






一、简介:
MySQL性能优化是通过各个方面的,不仅仅是优化SQL语句这一方面,而是通过各个方面的优化一些,这样整体性能就会有很明显的提升。
二、优化方式
1、优化数据库的表结构的设计
为什么数据库表结构的设计会影响性能?
字段的数据类型:不同的数据类型的存储和检索方式不同,对应的性能也不同,所以说要合理的选用字段的数字类型,比如说人的年龄用无符号的unsigned tinyint 即可,没必要要用interger
数据类型的长度:数据库最终是写道磁盘上的,所以字段的长度也会影响着磁盘的i/o操作,如果字段的长度很大,那么读取数据也需要很多的I/O所以合理的字段长度也会提升数据库的性能,比如说用户的手机号11位长度,没必要用255个长度。
表的存储引擎:常用的存储引擎有MYLSAM INNODB MEMORY,不同的存储引擎有着不同的特性,所以合理的利用每种春初引擎的长处和优点来提供数据的性能MYLSAM不支持事务,表级锁,但是查询速度快,lnnoDB支持事务,行锁
2、SQL优化
MySQL性能优化的一个重要的手段是对SQL语句的优化,其中最重要的方式就是使用索引。
索引少了查询慢,索引多了占用的内存比较大,执行增删改查的语句的时候需要动态维护索引,影响性能,选择率高且被WHERE频繁引用需要建立B树索引;
一般jion列需要建立索引;复杂文档类型查询采用全文索引效率更好;索引的建立要在查询和DML性能之间取得 平衡;复合索引创建时要注意基于非前导列查询的情况
1、通过慢查询日志发现有效率的SQL
可以通过开启慢查询日志的方式进行定位有问题的SQL
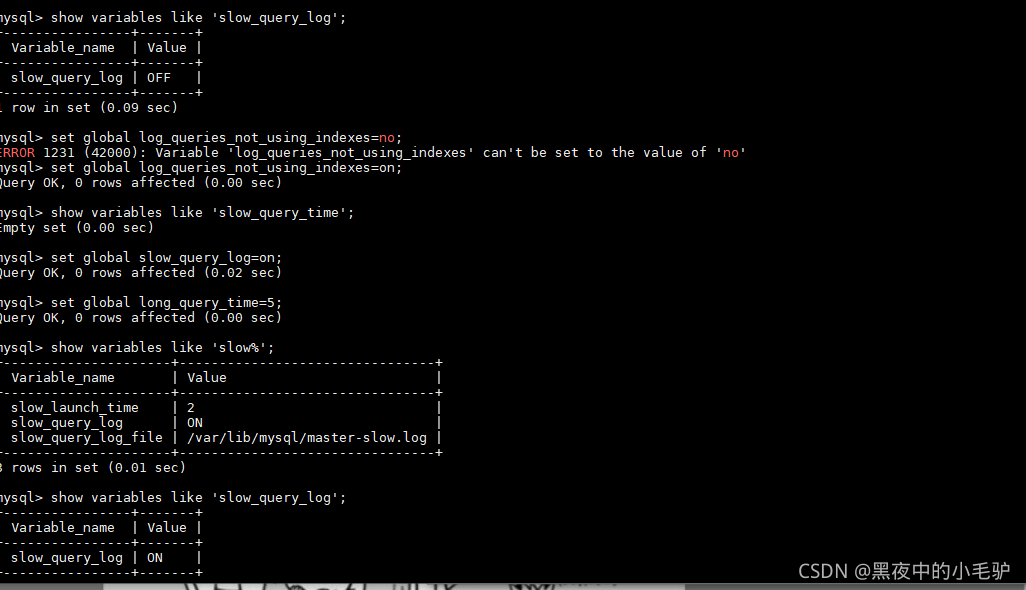
(1)查看MySQL是否开启慢查询日志
(2)设置没有索引的记录到慢查询日志
set global log_queries_not_using_indexes=on;
(3)查看超过多长时间的sql进行记录到慢查询日志
show variables like 'long_query_time‘
(4)开启慢查询日志
set global slow_query_log=on或set global slow-query-log=on
(5)设置超时时间
Set global long_query_time=5;--超过5s的语句才记录日志
(6)查看慢查询日志的位置
show variables like 'slow%'
2、避免select * 写法
执行SQL语句时需要将*转换成具体的列;
3、避免复杂SQL语句
提升可阅读性;避免慢查询的概率,可以转换成多个短查询,用业务端查询
避免where 1=1 写法,避免order by rand()类似写法
rand()导致数据列被多次扫描
4、JION字段建议建立索引 一般的JION字段都是提前加上索引
5、使用UNION ALL 代替UNION
UNION ALL的执行效率比UNION高,UNION执行时需要重新排重;UNION需要对数据进行排序
6、使用连接(JION)来代替子查询(SUB-QUERIES)
使用子查询可以一次性的完成很多的逻辑上需要的多个步骤才能完成的SQL操作,同时也可以避免事务或者事表索斯,并且写起来也很容易,但是,有些情况,子查询更有效的被连接,替代
三、分区
分区就是把一张表的数据分为多个快区,这些块区可以是在一个磁盘上,也可以是在多个磁盘上,分区后,表面上还是一张表,但数据散列在多个位置,这样一来,多块硬盘同样处理不同的请求,从而提高磁盘I/O读写性能,实现比较简单。
什么时候考虑使用分区?
#一张表的查询速度已经慢到影响使用的时候
#SQL经过优化
#数据量大
#表中的数据是分段的
#对数据的操作往往知识设计一部分的数据而不是所有的数据
分区的实现方式很简单
分区解决的问题 主要是可以提升查询效率
CREATE TABLE sales (
id INT AUTO_INCREMENT,
amount DOUBLE NOT NULL,
order_day DATETIME NOT NULL,
PRIMARY KEY(id, order_day)
) ENGINE=Innodb
PARTITION BY RANGE(YEAR(order_day)) (
PARTITION p_2010 VALUES LESS THAN (2010),
PARTITION p_2011 VALUES LESS THAN (2011),
PARTITION p_2012 VALUES LESS THAN (2012),
PARTITION p_catchall VALUES LESS THAN
四、分库
分库是根据业务不同把相关的表切分到不同的数据库中,比如web,bbs blog等库,如果业务量很大,还可以将切分后的库做主从框架,进一步避免单个库的压力过大
什么时候考虑使用分库?
#单台DB的存储空间不够
#随着查询量的增加单台数据库服务器已经没办法支撑
分库解决的问题
其主要的目的是为了突破单节点数据库服务器的I/O能力,解决数据库扩展问题
垂直拆分
将系统中不存在关联关系或者需要JION的表可以放在不同的数据库不用的服务器
按照业务垂直划分,比如:可以按照业务分为资金、会员,订单三个数据库
需要解决的问题;跨数据库的事务、JION查询等问题
水平拆分
例如大部分的站点,数据库都是和用户有关,那么可以更具用户,将数据按照用的水平拆分
按照规则划分,一般水平分库在垂直分库之后,不如每天处理的订单数量是海量的,可以按照一定的规则划分,需要解决的问题:数据路由,组装。
五、分表
当一个表的数据量很大的时候,查询就变得很慢,所以就减少表里的记录是优化的一种方式,这种方式就是将一张表的数据拆分成多个表,这样的每张表的数量就减少了,这样的查询速度就相对的快了一些。
大表对DDL操作有一定的影响,如创建索引,添加字段,修改表结构需要很长的时间锁表,会造成长时间的主从延迟,影响正常的数据操作
什么时候考虑分表?
@一张表的查询速度已经很慢到影响使用的情况
@SQL经过优化
@数据量很大
@当频繁插入或者联合查询时,速度很慢
分表分为垂直拆分和水平拆分:
*垂直拆分:把原来的一个很多的字段的表拆分为多个表,解决表的宽带问题,你可以把不同的字段单独放到表中,也可以把大字段单独的放在一个表中,或者把关联密切的字段放在一个表中
*水平拆分:把原来的一个表拆分很多的表,美国个表的结构都是一样的,解决单表数据量很大的问题。
六、大事务
大事务:运行时间比较长,操作的数据比较多的事务。风险:锁定太多的数据,造成大量的阻塞和锁超时,回滚时所需要时间比较长,执行时间长容易造成主从延迟
避免一次处理太多的数据,移除不必要在书屋中的select操作。
七,数据库参数配置优化
MySQL是一个高度制定化的数据库系统,提供了很多的配置参数,这些参数都有默认值,一般的默认值都不是最佳的配置,一般都需要根据应用程序的特性和硬件情况对MySQL的配置进行调整。
例如:最大连接数默认不能超过一百,即使SQL语句优化的再好,硬件设备再高,当请求超过100时都要等待,着就是配置不合理造成的MySQL不能发挥它的最大能力。
在对于Linux中 查看当前最大连接数:show variables like "max_connections";
登陆自己的MySQL数据库,
设置自己的最大连接数:set GLOBAL max_connections=1000
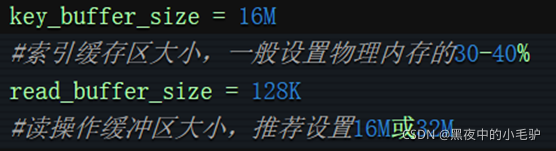
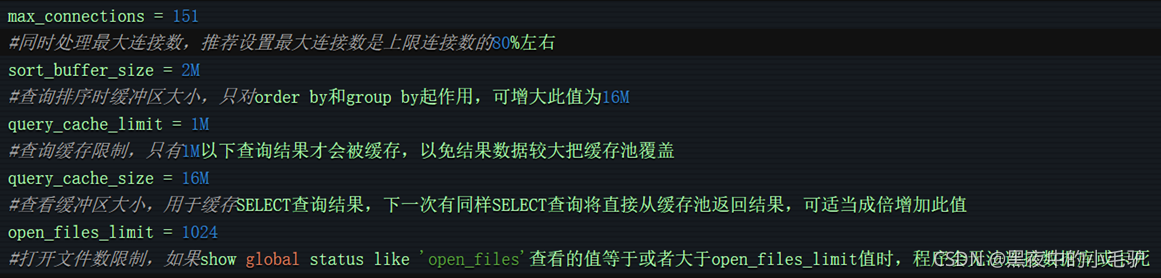
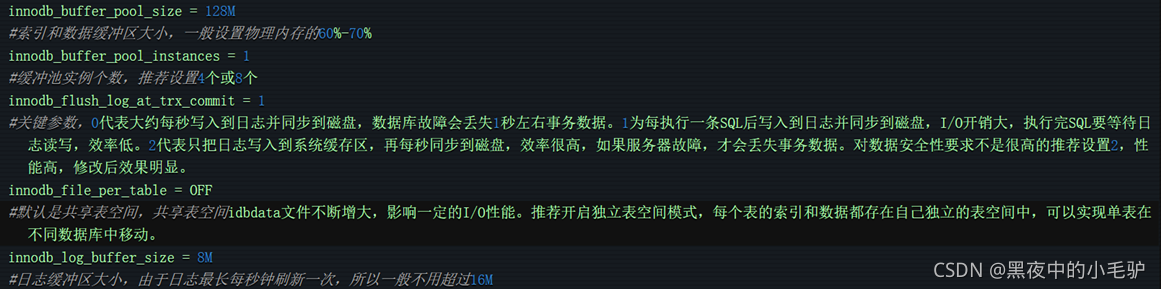
然后数据库在查询最大连接数(很多的MySQL关于优化SQL的配置文件都是在my.cnf中)

八、系统内核优化
大多数的MySQL都是部署在Linux中,所以操作系统的一些参数也会影响到MySQL性能,以下就是对Linux内核进行优化。
首先就是如果进程打开的文件句柄数量超过默认值1024,就会提示“too many files open”的信息,意思就是进程太多,这个时候就需要优化或者调整。

vim /etc/sysctl.conf 很多的优化内核配置文文件都是在这里面
九、主从复制、读写分离
一台mysql服务器同一时间点支持的并发数是有限的,当大量并发时,一台数据库处理不过来,所以增加MySQL的服务器的数量也是一种增强数据库性能的方式
通过MySQL主从复制,增删改master主服务器。查询slaver从服务器,这样就减少了只有一台服务器的压力。
十、增加缓存层
减少数据库连接也是一种优化手段,有些查询可以不用访问数据库,可以通过使用缓存服务器或者redis 、memcache 、 elasticsearch 等增加缓存,减少数据库的连接。
给数据库增加缓存系统,把热数据缓存到内存中,如果内存中有请求的数据就不再区数据库中返回结果,提高读写的性能。
缓存的实现由本地缓存和分布式缓存
本地缓存
将数据缓存到本地的服务器内存或者文件中,速度快,
分布式缓存
可以缓存海量的数据,扩展容易,主流的分布式有memcache redis性能稳定,数据缓存在内存中,速度很快Qps可达8w,如果想持久化就用redis,性能不低于memcached。
工作过程就是;
请求数据——到mecached中间缓存——是否有缓存(有就返回给客户端,不在访问数据库)——没有就访问数据库。
十一、性能状态关键指标
Qps 每秒的查询次数,一台服务器每秒能够处理的查询次数。
TPS 每秒处理的事务数
总结:
总之对于MySQL性能的提升,是通过各个方面的,每个方面都是能够提升的。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









