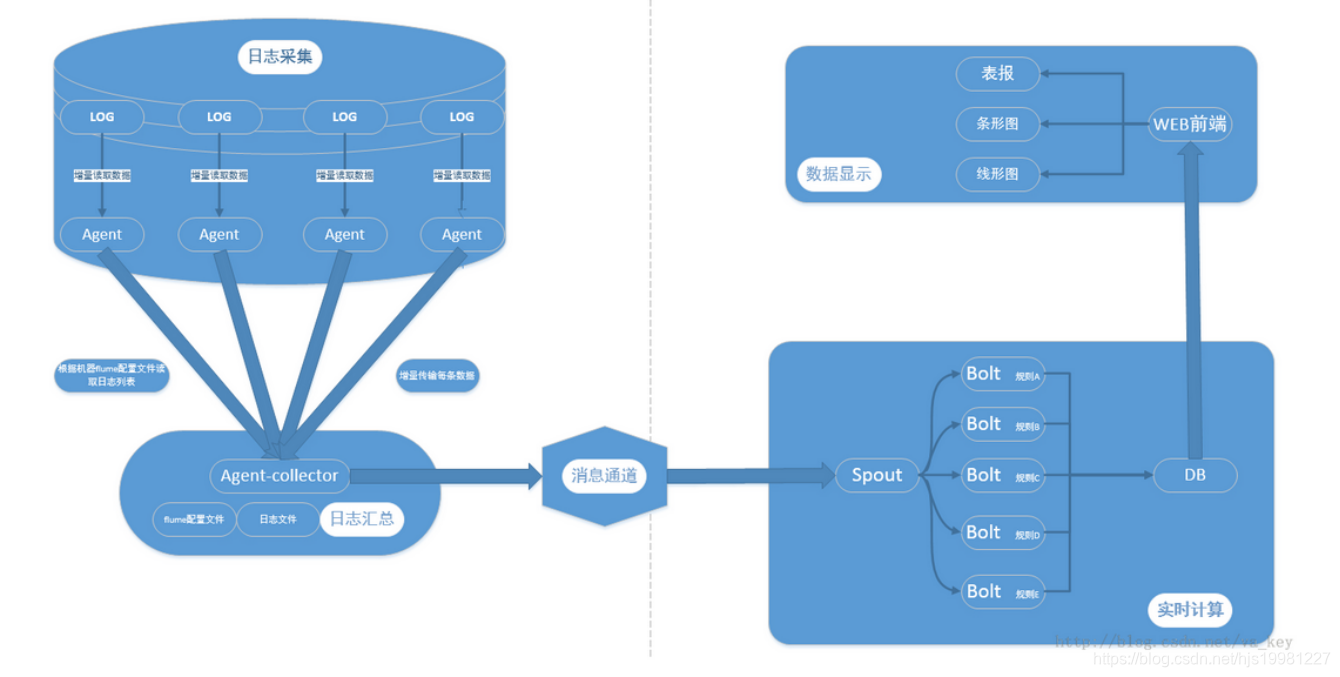
采集层:实现日志收集,使用负载均衡策略
消息队列:作用是解耦及不同速度系统缓冲
实时处理单元:用Storm来进行数据处理,最终数据流入DB中
展示单元:数据可视化,使用WEB框架展示
美团Flume架构
http://tech.meituan.com/mt-log-system-arch.html
Flume的负载均衡
http://flume.apache.org/FlumeUserGuide.html#load-balancing-sink-processor
Storm Grouping – 数据流分组(即数据分发策略)
-
Shuffle Grouping
随机分组,随机派发stream里面的tuple,保证每个bolt task接收到的tuple数目大致相同。
轮询,平均分配 -
Fields Grouping
按字段分组,比如,按"user-id"这个字段来分组,那么具有同样"user-id"的 tuple 会被分到相同的Bolt里的一个task, 而不同的"user-id"则可能会被分配到不同的task。 -
All Grouping
广播发送,对于每一个tuple,所有的bolts都会收到 -
Global Grouping
全局分组,把tuple分配给task id最低的task 。 -
None Grouping
不分组,这个分组的意思是说stream不关心到底怎样分组。目前这种分组和Shuffle grouping是一样的效果。 有一点不同的是storm会把使用none grouping的这个bolt放到这个bolt的订阅者同一个线程里面去执行(未来Storm如果可能的话会这样设计)。 -
Direct Grouping
指向型分组, 这是一种比较特别的分组方法,用这种分组意味着消息(tuple)的发送者指定由消息接收者的哪个task处理这个消息。只有被声明为 Direct Stream 的消息流可以声明这种分组方法。而且这种消息tuple必须使用 emitDirect 方法来发射。消息处理者可以通过 TopologyContext 来获取处理它的消息的task的id (OutputCollector.emit方法也会返回task的id) -
Local or shuffle grouping
本地或随机分组。如果目标bolt有一个或者多个task与源bolt的task在同一个工作进程中,tuple将会被随机发送给这些同进程中的tasks。否则,和普通的Shuffle Grouping行为一致
customGrouping
自定义,相当于mapreduce那里自己去实现一个partition一样。
Storm 并发机制
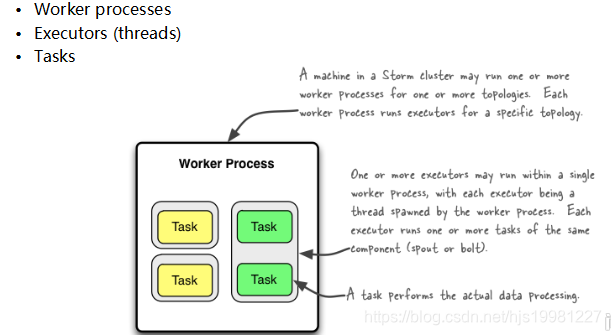
Worker – 进程
一个Topology拓扑会包含一个或多个Worker(每个Worker进程只能从属于一个特定的Topology)
这些Worker进程会并行跑在集群中不同的服务器上,即一个Topology拓扑其实是由并行运行在Storm集群中多台服务器上的进程所组成
Executor – 线程
Executor是由Worker进程中生成的一个线程
每个Worker进程中会运行拓扑当中的一个或多个Executor线程
一个Executor线程中可以执行一个或多个Task任务(默认每个Executor只执行一个Task任务),但是这些Task任务都是对应着同一个组件(Spout、Bolt)。
Task
实际执行数据处理的最小单元
每个task即为一个Spout或者一个Bolt
Task数量在整个Topology生命周期中保持不变,Executor数量可以变化或手动调整
(默认情况下,Task数量和Executor是相同的,即每个Executor线程中默认运行一个Task任务)
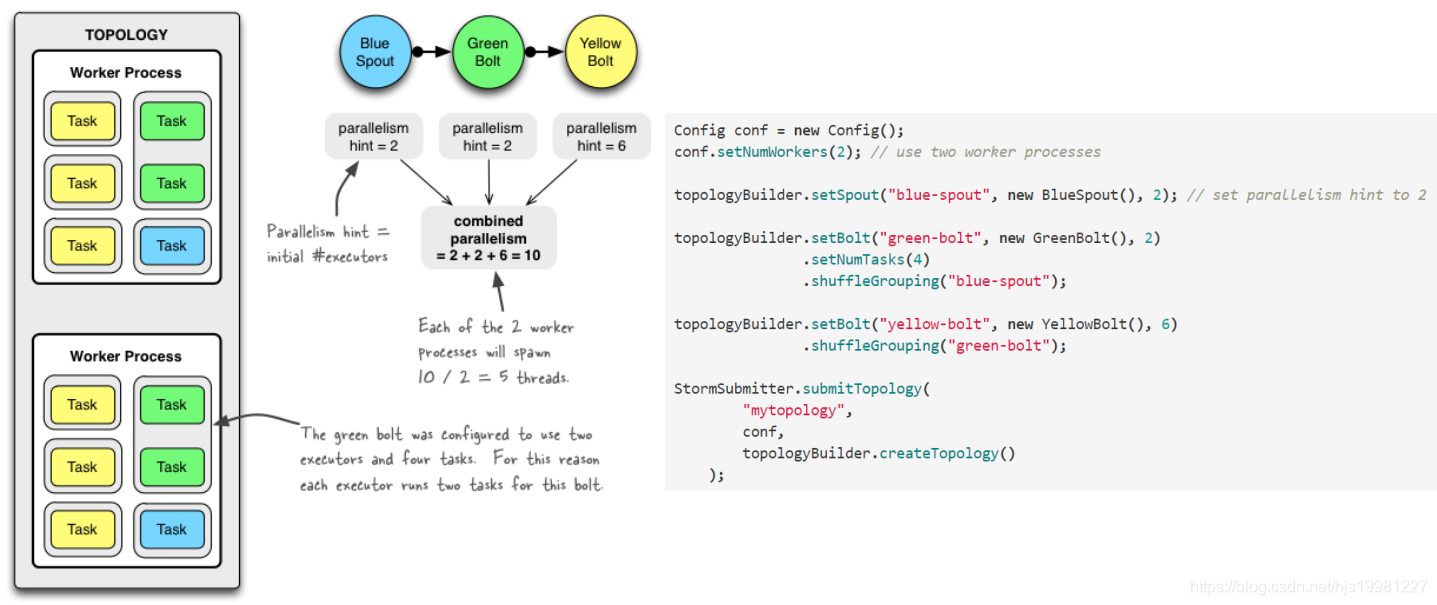
设置Worker进程数
Config.setNumWorkers(int workers)
设置Executor线程数
TopologyBuilder.setSpout(String id, IRichSpout spout, Number parallelism_hint)
TopologyBuilder.setBolt(String id, IRichBolt bolt, Number parallelism_hint)
:其中, parallelism_hint即为executor线程数
设置Task数量
ComponentConfigurationDeclarer.setNumTasks(Number val)
例:
Config conf = new Config() ;
conf.setNumWorkers(2);
TopologyBuilder topologyBuilder = new TopologyBuilder();
topologyBuilder.setSpout("spout", new MySpout(), 1);
topologyBuilder.setBolt("green-bolt", new GreenBolt(), 2)
.setNumTasks(4)
.shuffleGrouping("blue-spout);
Rebalance – 再平衡
即,动态调整Topology拓扑的Worker进程数量、以及Executor线程数量
支持两种调整方式:
1、通过Storm UI
2、通过Storm CLI
通过Storm CLI动态调整:
例:storm rebalance mytopology -n 5 -e blue-spout=3 -e yellow-bolt=10
将mytopology拓扑worker进程数量调整为5个
“ blue-spout ” 所使用的线程数量调整为3个
“ yellow-bolt ”所使用的线程数量调整为10个
Storm 容错机制
1、集群节点宕机
Nimbus服务器
单点故障?
非Nimbus服务器
故障时,该节点上所有Task任务都会超时,Nimbus会将这些Task任务重新分配到其他服务器上运行
2、进程挂掉
Worker
挂掉时,Supervisor会重新启动这个进程。如果启动过程中仍然一直失败,并且无法向Nimbus发送心跳,Nimbus会将该 Worker重新分配到其他服务器上
Supervisor
无状态(所有的状态信息都存放在Zookeeper中来管理)
快速失败(每当遇到任何异常情况,都会自动毁灭)
Nimbus
无状态(所有的状态信息都存放在Zookeeper中来管理)
快速失败(每当遇到任何异常情况,都会自动毁灭)
3、消息的完整性

消息的完整性
从Spout中发出的Tuple,以及基于他所产生Tuple(例如上个例子当中Spout发出的句子,以及句子当中单词的tuple等)
由这些消息就构成了一棵tuple树
当这棵tuple树发送完成,并且树当中每一条消息都被正确处理,就表明spout发送消息被“完整处理”,即消息的完整性
Acker – 消息完整性的实现机制
Storm的拓扑当中特殊的一些任务
负责跟踪每个Spout发出的Tuple的DAG(有向无环图)
Storm – 事务
事务性拓扑(Transactional Topologies)
保证消息(tuple)被且仅被处理一次
官网:http://storm.apache.org/releases/0.9.6/Transactional-topologies.html
Design 1
强顺序流(强有序)

引入事务(transaction)的概念,每个transaction(即每个tuple)关联一个transaction id。
Transaction id从1开始,每个tuple会按照顺序+1。
在处理tuple时,将处理成功的tuple结果以及transaction id同时写入数据库中进行存储。
两种情况:
1、当前transaction id与数据库中的transaction id不一致
2、两个transaction id相同
缺点:
一次只能处理一个tuple,无法实现分布式计算
Design 2
强顺序的Batch流
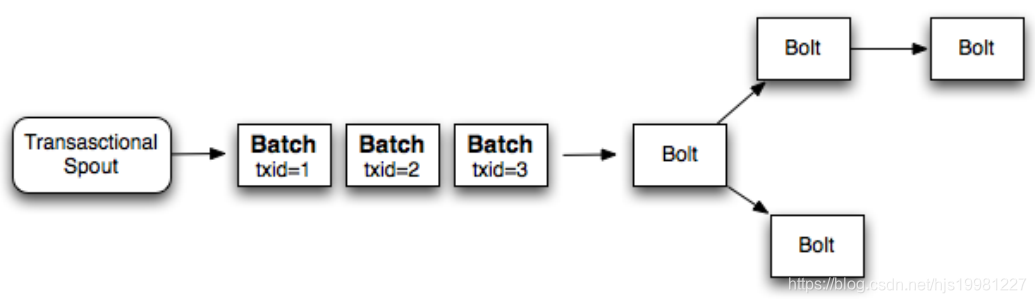
事务(transaction)以batch为单位,即把一批tuple称为一个batch,每次处理一个batch。
每个batch(一批tuple)关联一个transaction id
每个batch内部可以并行计算
缺点?

Design 3
Storm’s design
将Topology拆分为两个阶段:
1、Processing phase
允许并行处理多个batch
2、Commit phase
保证batch的强有序,一次只能处理一个batch
Design details
Manages state - 状态管理
Storm通过Zookeeper存储所有transaction相关信息(包含了:当前transaction id 以及batch的元数据信息)
Coordinates the transactions - 协调事务
Storm会管理决定transaction应该处理什么阶段(processing、committing)
Fault detection - 故障检测
Storm内部通过Acker机制保障消息被正常处理(用户不需要手动去维护)
First class batch processing API
Storm提供batch bolt接口
三种事务:
1、普通事务
2、Partitioned Transaction - 分区事务
3、Opaque Transaction - 不透明分区事务
flume安装
1 ftp 上传linux: apache-flume-1.6.0-bin.tar.gz
2 解压到 /opt/sxt目录下
3 进入conf/ 目录,直接把flume-env.sh.template 文件改为flume-env.sh
4 修改flume-env.sh 文件中的export_java ,变为 export JAVA_HOME=/usr/java/jdk1.7.0_67
5 配置flume环境变量在profile中
./conf/ 目录下创建: fk.conf
a1.sources = r1
a1.sinks = k1
a1.channels = c1
#Describe/configure the source
a1.sources.r1.type = avro
a1.sources.r1.bind = node06
a1.sources.r1.port = 41414
#Describe the sink
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.topic = testflume
a1.sinks.k1.brokerList = node06:9092,node07:9092,node08:9092
a1.sinks.k1.requiredAcks = 1
a1.sinks.k1.batchSize = 20
#Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000000
a1.channels.c1.transactionCapacity = 10000
#Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
启动:
bin/flume-ng agent -n a1 -c conf -f conf/fk.conf -Dflume.root.logger=DEBUG,console
hbase伪分布式安装
(1) 准备JDK/HBase安装包
(2) 安装JDK/配置环境变量
(3) 上传/解压/部署HBase
(4) 配置HBase环境变量
(5) 修改
H
B
A
S
E
H
O
M
E
/
c
o
n
f
/
h
b
a
s
e
−
e
n
v
.
s
h
(
设
置
J
A
V
A
H
O
M
E
)
(
6
)
修
改
{HBASE_HOME}/conf/hbase-env.sh(设置JAVA_HOME) (6) 修改
HBASEHOME/conf/hbase−env.sh(设置JAVAHOME)(6)修改{HBASE_HOME}/conf/hbase-site.xml,如下:
hbase.rootdir file:///home/testuser/hbase
hbase.zookeeper.property.dataDir /home/testuser/zookeeper
(7) 启动HBase服务:start-hbase.sh
(8) 关闭HBase服务:stop-hbase.sh
(9) 访问HBase WEB UI:[ip:60010]
(10) 启动HBase shell客户端:hbase shell
注意:退格键需按Ctrl键
关闭进程
jps: 展示进程(hmaster)
kill -9 pid (hbase 进程号)
storm安装
一、环境要求
JDK 1.6+
java -version
Python 2.6.6+
python -V
ZooKeeper3.4.5+
storm 0.9.4+
二、单机模式
上传解压
$ tar xf apache-storm-0.9.4.tar.gz
$ cd apache-storm-0.9.4
$ storm安装目录下创建log: mkdir logs
$ ./bin/storm --help
下面分别启动ZooKeeper、Nimbus、UI、supervisor、logviewer
$ ./bin/storm dev-zookeeper >> ./logs/zk.out 2>&1 &
$ ./bin/storm nimbus >> ./logs/nimbus.out 2>&1 &
$ ./bin/storm ui >> ./logs/ui.out 2>&1 &
$ ./bin/storm supervisor >> ./logs/supervisor.out 2>&1 &
$ ./bin/storm logviewer >> ./logs/logviewer.out 2>&1 &
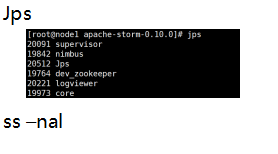
需要等一会儿
$ jps
6966 Jps
6684 logviewer
6680 dev_zookeeper
6681 nimbus
6682 core
6683 supervisor
http://node01:8080
提交任务到Storm集群当中运行:
$ ./bin/storm jar examples/storm-starter/storm-starter-topologies-0.9.4.jar storm.starter.WordCountTopology wordcount
$ ./bin/storm jar examples/storm-starter/storm-starter-topologies-0.9.4.jar storm.starter.WordCountTopology test
三、完全分布式安装部署
各节点分配:
Nimbus Supervisor Zookeeper
node1 1 1
node2 1 1
node3 1 1
node1作为nimbus,
开始配置
$ vim conf/storm.yaml
storm.zookeeper.servers:
- “node1”
- “node2”
- “node3”
storm.local.dir: “/tmp/storm”
nimbus.host: “node1”
supervisor.slots.ports:
- 6700
- 6701
- 6702
- 6703
在storm目录中创建logs目录
$ mkdir logs
(分发)集群其他服务器
启动ZooKeeper集群
node1上启动Nimbus
$ ./bin/storm nimbus >> ./logs/nimbus.out 2>&1 &
$ tail -f logs/nimbus.log
$ ./bin/storm ui >> ./logs/ui.out 2>&1 &
$ tail -f logs/ui.log
节点node2和node3启动supervisor,按照配置,每启动一个supervisor就有了4个slots
$ ./bin/storm supervisor >> ./logs/supervisor.out 2>&1 &
$ tail -f logs/supervisor.log
(当然node1也可以启动supervisor)
http://node1:8080/
提交任务到Storm集群当中运行:
$ ./bin/storm jar examples/storm-starter/storm-starter-topologies-0.9.4.jar storm.starter.WordCountTopology test
环境变量可以配置也可以不配置
export STORM_HOME=/opt/sxt/storm
export PATH=
P
A
T
H
:
PATH:
PATH:STORM_HOME/bin
观察关闭一个supervisor后,nimbus的重新调度
再次启动一个新的supervisor后,观察,并rebalance
集群drpc
修改
$ vi conf/storm.yaml
drpc.servers:
- “node06”
分发配置storm.yaml文件给其他节点
启动zk
主节点启动 nimbus,supervisor,drpc
从启动 supervisor


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









