 MySQL查询排序、锁及数据一致性问题解析
MySQL查询排序、锁及数据一致性问题解析








 本文围绕MySQL展开,介绍了ORDER BY工作原理及优化方案,如建立联合索引;探讨了随机显示结果的方法;分析了函数隐式转换、单行查询过慢、幻读、锁等问题及解决办法;还提及饮鸩止渴的优化方案;最后阐述了binlog和redo log的写入机制及数据一致性机制。
本文围绕MySQL展开,介绍了ORDER BY工作原理及优化方案,如建立联合索引;探讨了随机显示结果的方法;分析了函数隐式转换、单行查询过慢、幻读、锁等问题及解决办法;还提及饮鸩止渴的优化方案;最后阐述了binlog和redo log的写入机制及数据一致性机制。
目录
ORDER BY工作原理
假设有如下建表语句
CREATE TABLE `t` (
`id` int(11) NOT NULL,
`city` varchar(16) NOT NULL,
`name` varchar(16) NOT NULL,
`age` int(11) NOT NULL,
`addr` varchar(128) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `city` (`city`)
) ENGINE=InnoDB;查询的sql如下
select city,name,age from t where city='杭州' order by name limit 1000 ;用explain分析如下
Extra这个字段中的“Using filesort”表示用了排序,mysql会给每个线程分配一个内存用于排序
成为sort_buffer
city索引如下
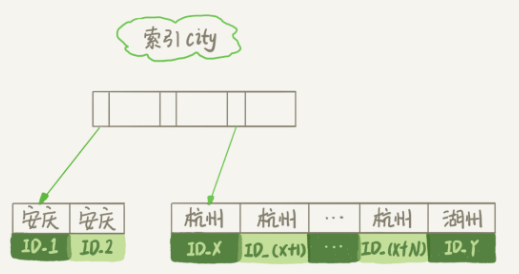
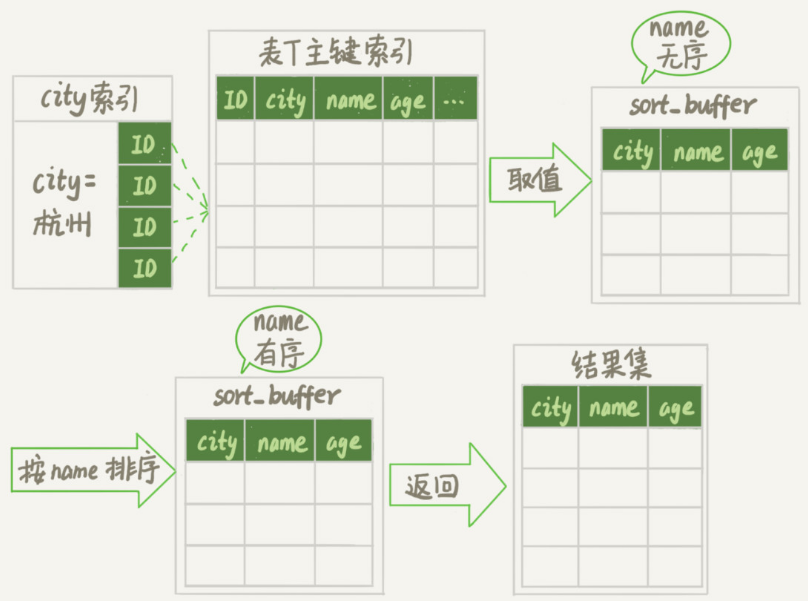
这个语句执行流程如下
1.初始化sort_buffer,确定放入name,city,age三个字段
2.从索引city找到第一个满足city='杭州' 条件的主键id,也就是上图中的ID_X
3.到初见id索引取出正航,取name,city,age三个字段放入sort_buffer中
4.从索引city取下一个记录的主键id
5.重复3,4步直到city的值不满足条件位置,对应的主键id就是图中的ID_Y
6.对sort_buffer中的数据按照字段name做快速排序
7.按照排序结果取前1000行返回给客户端
整个流程执行图如下
sort_buffer_size是mysql为排序开辟的内存,如果排序的数据小于这个值就在内存中完成,否则需要磁盘临时文件辅助排序
可以用下面的方法,检查一个排序语句是否用了临时文件
/* 打开 optimizer_trace,只对本线程有效 */
SET optimizer_trace='enabled=on';
/* @a 保存 Innodb_rows_read 的初始值 */
select VARIABLE_VALUE into @a from performance_schema.session_status where variable_name = 'Innodb_rows_read';
/* 执行语句 */
select city, name,age from t where city='杭州' order by name limit 1000;
/* 查看 OPTIMIZER_TRACE 输出 */
SELECT * FROM `information_schema`.`OPTIMIZER_TRACE`\G
/* @b 保存 Innodb_rows_read 的当前值 */
select VARIABLE_VALUE into @b from performance_schema.session_status where variable_name = 'Innodb_rows_read';
/* 计算 Innodb_rows_read 差值 */
select @b-@a;通过查看看OPTIMIZER_TRACE的结果来确定,可以从number_of_tmp_files 中看到是否使用了临时文件
mysql将排序文件分成了12份,每个单独排序后保存到临时文件中,再把12个文件合并成一个有序的大文件
如果sort_buffer_size 超过了要排序文件数据大小,表示在内存中完成的,number_of_tmp_files就是0
使用row_id排序
增加这个参数
SET max_length_for_sort_data = 16;这段意思是,设置单行长度为16,如果要排序的一行超过了这个值,就需要另一种排序算法
整个执行流程如下:
1.初始化sort_buffer,确定放入两个字段 name和id
2.从索引city知道第一个满足条件city='杭州'条件的主键id,也就是ID_X
3.到主键id索引取出正航,取name,id这两个字段放入sort_buffer中
4.从索引city取下一个记录的主键id
5.重复步骤3,4直到不满足条件位置,对应图中是ID_Y
6.对sort_buffer中的数据按字段name排序
7.遍历排序结果,取前1000行,并按照id的值回到原表中取出city,name,age三个字段返回给客户端
整个流程图如下
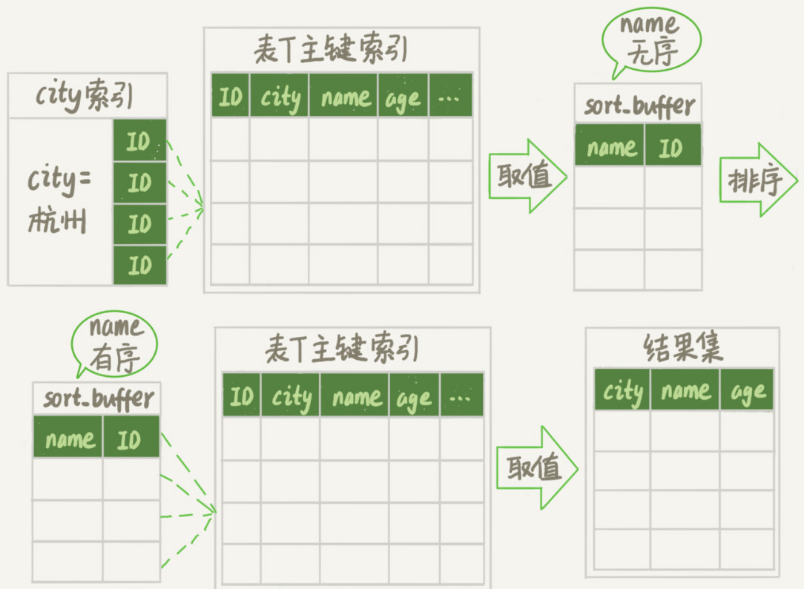
上面这个流程比第一次多了步骤7,需要回表
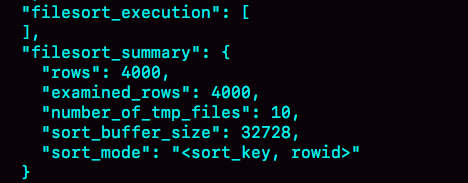
通过trace观察到的结果如下
会多读1000行
sort_mode变成了<sort_key,rowid>表示参与排序的只有name和id两个字段
number_of_tmp_files变成10虽然排序的行是4000,但每行内容变小了
执行的trace图如下
优化方案
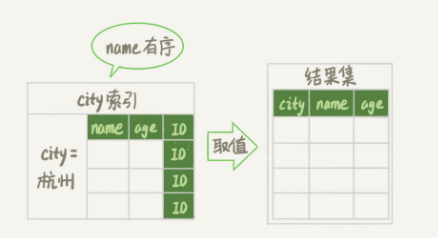
建立联合索引
alter table t add index city_user(city, name);
联合索引如下
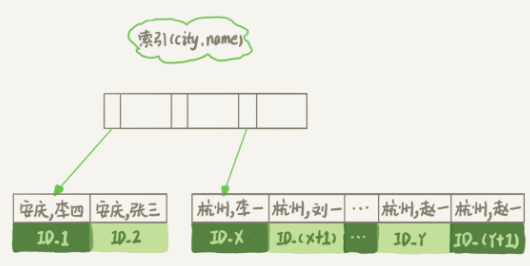
可以看到选中city='杭州'的记录后,name都是排好序的
整个执行流程如下
1.从索引(city,name)找到第一个满足条件的city='杭州'条件的主键id
2.回到主键id取出整行,name,city,age三个字段作为结果返回
3.从索引(city,name)取下一个记录主键id
4.重复步骤2,3 直到第1000条记录或者不满足city是杭州的,结束循环
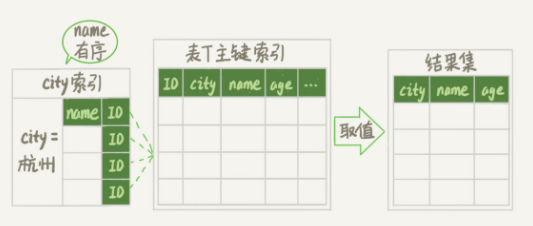
这个过程只需要回表即可,不用排序
还可以再进一步优化
建立一个三个字段的联合索引
alter table t add index city_user_age(city, name, age);
这里就用到了覆盖索引
这次整个执行流程如下
1.从索引(city,name,age)找到第一个满足city='杭州'条件的记录,取出city,name,age三个字段返回
2.从索引(city,name,age)取下一个记录,同样取出这三个字段作为结果集的一部分返回
3.重复步骤2,直到查到第1000条记录或者city不等于杭州结束循环
如何随机的显示结果
一个查询表的随机值的sql
mysql> select word from words order by rand() limit 3;
执行过程如下
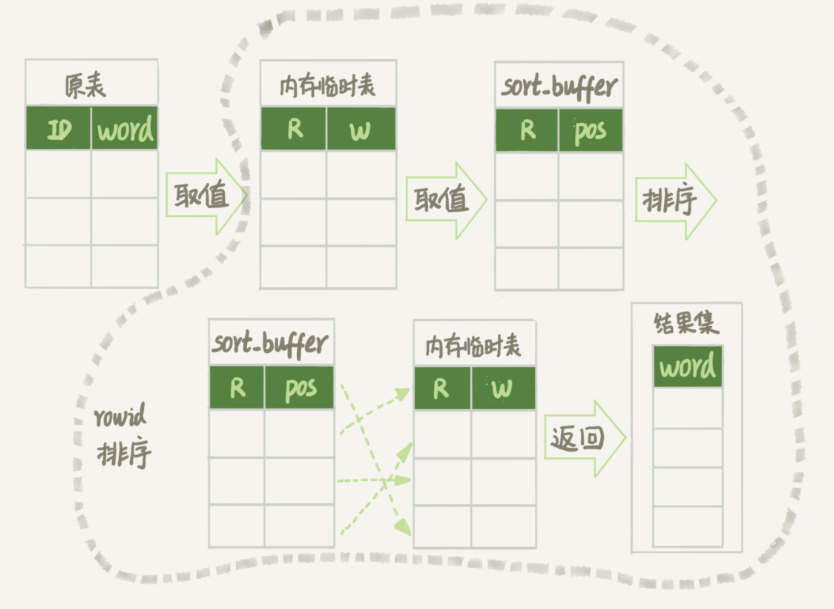
1.创建临时表,用的是menory引擎,这个表有两个字段double,varchar(64)
2.从words表中按主键顺序取出所有的word值,对每个word值调用rand()函数生产一个大于0小雨1的随机数,并把结果放到memory临时表中
3.现在临时表有1W行数据了,接下来在这个没有索引的内存临时表上按照字段double来排序
4.初始化sort_buffer,这个buffer中有两个字段,一个是double类型,一个是整型
5.从内存临时表中一行一行取出double的值和位置信息(系统自动生成的row_id)
6.在sort_buffer中根据double的值排序
7.排序完后根据,取出前三个位置信息,依次到内存临时表中取出word值返回给客户端
整个过程总扫描行数是20003
整个执行流程图如下
内存临时表如果超过 tmp_table_size 的限制,就会使用磁盘临时表
磁盘临时表使用的是InnoDB,参数由internal_tmp_disk_storage_engine 控制的
mysql5.6之后对于sort_buffer的排序用的是堆排序,这里只需要前三个有序就行了,如果是取1000个就变成归并排序了
正确的排序方式
min和max方式
1.取这个表主键id最大值和最小值
2.用随机函数生成一个最大值到最小值之间的数 x = (max-min)*rand()+N
3.取不小于X的第一个ID的行
mysql> select max(id),min(id) into @M,@N from t ;
set @X= floor((@M-@N+1)*rand() + @N);
select * from t where id >= @X limit 1;这个方法的效率很高,但最大值和最小值之间id不连续则每行算出的概率不一样,不是真正的随机
严格随机算法
1.取得整个表的行数,记为C
2.根据相当的随机方法得到Y1,Y2,Y3
3.再执行三个limit Y,1 语句得到三行数据
mysql> select count(*) into @C from t;
set @Y1 = floor(@C * rand());
set @Y2 = floor(@C * rand());
set @Y3 = floor(@C * rand());
select * from t limit @Y1,1; // 在应用代码里面取 Y1、Y2、Y3 值,拼出 SQL 后执行
select * from t limit @Y2,1;
select * from t limit @Y3,1;
函数的隐式转换问题
下面这个sql不会走索引
mysql> select count(*) from tradelog where month(t_modified)=7;如果改成t_modified='2018-7-1' 就会走索引了
下面是索引的示意图
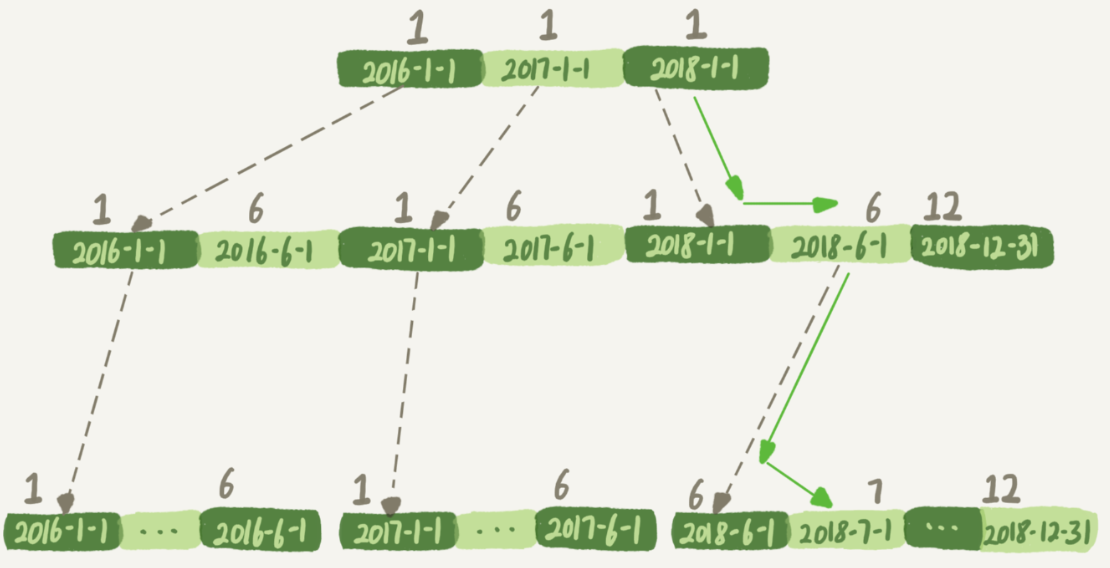
对于普通的t_modified='2018-7-1'会按照上图的箭头路线进行搜索,B+树提供这个快速定位能力,来源于同一层兄弟节点的有序性
如果用month()函数,传入7,树的第一层就不知道该怎么做的
对于索引字段做函数操作,可能会破坏索引值的有序性,因为优化器决定放弃走树搜索功能
虽然放弃了使用搜索功能,但是仍然会用索引,因为mysql比较索引数和主键树,发现用索引树代价更小
但不能再用搜索了,于是遍历了整个索引树

隐式类型转换
mysql> select * from tradelog where tradeid=110717;这个字段本来是字符串类型的,现在要根数字比较,就会走类型转换
这里有个简单的方法,看
SELECT "10" > 9执行结果
如果是 将字符串转换成数字,那么就是做数字比较,结果是1
如果是 将数字转换成字符串,那么就坐字符串比较,结果是0
其实这句相当于
mysql> select * from tradelog where CAST(tradid AS signed int) = 110717;这里也把索引树全部扫一遍
隐式字符编码转换
下面sql
mysql> select d.* from tradelog l, trade_detail d where d.tradeid=l.tradeid and l.id=2; /* 语句 Q1*/执行过程
1.根据id在tradelog表里面找到L2这一行
2.从L2中取出tradid字段的值
3.根据tradeid值到trade_detail表中查到条件匹配的行,这里有索引但没用上
执行过程如下
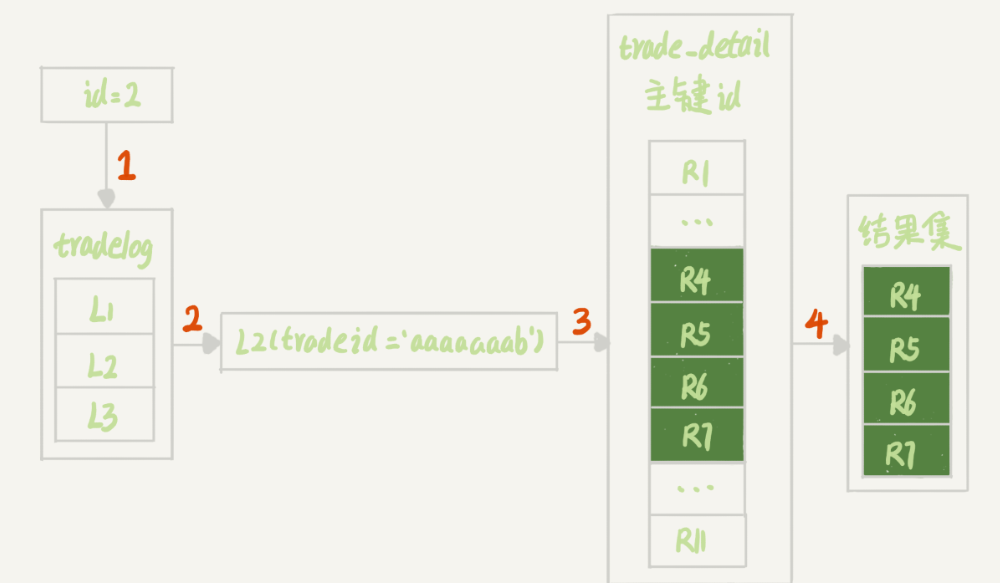
问题出在第三步
mysql> select * from trade_detail where tradeid=$L2.tradeid.value; L2.tradeid.value的字符集是uft8mb4,是UTF-8的超集
相当于执行了下面这个语句
select * from trade_detail where CONVERT(traideid USING utf8mb4)=$L2.tradeid.value; 这是在连接过程中要求在被驱动的表的索引字段上加函数操作导致的,索引不会用到,会扫描整个索引树
解决办法
1.把trade_detail表上的tradeid字段字符集也改成utf8mb4,这样就没有字符集转换的问题了
alter table trade_detail modify tradeid varchar(32) CHARACTER SET utf8mb4 default null;2.如果数据量太大不方便改,就只能修改sql
mysql> select d.* from tradelog l , trade_detail d where d.tradeid=CONVERT(l.tradeid USING utf8) and l.id=2; 这里主动将l.tradeid转换成utf-8,避免了被夅表上的字符编码转换问题,这样就可以利用索引了
单行查询过慢的问题
等待MDL锁
通过show processlist命令可以查看等待table metadata lock的任务
有一个线程正在表t上请求或者持有MDL写锁,把select语句给堵住了
解决办法是找到是谁持有MDL写锁,然后将其kill掉
MySql启动时开启performance_schema=on,会将一些信息记录到系统表中
再查询 performance_schema和sys库可就可以了
比如查询
select blocking_pid from sys.schema_table_lock_waits
找到直接造成阻塞的process id,然后将其kill掉
等待flush
有一个线程正在flush 表时也会出现阻塞的情况
flush tables t with read lock;
flush tables with read lock;
通过show processlist命令可以查看到

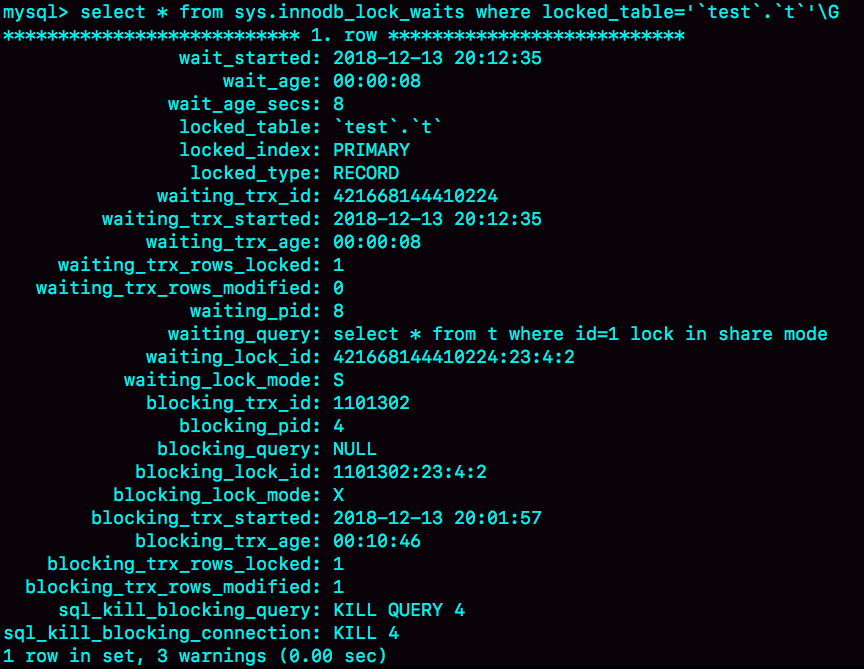
等行锁
通过下面命令查询是谁占有这个写锁
mysql> select * from t sys.innodb_lock_waits where locked_table=`'test'.'t'`\G
查询结果如下
慢查询
下面这个sql会很慢,需要扫描50000行,因为c这个字段上没有索引,只能走id主键顺序扫描
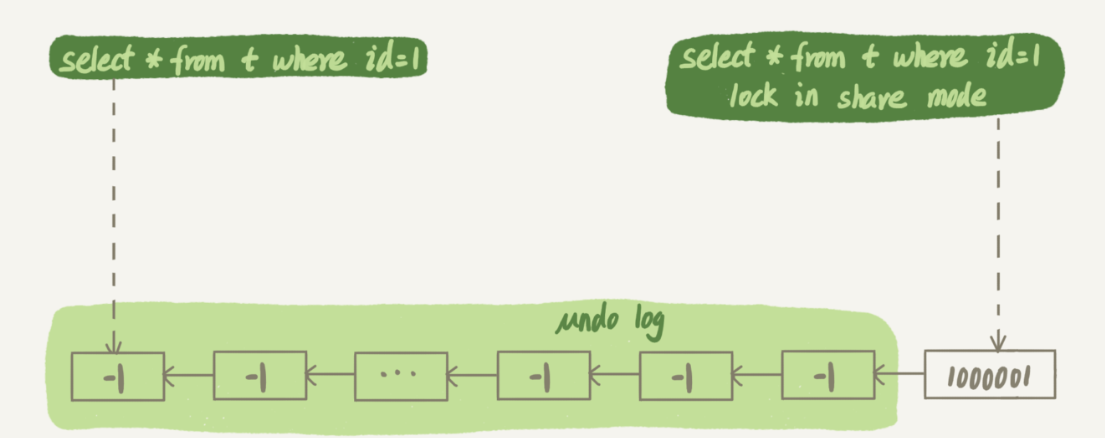
mysql> select * from t where c=50000 limit 1;下面第一个sql执行时间很长,第二个加共享锁的反而执行的很快
mysql> select * from t where id=1;
mysql> select * from t where id=1 lock in share mode事务A对某个字段更新了10000次,用普通的读需要往前回溯10000次,而共享锁是当前读所以很快
幻读
幻读:指一个线程中的事务读取到了另外一个线程中提交的insert的数据
隔离级别:
| 隔离级别 | 脏读(Dirty Read) | 不可重复读(NonRepeatable Read) | 幻读(Phantom Read) |
|---|---|---|---|
| 未提交读(Read uncommitted) | 可能 | 可能 | 可能 |
| 已提交读(Read committed) | 不可能 | 可能 | 可能 |
| 可重复读(Repeatable read) | 不可能 | 不可能 | 可能 |
| 可串行化(Serializable ) | 不可能 | 不可能 | 不可能 |
假设有三个事务
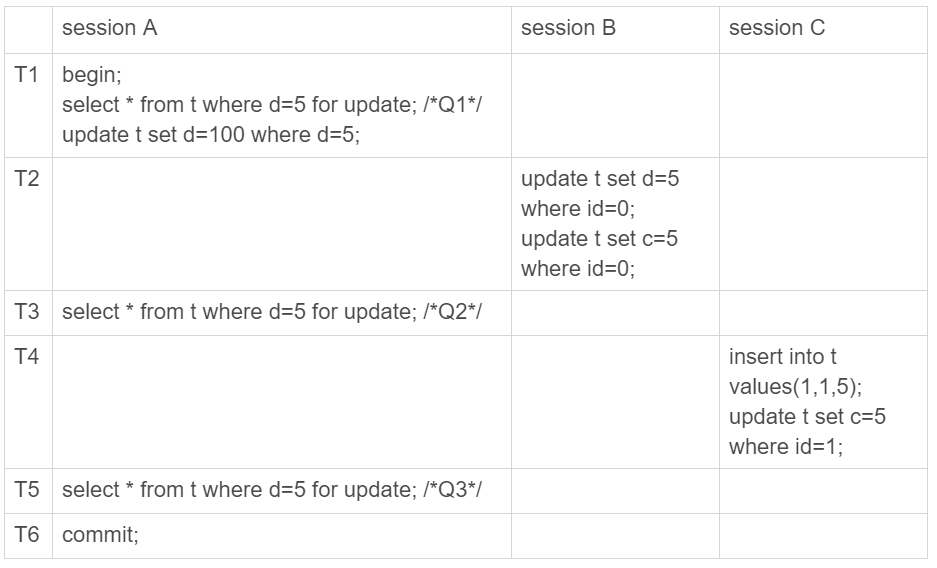
上图的执行结果
- 经过T1时刻,id=5这一行变成(5,5,100),最终在T6时刻正式提交
- 经过T2时刻,id=0这行变成(0,0,5)
- 经过T4时刻,表里多了一行(1,5,5)
- 其他杭根这个执行序列无关,保持不变
再看binlog里面的内容
- T2时刻,session B提交事务,写入两条语句
- T4时刻,session C提交事务,写入两条语句
- T6时刻,session A提交事务,写入了update t set d=100 where d=5这条语句
统一放在一起就是
update t set d=5 where id=0; /*(0,0,5)*/
update t set c=5 where id=0; /*(0,5,5)*/
insert into t values(1,1,5); /*(1,1,5)*/
update t set c=5 where id=1; /*(1,5,5)*/
update t set d=100 where d=5;/* 所有 d=5 的行,d 改成 100*/数据不一致是因为
select * from t where d=5 for update
这条语句只给d=5这一行,也就是id=5的这一行加锁导致的
假设把扫描过程中碰到的行都加上写锁,那么最终binlog中的数据如下
insert into t values(1,1,5); /*(1,1,5)*/
update t set c=5 where id=1; /*(1,5,5)*/
update t set d=100 where d=5;/* 所有 d=5 的行,d 改成 100*/
update t set d=5 where id=0; /*(0,0,5)*/
update t set c=5 where id=0; /*(0,5,5)*/但新插入的(1,5,5)还是无法解决,因为加锁无法解决新插入的数据
为了解决幻读,mysql引入了间歇锁
插入6条记录,会产生7个间歇锁
insert into t values(0,0,0),(5,5,5),
(10,10,10),(15,15,15),(20,20,20),(25,25,25);

间歇锁也会带来一些问题,假设下面sql
begin;
select * from t where id=N for update;
/* 如果行不存在 */
insert into t values(N,N,N);
/* 如果行存在 */
update t set d=N set id=N;
commit;假设N=9,执行过程如下图

执行过程分析
- session A执行select ... for update语句,由于id=9这一行不存在,会加上间歇锁(5,10)
- session B执行select .. for update,同样会加上间歇锁(5,10),间歇锁之间不会冲突
- session B试图插入一行(9,9,9) 被session A的间歇锁挡住了,进入等待状态
- session A试图插入一行(9,9,9) 被sesion B的间歇锁挡住了
InnoDB检测出死锁,让session A的insert语句报错返回了
间歇锁的引入,可能会导致同样的语句锁住更大的范围,这其实是英雄了并发度的
间歇锁是在可重复读隔离级别下才会生效的,如果把隔离级别设置为 读提交的话,就没有间歇锁了,如果业务上支持可以修改隔离级别解决这个问题
锁问题分析
。。。
饮鸩止渴的优化方案
短连接太多会出现max_connections错误,直接调大并不合适
通过show processlist的结果,kill掉那么显示为sleep的线程
如果连接数过多,优先断开事务外空闲太久的连接,再考虑断开事务内空闲太久的连接
执行命令
kill connection + id
客户端不会马上知道,等客户端下次执行后才会收到通知,但这个方案是有损的,如果客户端没做重试处理会一直用这个连接,导致看起来是mysql一直没恢复
增加 -skip-grant-tables 参数,这样每个连接就不会做验证了,可以减少验证的消耗
但这样非常不安全
索引没设计好,
- 在备库上执行 set sql_log_bin=off,再alter table加上索引
- 主备切换
- 这时候B是主库,在A库再执行sql_log_bin=off,然后alter table加索引
这种方案很古老,但应该考虑gh-ost这样的方案,但这个方案效率最高
语句没写好
通过mysql5.7提供的query_rewrite功能,把输入的语句改写成另外一种模式
比如语句写错了
select * from where id+1 = 10000
mysql> insert into query_rewrite.rewrite_rules(pattern, replacement, pattern_database) values ("select * from t where id + 1 = ?", "select * from t where id = ? - 1", "db1");
call query_rewrite.flush_rewrite_rules();mysql用错索引
这时候用 force index强制指定用某个索引即可
可以用pt-query-digest 工具,检查所有的SQL语句返回结果
QPS突增
- 如果是全新业务bug导致的,可以从数据库端将这个用户名加入白名单
- 或者将这个用户删除,因为其他业务可能会重用同样的模板,1和2可能会导致误伤
- 把压力最大的SQL直接重写为select 1返回,但这个可能会影响业务逻辑,是有损的
数据一致性的机制
binlog写入机制
系统给binlog cache分配一片内存,每个线程一个,参数binlog_cache_size控制,如果超过这个大小就要暂存到磁盘
事务提交的时候,执行器把binlog_cache里完整的事务写入到binlog中,并清空binlog cache,整个执行过程如下
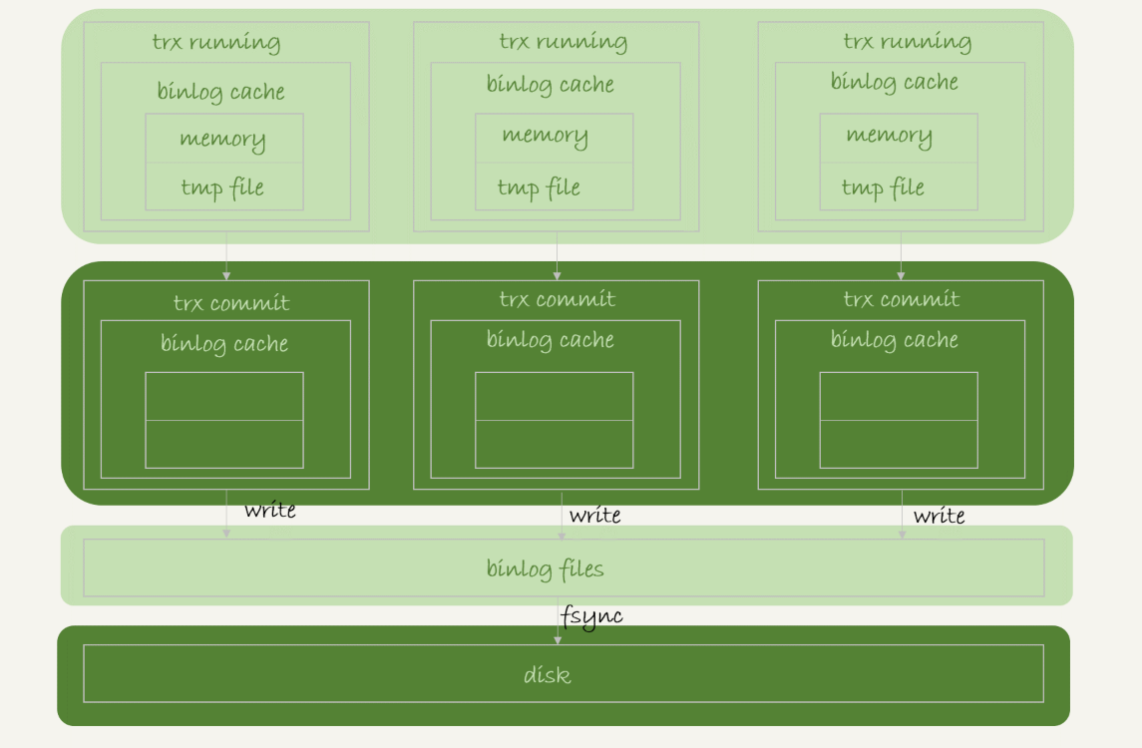
上图中的write,是指把日志写入到文件系统的page cache,并没有把数据持久化到磁盘
途中的fsync,才是将数据持久化到磁盘,所以fsync才占磁盘的IOPS
write和fsync的时机,是由参赛sync_binlog控制的
- sync_binlog=0,表示每次提交事务只write,不fsync
- sync_binlog=1,表示每次提交事务都会执行fsync
- sync_binlog=N(N>1)的时候,表示每次提交事务都write,但累积N个事务后才fsync
redo log的写入机制
redo log对应三种状态如下图
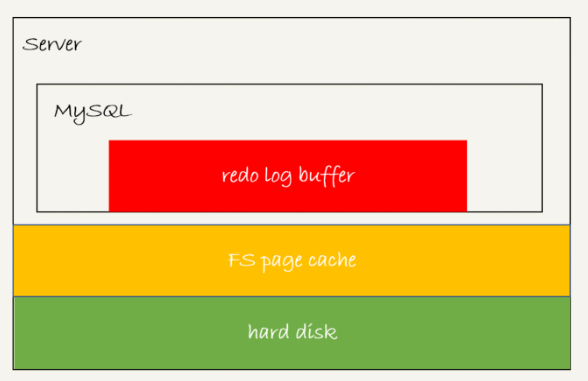
这三种状态分别是
1.存在redo log buffer中,物理上是在mysql进程内存中,对应图中红色部分
2.磁道磁盘,但没有持久化,物理上是在文件系统的page cache中,对应图中黄色部分
3.持久化到磁盘,对应的是hard disk,对应图中绿色部分
为了控制redo log的写入策略,InnoDB 提供了innodb_flush_log_at_trx_commit 参数
1.设置为0,表示每次事务提交时都只把redo log刘在redo log buffer中
2.设置为1,表示每次事务提交时都将redo log直接持久化到磁盘
3.设置为2,表示每次事务提交时都只是把redo log写入到page cache
InnoDB有一个后台线程,每隔1秒,就会把redo log buffer中的日志写入到page cache,在fsync到磁盘
一个没有提交事务的redo log也可能持久化到磁盘
比如redo log buffer 达到 innodb_log_buffer_size 一半时后台线程会写磁盘
并行事务提交的时候,会顺带将这个事务的redo log buffer持久化到磁盘
MySql中的双1,指的是sync_binlog和innodb_flush_log_at_trx_commit都设置为1
也就是一次完整的事务提交前,需要等待两次刷盘,一次redo log(prepare阶段),一次binlog
mysql为了提高TPS的性能,用了组提交的概念
下图是三个并发事务(trx1,trx2,trx3)在prepare阶段,都写完了redo log buffer,持久化到磁盘的过程,LSN分别是50,120,160
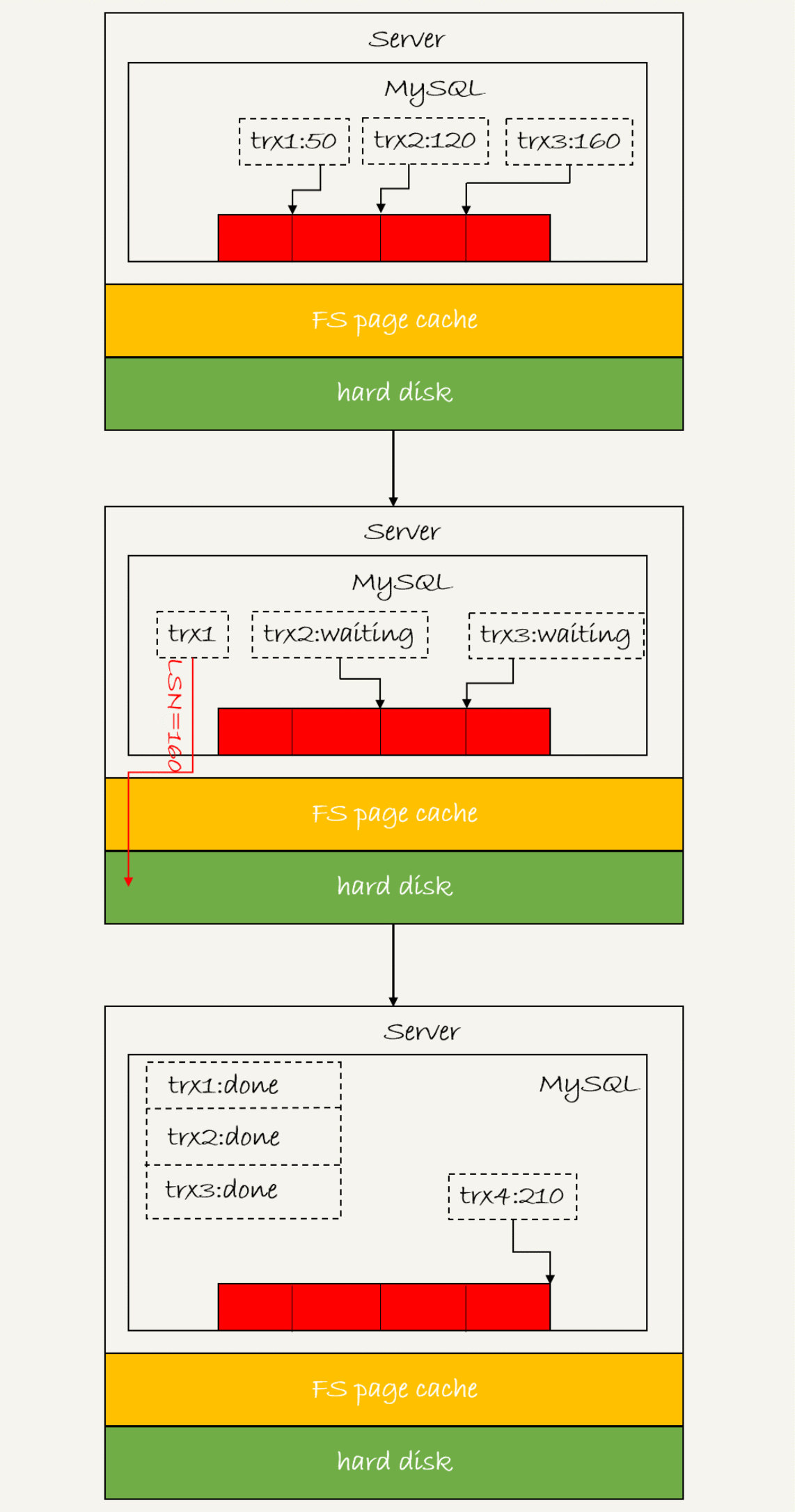
上图中
1.trx1是第一个达到的,是这组的leader
2.等trx1要开始写盘时,这个组里面有三个事务,这时候LSN变成160
3.trx1去写盘时,带的就是LSN=160,因此等trx1返回时,所有LSN小于等于160的redo log都已经被持久化到磁盘
4.这时候trx2和trx3就可以直接返回了
所以一次提交里面,组成员越多,节约磁盘IOPS的效果越好
原先的两阶段提交是下图模式
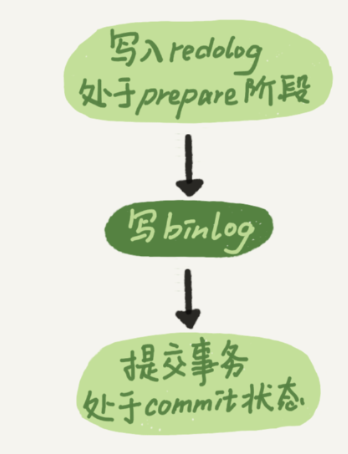
mysql为了让组提交的效果更好,把redo log做fsync的时间拖到了步骤1之后,所以实际的两阶段(redo log+binlog)提交应该如下
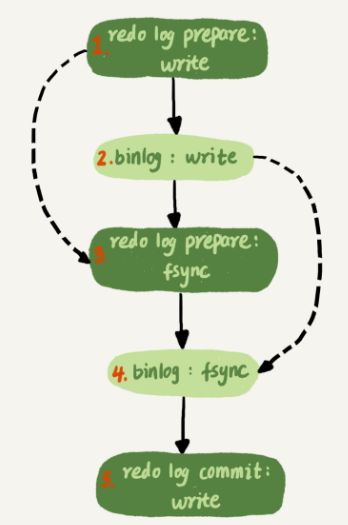
通常第三步会比较快,所以binlog的write和fsync时间间隔短,如果想提升binlog组提交效果,可以设置
binlog_group_commit_sync_delay 和 binlog_group_commit_sync_no_delay_count
1.binlog_group_commit_sync_delay 表示延迟多少微秒后调用fsync
2.binlog_group_commit_sync_no_delay_count 表示累计多少次后才调用fsync
两个条件是 或 的关系
WAL机制主要得益于两个方面
1.redo log和binlog都是顺序写,磁盘的顺序写比随机写速度快
2.组提交机制,可以大幅度降低磁盘的IOPS消耗
如果mysql出现性能瓶颈,并且瓶颈在IO上,可以做如下调整
1.调整binlog的两个延迟参数,减少binlog的写盘次数,这个方法基于额外的故意等待,会增加响应时间但没有丢数据风险
2.将sync_binlog设置为大于1的值(常见的是100-1000),这样做的风险是掉电时会丢binlog
3.将innodb_flush_log_at_trx_commit设置为2,风险是主机掉电时会丢数据

















 1443
1443

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









