




 本文详细解析了NvidiaVolta/Turing架构中TensorCore如何加速矩阵计算,包括混合精度处理、load操作、MMA指令、寄存器共享、threadgroup和OCTET等概念的应用。
本文详细解析了NvidiaVolta/Turing架构中TensorCore如何加速矩阵计算,包括混合精度处理、load操作、MMA指令、寄存器共享、threadgroup和OCTET等概念的应用。
目录
1. 指令与架构
2. Load
3. 计算MMA
4. Set, Step 与thread group
5. OCTET
6. Tensor Core微架构
7. Final
Nvidia自从Volta/Turing(2018)架构开始,在stream multi processor中加入了tensor core,用于加速矩阵计算。如下图所示,其中每个SM有两个tensor core。相信大家也看了这个图很多次,那么一个tensor core里面的64个绿色小格子代表的是什么级别的计算呢?
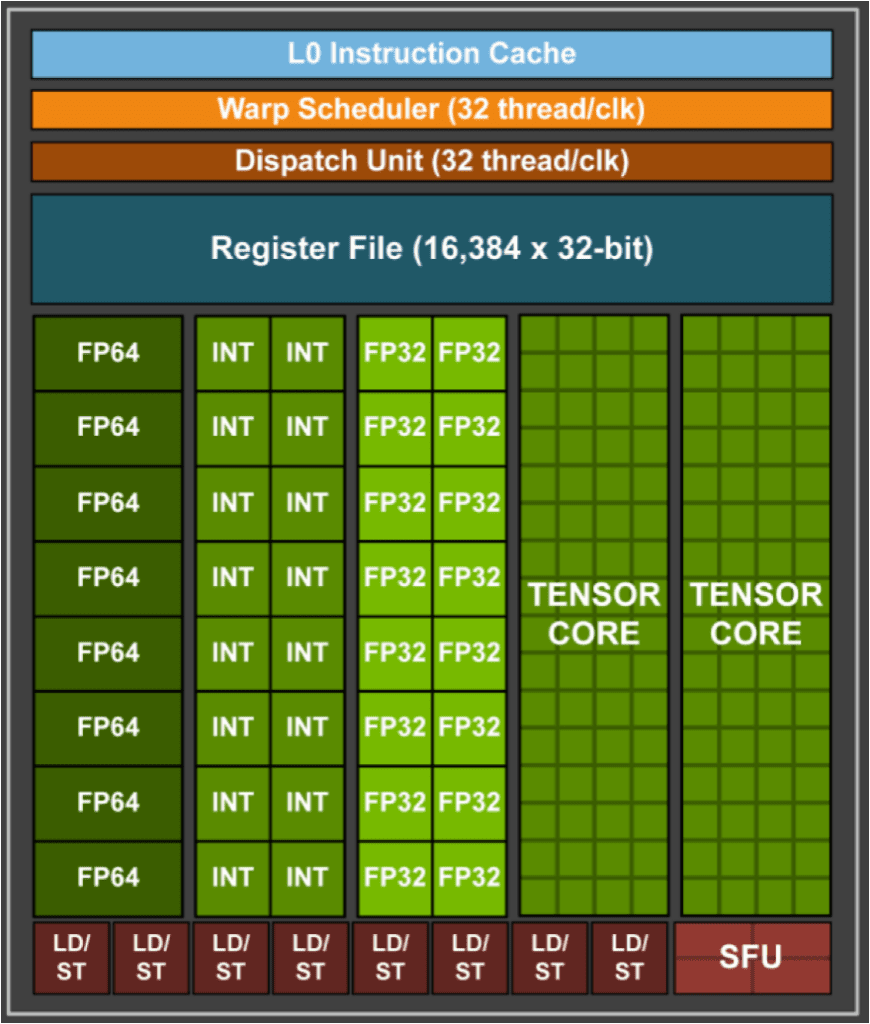
图自[3]
指令与架构
Tensor core支持mixed precision和FP16矩阵计算:D = A x B + C. mixed precision指的是 A和B为FP16,但是C和D为FP32或FP16.
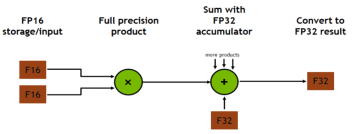
CUDA9.0支持的最小矩阵乘法为16x16x16(不是一个周期就能计算完毕的),下图所示为Tensor Core load A, B, C,进行mma(matrix multiply-accumulate),而后store结果D的PTX指令,其中每个指令都有sync,用于进行warp-wide的同步。

Tensor Core PTX指令
Volta的每个SM core内部有两个tensor core,每个Tensor Core每个周期可以完成一个 4x4x4的MACC操作,如下图所示:
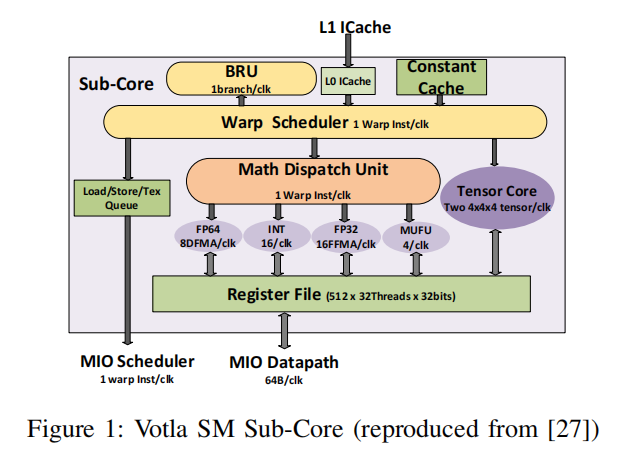
这里的4x4x4指的是A
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 525
525

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









