







Java 8 到 Java 21 系列之 Stream API:数据处理的新方式(Java 8)
系列目录
- Java8 到 Java21 系列之 Lambda 表达式:函数式编程的开端(Java 8)
- Java 8 到 Java 21 系列之 Stream API:数据处理的新方式(Java 8)
- Java 8 到 Java 21 系列之 Optional 类型:优雅地处理空值(Java 8)
- Java 8 到 Java 21 系列之 新日期时间API:精确的时间管理(Java 8)
- Java 8 到 Java 21 系列之 模块化系统:构建模块化的 Java 应用(Java 9) 更新中
- Java 8 到 Java 21 系列之 JShell:即时运行 Java 代码(Java 9) 更新中
- Java 8 到 Java 21 系列之 局部变量类型推断:var 关键字的妙用(Java 10) 更新中
- Java 8 到 Java 21 系列之 HTTP Client API:现代网络通信的基础(Java 11) 更新中
- Java 8 到 Java 21 系列之 ZGC:低延迟垃圾收集器的秘密(Java 11) 更新中
- Java 8 到 Java 21 系列之 Switch 表达式的进化(Java 12) 更新中
- Java 8 到 Java 21 系列之 文本块:轻松管理多行字符串(Java 13) 更新中
- Java 8 到 Java 21 系列之 instanceof 模式匹配:简化类型检查(Java 14) 更新中
- Java 8 到 Java 21 系列之 Records:数据类的全新体验(Java 14) 更新中
- Java 8 到 Java 21 系列之 密封类:限制继承的艺术(Java 15) 更新中
- Java 8 到 Java 21 系列之 外部函数与内存 API:无缝集成本地代码(Java 17) 更新中
- Java 8 到 Java 21 系列之 Sealed Classes 正式登场:增强类型安全性(Java 17) 更新中
- Java 8 到 Java 21 系列之 强封装 JDK 内部 API:保护你的应用程序(Java 17) 更新中
- Java 8 到 Java 21 系列之 增强的伪随机数生成器:更高质量的随机数(Java 17) 更新中
- Java 8 到 Java 21 系列之 虚拟线程:并发编程的新纪元(Java 21) 更新中
- Java 8 到 Java 21 系列之 分代 ZGC 优化:迈向更高性能(Java 21) 更新中
- Java 8 到 Java 21 系列之 序列集合 API:简化集合操作(Java 21) 更新中
摘要与引言
随着Java 8的到来,Stream API作为一项革命性的特性被引入,它为Java开发者提供了一种全新的、声明式的方式来处理集合数据。通过Stream API,我们可以轻松地执行过滤、映射、排序和聚合等操作,同时还能享受到并行处理带来的性能提升。本文将深入探讨Stream API的核心概念、常用操作以及一些实际应用案例,帮助你快速上手这一强大的工具。
Stream API简介
在Java 8中,Stream是一种用于处理元素序列的数据结构抽象,它可以高效地进行各种数据处理任务。Stream不是一种数据存储机制,而是一个从源(如集合、数组)获取数据并进行处理的管道。
Stream的特点
- 惰性求值:中间操作不会立即执行,只有当遇到终端操作时才会触发。
- 不可重复消费:流只能被消费一次,一旦流开始计算,就不能再次使用。
- 支持并行:利用多核处理器的能力,可以轻松实现并行处理。
1 传统方法 vs Stream API
在Java 8之前,对集合的操作通常需要手动编写循环和条件语句,首先附上一个最常用的List集合遍历处理案例。例如,假设我们有一个整数列表,并希望找出其中所有大于100的偶数:
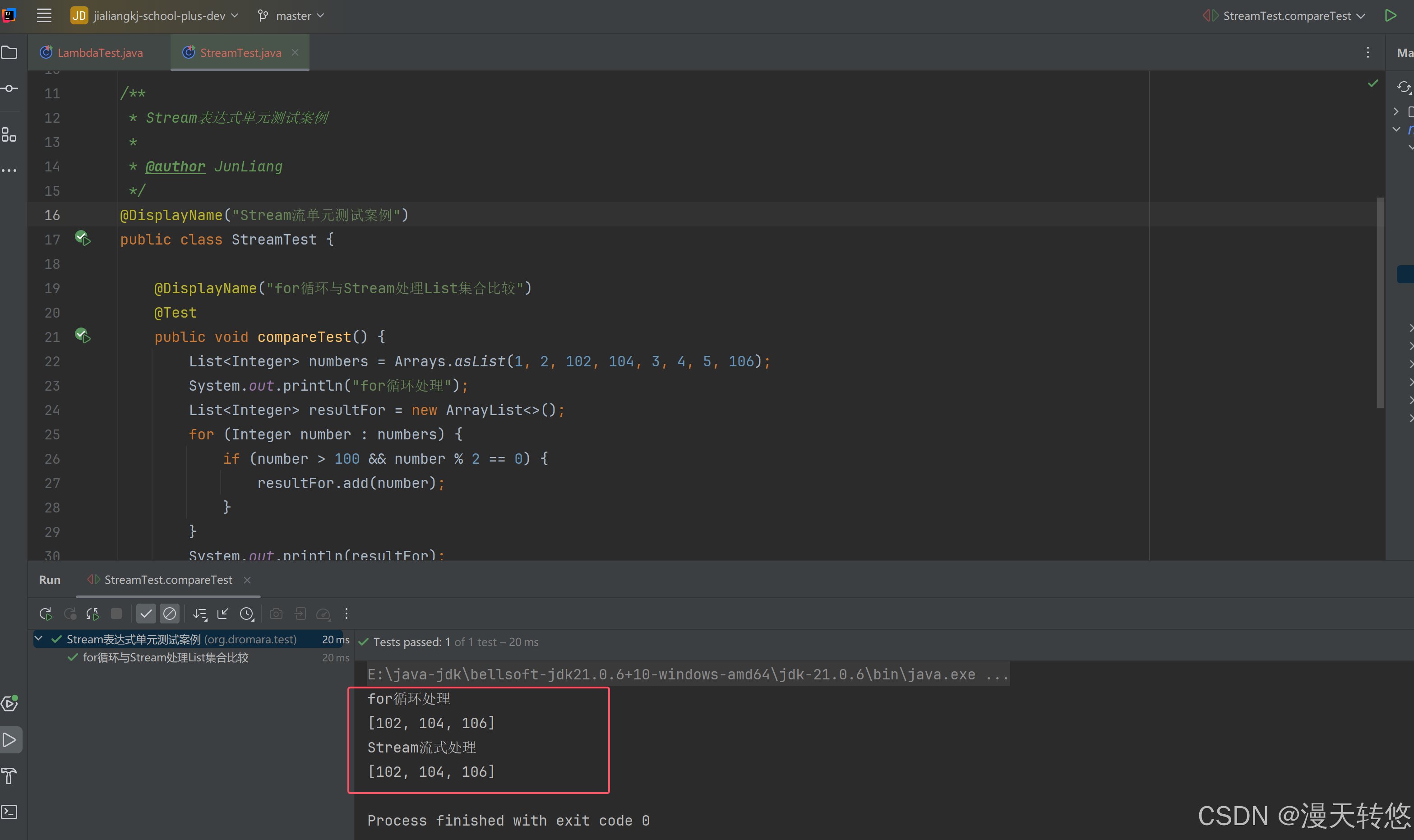
分别使用for循环与Stream流对List集合进行遍历
/**
* Stream表达式单元测试案例
*
* @author JunLiang
*/
@DisplayName("Stream流单元测试案例")
public class StreamTest {
@DisplayName("for循环与Stream处理List集合比较")
@Test
public void compareTest() {
List<Integer> numbers = Arrays.asList(1, 2, 102, 104, 3, 4, 5, 106);
System.out.println("for循环处理");
List<Integer> resultFor = new ArrayList<>();
for (Integer number : numbers) {
if (number > 100 && number % 2 == 0) {
resultFor.add(number);
}
}
System.out.println(resultFor);
System.out.println("Stream流式处理");
List<Integer> resultStream = numbers.stream()
.filter(n -> n > 100)
.filter(n -> n % 2 == 0)
.collect(Collectors.toList());
System.out.println(resultStream);
}
}
处理显示结果一致
传统方法
List<Integer> numbers = Arrays.asList(1, 2, 102, 104, 3, 4, 5, 106);
List<Integer> result = new ArrayList<>();
for (Integer number : numbers) {
if (number > 100 && number % 2 == 0) {
result.add(number);
}
}
Stream API 方法
List<Integer> numbers = Arrays.asList(1, 2, 102, 104, 3, 4, 5, 106);
List<Integer> result = numbers.stream()
.filter(n -> n > 100)
.filter(n -> n % 2 == 0)
.collect(Collectors.toList());
从上述例子可以看出,使用Stream API可以使代码更加简洁和易读。
2 顺序流和并行流
好了,现在我们大概知道Stream流式处理是什么了,在这其中还有分为顺序流和并行流,下面将进行逐一解释。
2.1 Java 8中的顺序流和并行流介绍
顺序流(Sequential Stream)
在Java 8中,顺序流是指按照元素在源集合中的出现顺序逐一处理每个元素的流。顺序流的操作是在单个线程上按顺序执行的,这意味着每一个操作都必须等待前一个操作完成后才能开始。顺序流非常适合那些不需要考虑并发性的小规模数据集或需要保持处理顺序的情况。
示例代码:
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5);
numbers.stream() // 创建顺序流
.filter(n -> n % 2 == 0) // 过滤偶数
.map(n -> n * 2) // 将每个数字乘以2
.forEach(System.out::println); // 输出结果
并行流(Parallel Stream)
并行流则是利用多线程技术同时处理多个元素的流。通过将任务分解为多个子任务并在多个线程上并行执行,可以显著提高处理速度,尤其是在多核处理器上。并行流适合于大规模数据集或者CPU密集型任务。
示例代码:
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5);
numbers.parallelStream() // 创建并行流
.filter(n -> n % 2 == 0)
.map(n -> n * 2)
.forEach(System.out::println);
2.2 原理解析
2.2.1 顺序流原理
顺序流内部使用了链表结构来组织中间操作(如filter, map等),这些操作形成一个链条。当触发终端操作(如forEach, collect等)时,会从头到尾遍历这个链条,对每个元素依次应用所有的中间操作。
2.2.2 并行流原理
并行流基于Fork/Join框架实现。当你创建一个并行流时,实际上是在创建一系列可以在多个线程上并行执行的任务。这些任务被分配给不同的线程,然后由各个线程独立执行。完成之后,结果会被合并起来,形成最终的结果。并行流还采用了工作窃取算法(work-stealing),即空闲线程可以从其他忙碌线程的任务队列尾部“偷取”任务来执行,从而提高了资源利用率。
2.3 性能对比
下面是一个简化的性能对比表格,展示了不同大小的数据集上顺序流和并行流的处理时间(以毫秒为单位)。请注意,实际性能可能会根据硬件配置、JVM版本等因素有所不同。
| 数据集大小 | 顺序流处理时间(ms) | 并行流处理时间(ms) |
|---|---|---|
| 1,000 | 5 | 3 |
| 10,000 | 50 | 15 |
| 100,000 | 500 | 70 |
| 1,000,000 | 5,000 | 500 |
2.4 在实际项目开发中的选择
在实际项目开发中选择顺序流还是并行流应考虑以下几个因素:
-
数据量大小:对于小数据集,顺序流通常更高效,因为启动并行流带来的额外开销可能超过性能提升。对于大数据集,并行流能显著减少处理时间。
-
任务类型:如果任务是CPU密集型且各任务间相互独立,那么并行流可能提供更好的性能。如果是I/O密集型任务,顺序流可能更为合适。
-
线程安全:尽管并行流自身是线程安全的,在涉及共享可变状态时仍需注意同步问题。
-
性能测试:在决定采用哪种方式之前,应该进行性能测试,确保所选方式确实带来预期的性能增益。
例如,如果你正在处理一个包含数百万条记录的大文件,那么并行流可能是加速处理过程的好选择;然而,如果你的工作负载主要是网络请求或者数据库查询等I/O受限的任务,那么顺序流可能更适合,因为它不需要额外的线程管理开销。此外,对于那些依赖于元素处理顺序的应用场景,也需要特别注意,因为并行流并不保证处理顺序。在这种情况下,可能需要使用forEachOrdered()方法来确保顺序输出,但这可能会牺牲一些性能优势。
3 Stream流常见用法
Java 8 中的 Stream API 提供了丰富的操作集合数据的方法,可以极大地简化代码并提高开发效率。以下是一些常用的 Stream 流用法及示例代码,并简要介绍了它们在实际项目中的使用场景。
3.1 创建流
3.1.1 从集合创建流
List<String> list = Arrays.asList("apple", "banana", "cherry");
Stream<String> streamFromList = list.stream();
3.1.2 从数组创建流
String[] array = {"apple", "banana", "cherry"};
Stream<String> streamFromArray = Arrays.stream(array);
3.1.3 使用 Stream.builder创建流
Stream<String> streamFromBuilder = Stream.<String>builder()
.add("apple")
.add("banana")
.build();
3.1.4 无限流
// 使用 generate 创建无限流
Stream<Integer> infiniteStream = Stream.generate(() -> 1).limit(10); // 生成10个1
// 使用 iterate 创建无限流
Stream<Integer> infiniteNumberStream = Stream.iterate(0, n -> n + 2).limit(10); // 生成0到18的偶数
使用场景:当你需要处理列表、集或其他实现了Collection接口的集合时,这是最常用的方式。
3.2 中间操作
3.2.1 过滤(filter)
stream.filter(s -> s.startsWith("a")); // 筛选出以'a'开头的字符串
使用场景:用于筛选出符合条件的数据,如过滤掉无效用户或不符合条件的商品等。
3.2.2 映射(map)
stream.map(String::toUpperCase); // 将所有字符串转换为大写
使用场景:将一种类型的对象转换为另一种类型,例如将用户的ID映射到完整的User对象。
3.2.3 扁平化映射(flatMap)
List<List<Integer>> listOfLists = Arrays.asList(Arrays.asList(1, 2), Arrays.asList(3, 4));
listOfLists.stream().flatMap(Collection::stream).forEach(System.out::println); // 输出: 1 2 3 4
使用场景:当你的数据结构是嵌套的集合时,使用flatMap来扁平化处理。
3.2.4 去重(distinct)
stream.distinct(); // 去除重复元素
使用场景:移除集合中的重复项,比如获取唯一用户ID列表。
3.2.5 排序(sorted)
stream.sorted(); // 自然排序
stream.sorted((s1, s2) -> s2.compareTo(s1)); // 定制排序
使用场景:对数据进行排序,例如按价格降序排列商品列表。
3.3 终端操作
3.3.1 遍历(forEach)
stream.forEach(System.out::println); // 对每个元素执行动作
使用场景:打印输出或者对每个元素执行某些操作。
3.3.2 收集结果(collect)
List<String> result = stream.collect(Collectors.toList()); // 转换为列表
Set<String> resultSet = stream.collect(Collectors.toSet()); // 转换为集合
Map<String, Integer> resultMap = stream.collect(Collectors.toMap(Function.identity(), String::length)); // 转换为映射
使用场景:将流中的元素收集到集合中,如构建报告时汇总数据。
3.3.3 统计(count, min, max)
long count = stream.count(); // 统计元素数量
Optional<String> min = stream.min(String::compareTo); // 获取最小值
Optional<String> max = stream.max(String::compareTo); // 获取最大值
使用场景:统计分析数据,如计算销售额总和或找出最高/最低价格。
3.3.4 归约(reduce)
Optional<String> reduced = stream.reduce((s1, s2) -> s1 + "," + s2); // 字符串连接
int sum = IntStream.range(1, 5).reduce(0, (a, b) -> a + b); // 数字求和
使用场景:对流中的元素进行累积运算,如计算购物车中商品总价。
3.3.5 匹配(anyMatch, allMatch, noneMatch)
boolean anyMatch = stream.anyMatch(s -> s.contains("a")); // 是否有任何一个元素包含'a'
boolean allMatch = stream.allMatch(s -> s.length() == 1); // 是否所有元素长度都是1
boolean noneMatch = stream.noneMatch(s -> s.isEmpty()); // 是否没有空字符串
使用场景:验证数据是否符合特定条件,如检查是否有未完成的任务。
3.3.6 Map集合的操作
3.3.6.1 将Map的值转换为新格式
Map<String, Integer> scores = new HashMap<>();
scores.put("Alice", 85);
scores.put("Bob", 90);
Map<String, Integer> updatedScores = scores.entrySet().stream()
.collect(Collectors.toMap(
Map.Entry::getKey,
entry -> entry.getValue() + 10
));
3.3.6.2 根据值排序Map
Map<String, Integer> sortedByValue = scores.entrySet().stream()
.sorted(Map.Entry.<String, Integer>comparingByValue().reversed())
.collect(Collectors.toMap(
Map.Entry::getKey,
Map.Entry::getValue,
(e1, e2) -> e1,
LinkedHashMap::new
));
3.3.7 分组(Collectors.groupingBy)
分组操作允许根据特定条件对元素进行分组。
Map<Integer, List<String>> groupByLength = Stream.of("a", "bb", "ccc", "dddd")
.collect(Collectors.groupingBy(String::length)); // 按字符串长度分组
3.3.8 分区(Collectors.partitioningBy)
分区是分组的一个特例,它根据布尔表达式的结果将元素分为两组。
Map<Boolean, List<String>> partitionedByLength = Stream.of("a", "bb", "ccc", "dddd")
.collect(Collectors.partitioningBy(s -> s.length() > 2)); // 根据长度是否大于2进行分区
3.3.9 自定义Collector
有时候内置的Collector不能满足需求,可以通过Collector.of()创建自定义的Collector。
Collector<Person, ?, Map<String, List<Person>>> personByCity = Collector.of(
HashMap::new,
(map, person) -> map.computeIfAbsent(person.getCity(), k -> new ArrayList<>()).add(person),
(map1, map2) -> {
map2.forEach((city, persons) -> map1.merge(city, persons, (existing, toAdd) -> {
existing.addAll(toAdd);
return existing;
}));
return map1;
}
);
3.4 注意事项
- 惰性求值:Stream的中间操作不会立即执行,只有在终端操作时才会触发计算。
- 短路操作:像
findFirst这样的短路操作可以在找到所需元素后立即停止遍历,节省资源。 - 避免不必要的对象创建:在循环中创建新的对象可能会导致性能下降,尽量复用对象或使用原始类型流(如
IntStream)。
这些只是Stream API的一部分功能,它还包括更多复杂的操作,如分组、分区等。在实际项目中,Stream API可以用于任何需要高效地处理大量数据的情况,尤其是在处理集合时,能够显著减少样板代码的数量,同时提高了代码的可读性和维护性。例如,在电子商务系统中,可以使用Stream API来过滤产品列表,根据用户偏好推荐商品;在金融系统中,可以用它来处理交易记录,进行数据分析等。
总结
通过以上文章内容,你应该可以大概了解和掌握Stream流的基本概念和用法。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









