



免责声明
本博客文章仅供教育和研究目的使用。本文中提到的所有信息和技术均基于公开来源和合法获取的知识。本文不鼓励或支持任何非法活动,包括但不限于未经授权访问计算机系统、网络或数据。
作者对于读者使用本文中的信息所导致的任何直接或间接后果不承担任何责任。包括但不限于因使用本文所述技术而可能导致的法律诉讼、财产损失、隐私泄露或其他任何形式的责任。
在进行任何渗透测试或安全研究之前,请确保您已获得所有必要的授权,并遵守适用的法律和道德准则。未经授权的安全测试可能违反法律,并可能导致严重的法律后果。
本文中的内容仅供参考,不应被视为专业建议。在进行任何安全相关活动之前,建议咨询具有相应资质的专业人士。
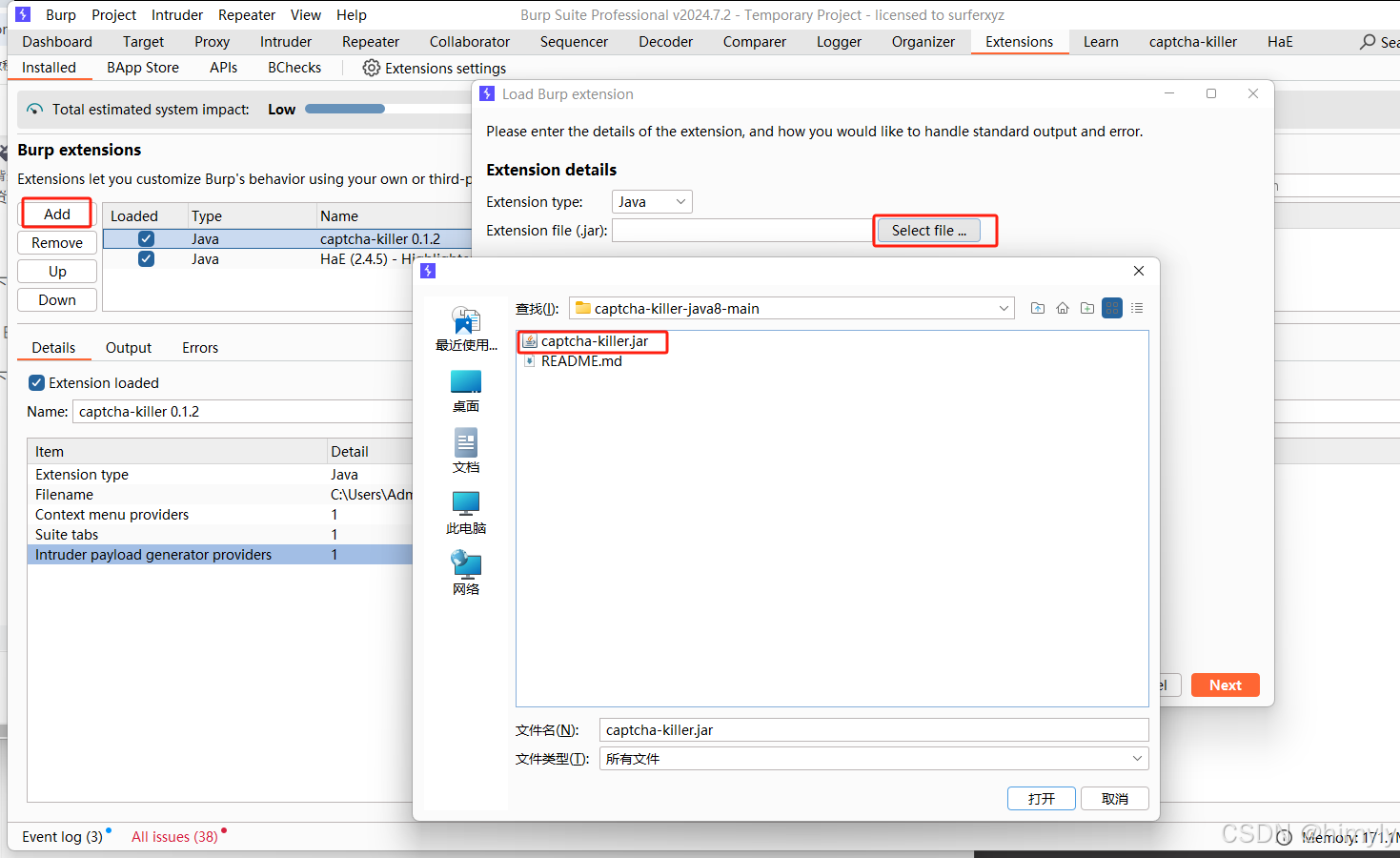
下载bp,我用的是2024.7.2
![]()
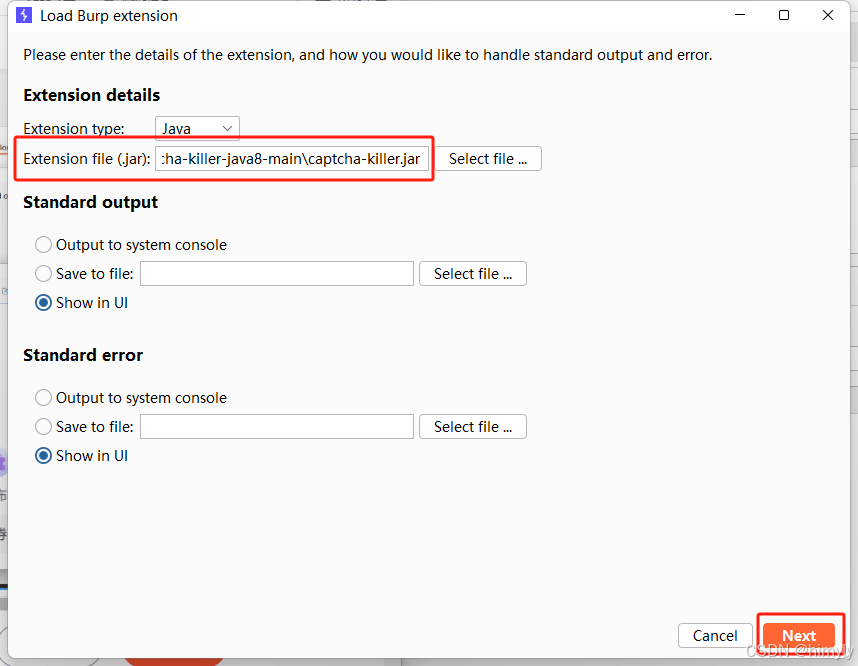
下载插件,打开bp安装插件
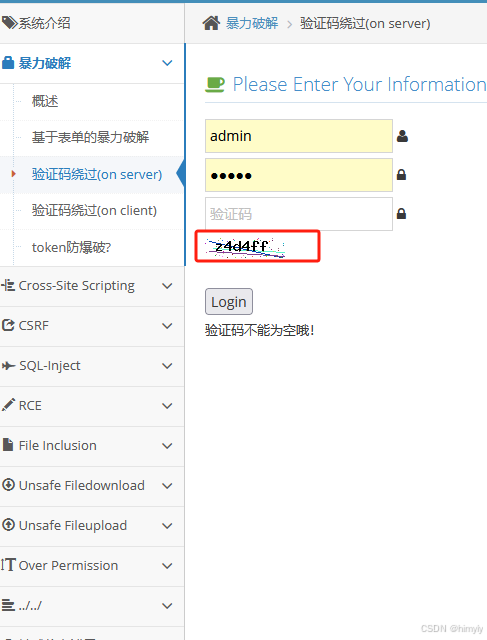
访问pikachu网站的暴力解第二关,点击图片,刷新验证码
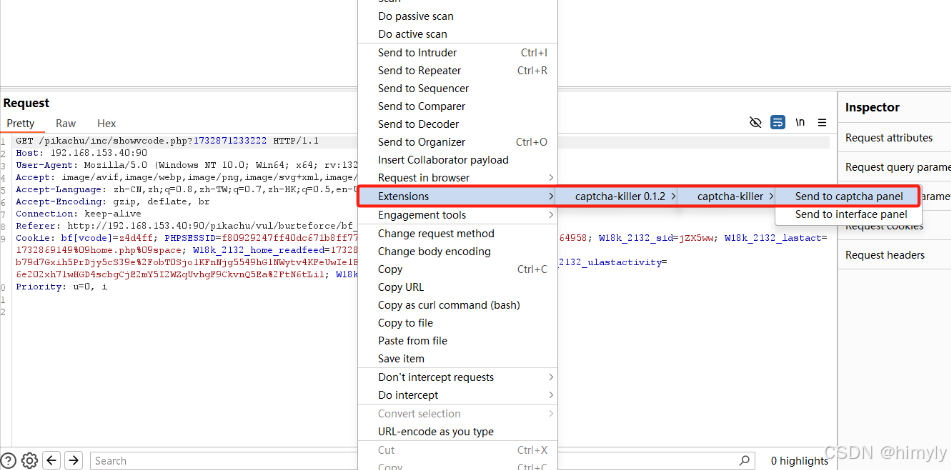
打开bp抓包并发送给captcha-killer模块
进入captcha-killer模块,点击获取就会显示右边的验证码
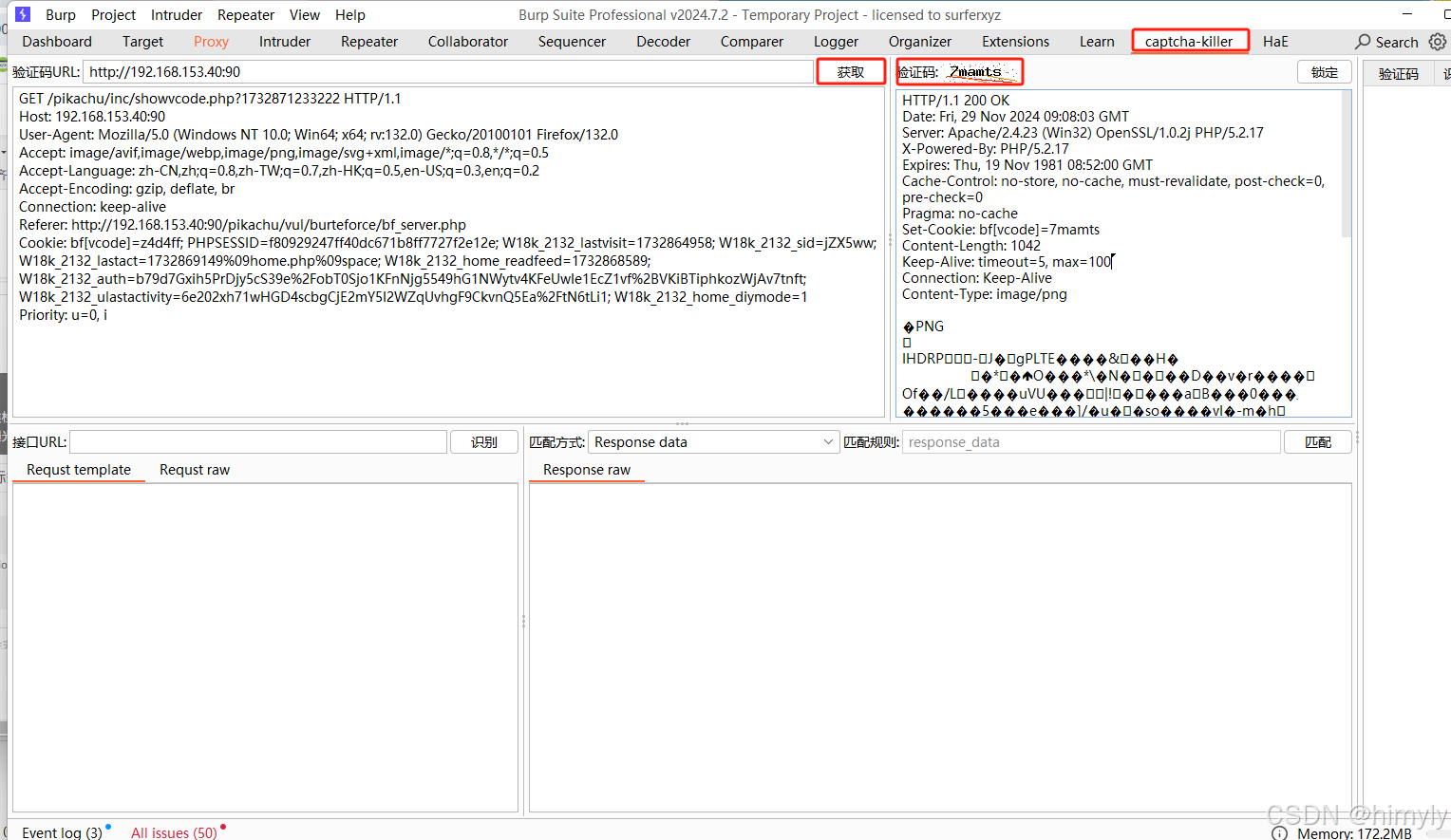
使用模板库中的百度模版
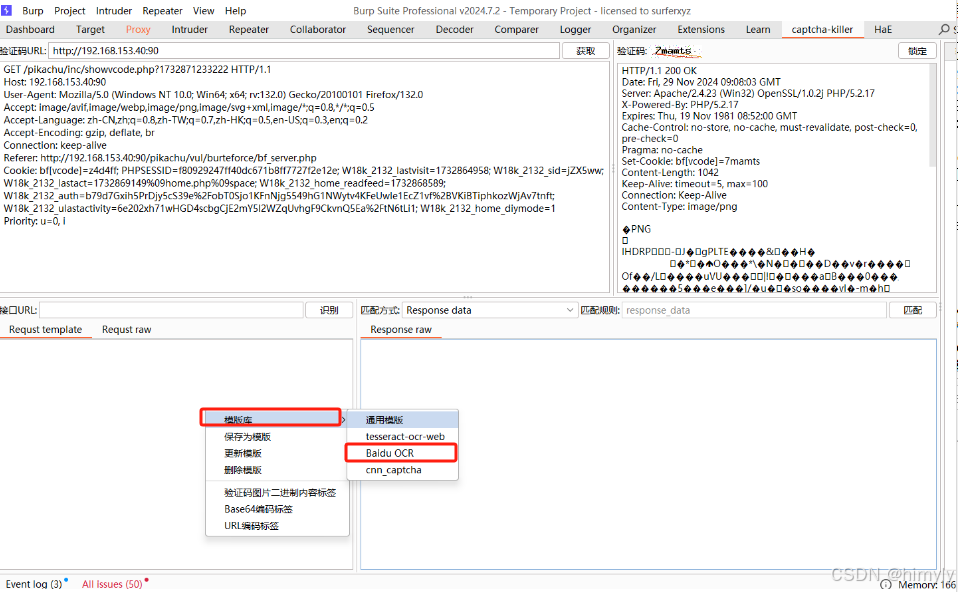
我们可以看到里面有个[token]
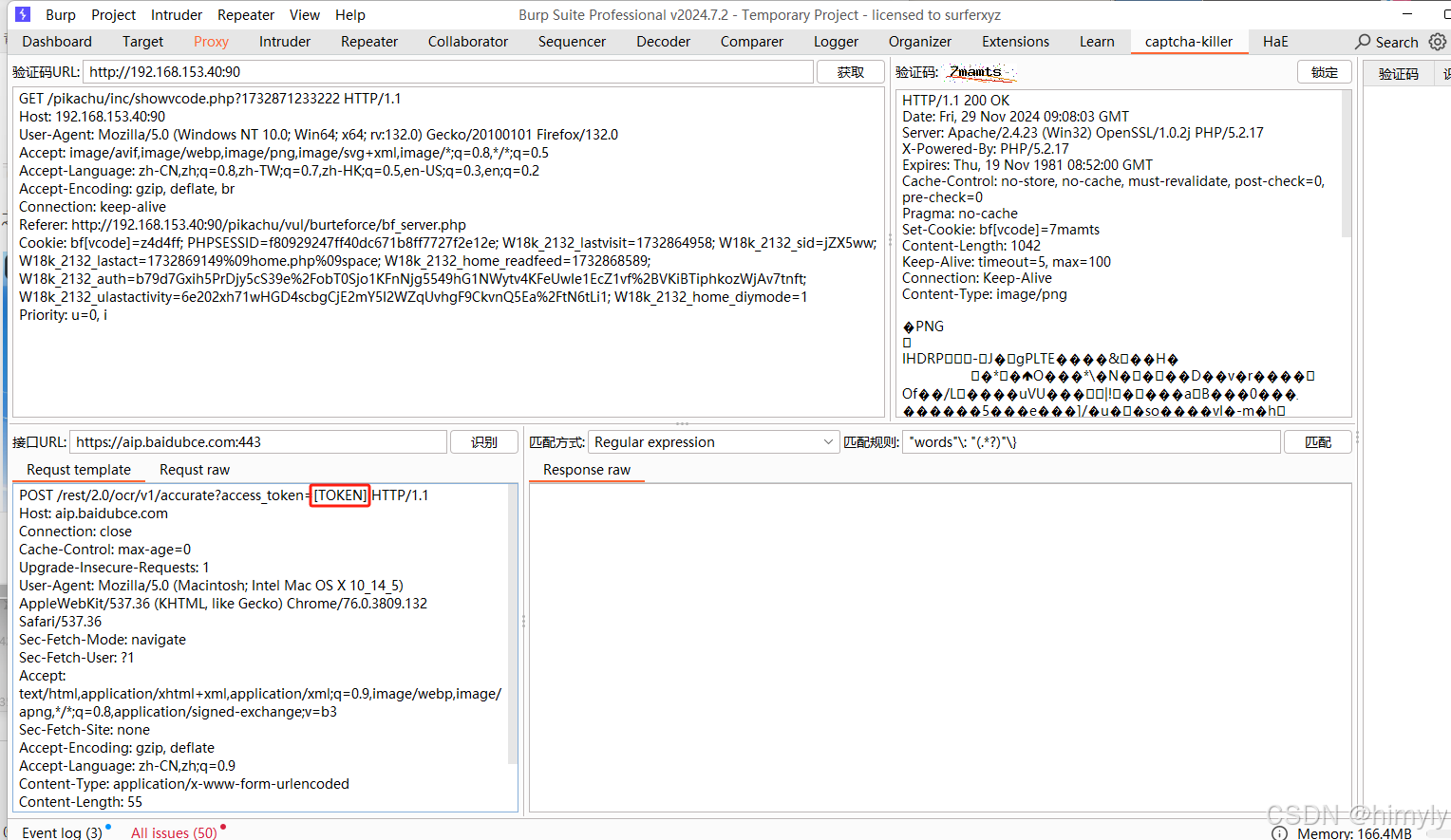
之后我们需要去百度智能云注册用户:百度智能云-登录,然后进入主页操作以下步骤
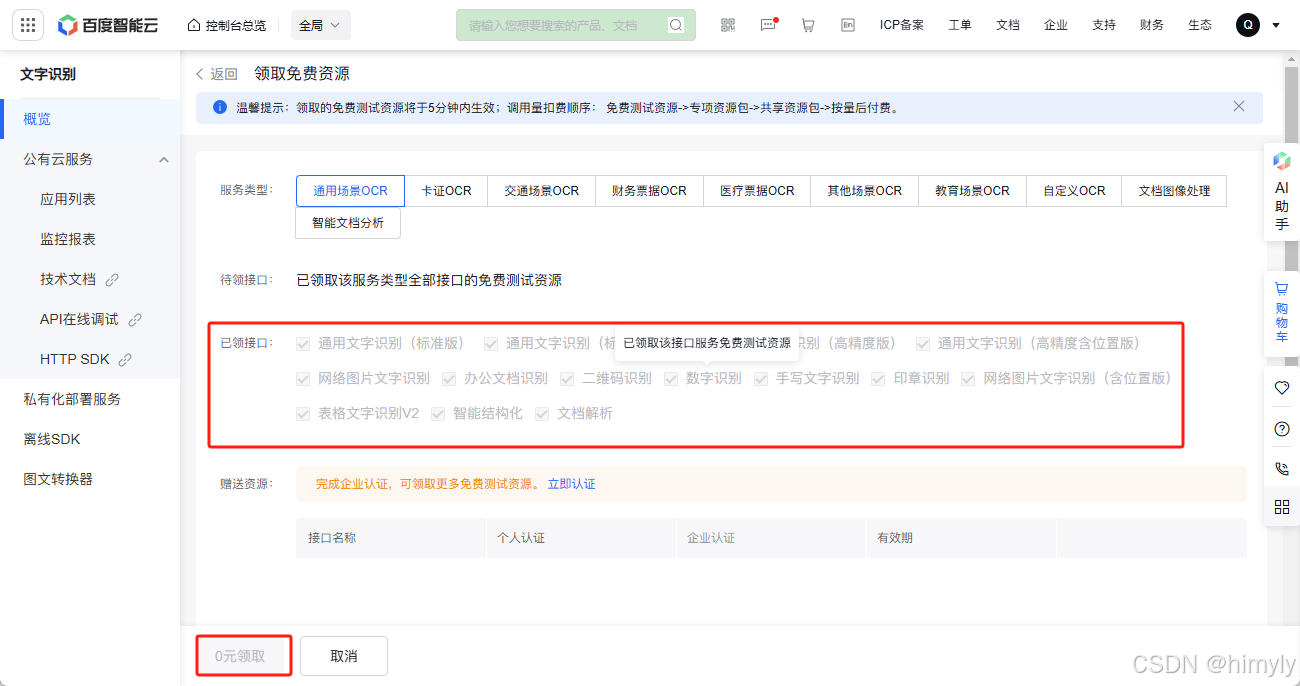
这里是因为我已经领取过了,全都勾然后领取就行
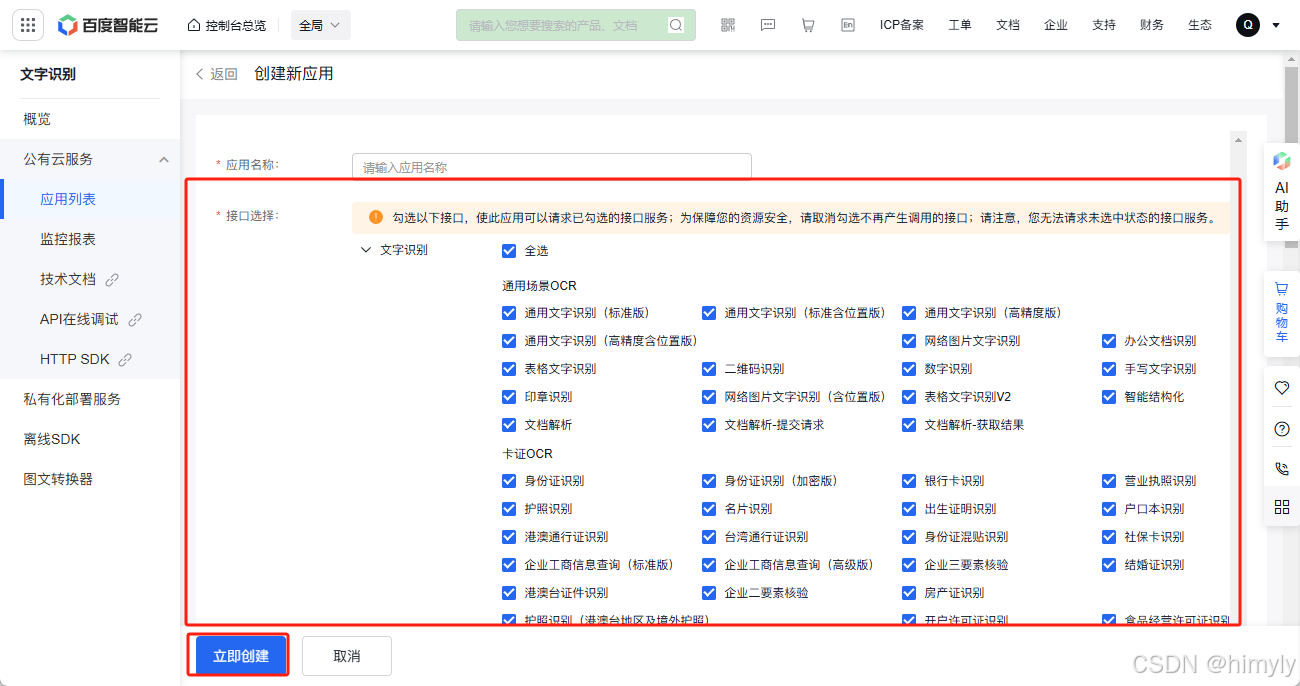
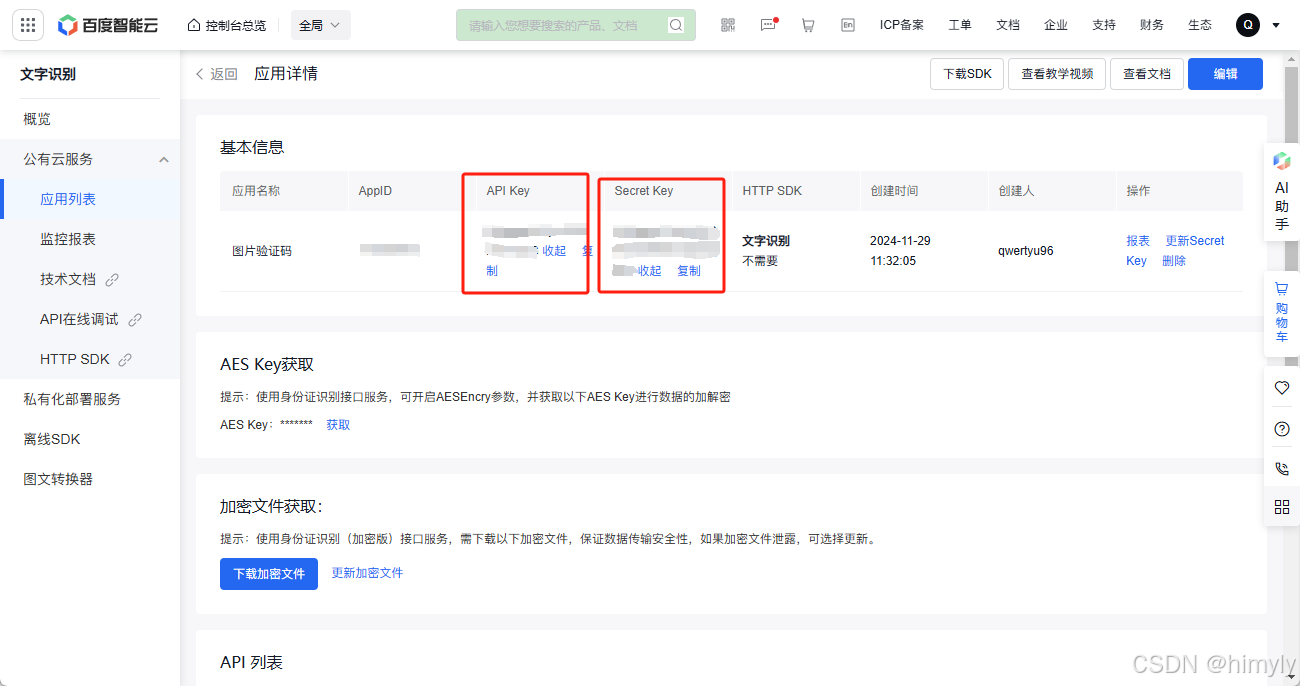
这里用这个方法获取,较为简单:
https://aip.baidubce.com/oauth/2.0/token?grant_type=client_credentials&client_id=【你创建应用的API Key值】&client_secret=【你创建应用的Secret Key值】
将创建之后的API Key和Secret Key替换掉【你创建应用的API Key值】和【你创建应用的Secret Key值】就行,然后访问该链接,这里我们需要的是access_token:后面的值,复制的时候加上双引号

将token复制过来,点击识别,然后将words后面的双引号内容选取并右键标记为识别结果
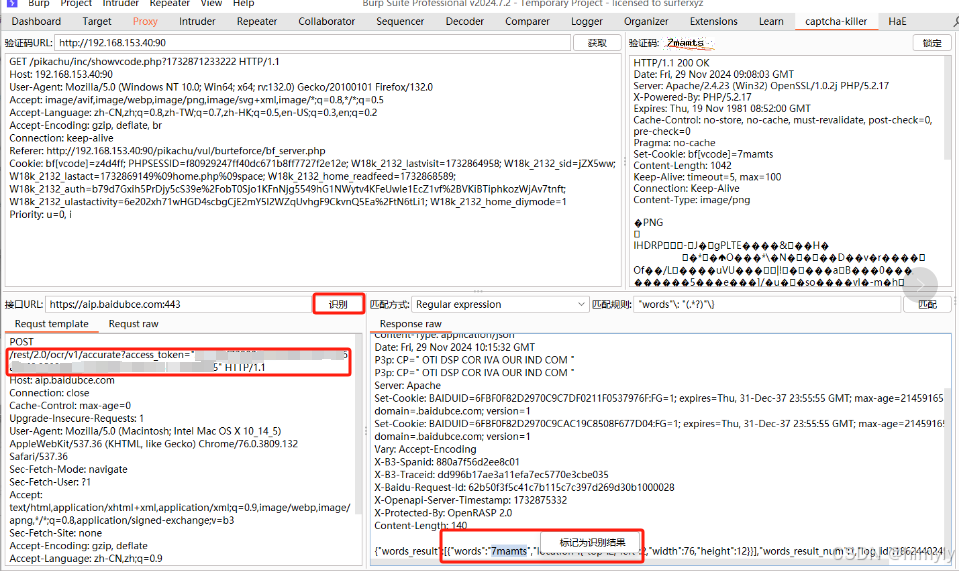
再次点击识别就会发现右边的图片码已经被识别出来了文字
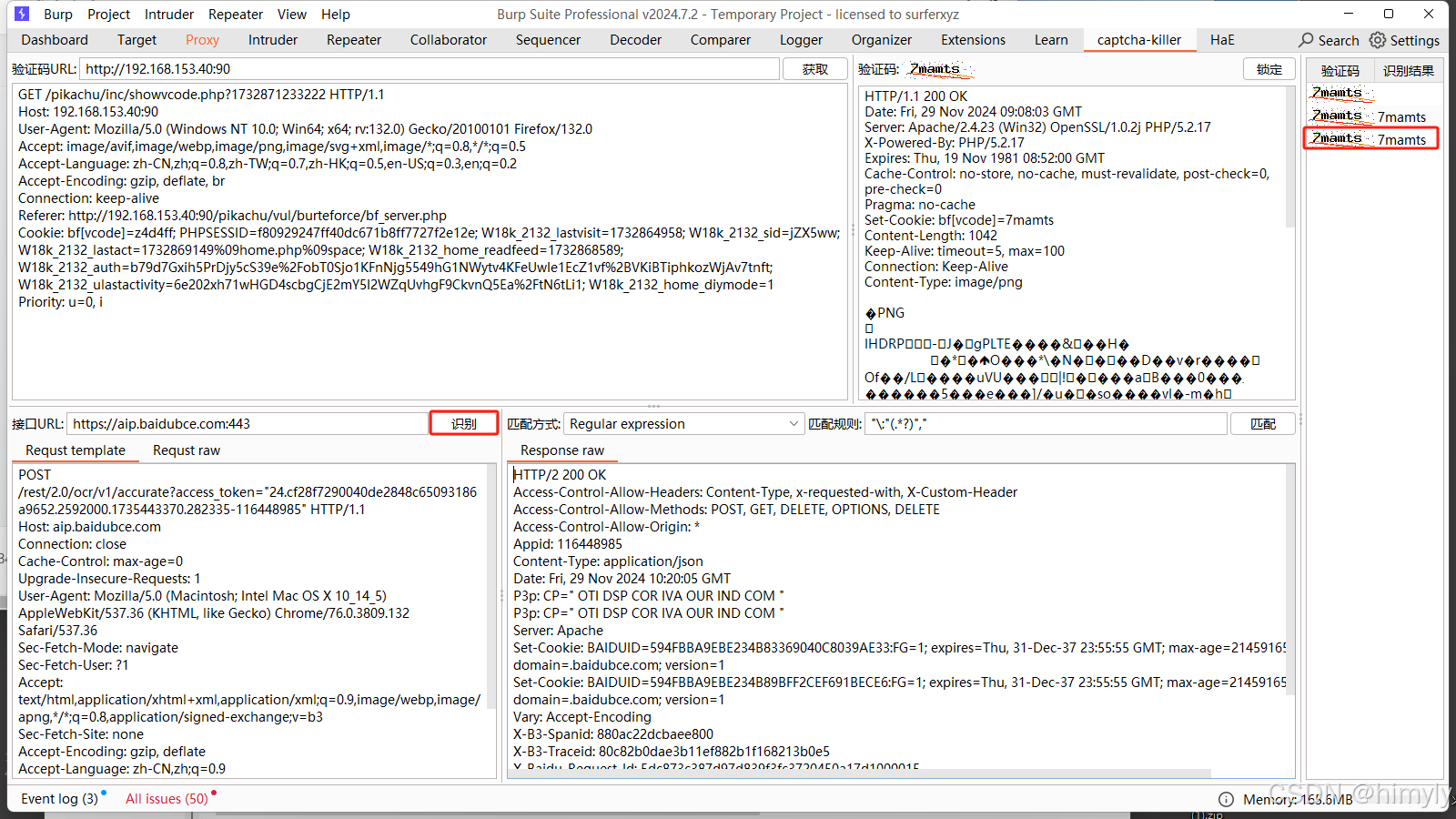
接下来我们打开pikachu暴力破解的第二关,输入正确的用户名、密码并随便输入验证码,抓包并将包发送给攻击模块
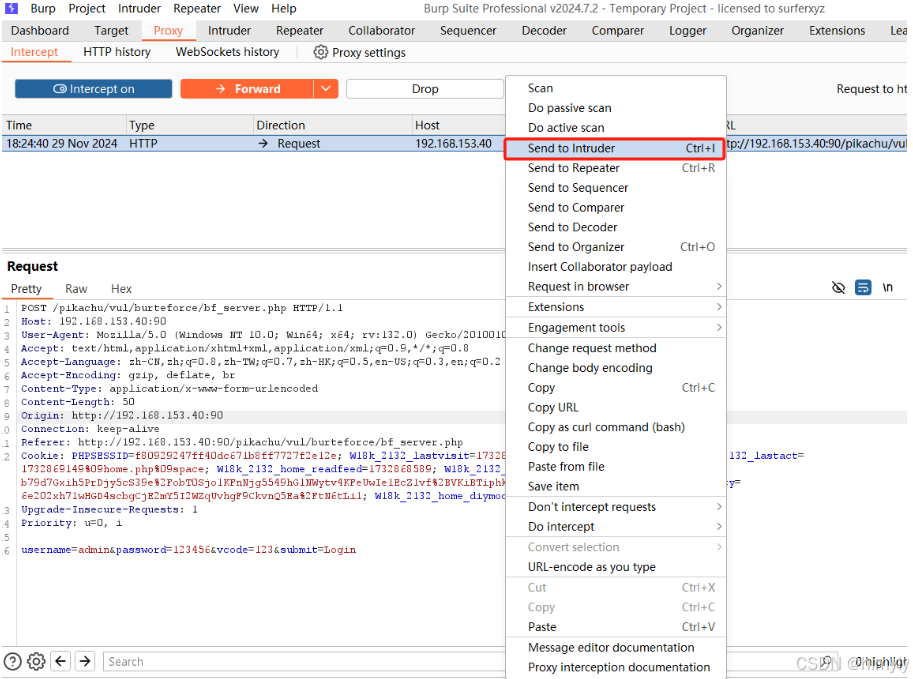
进入攻击模块,设置攻击节点
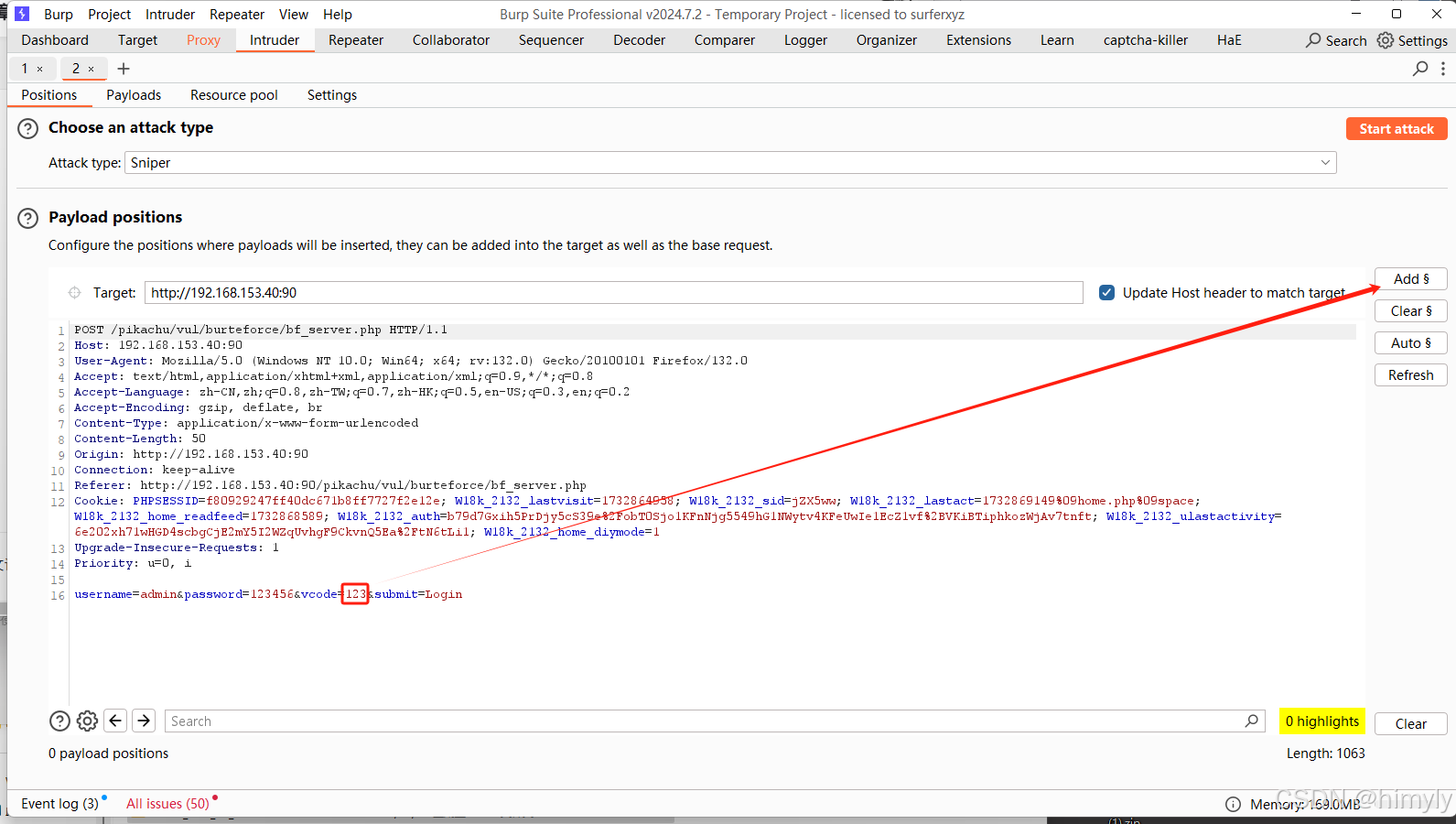
设置payload
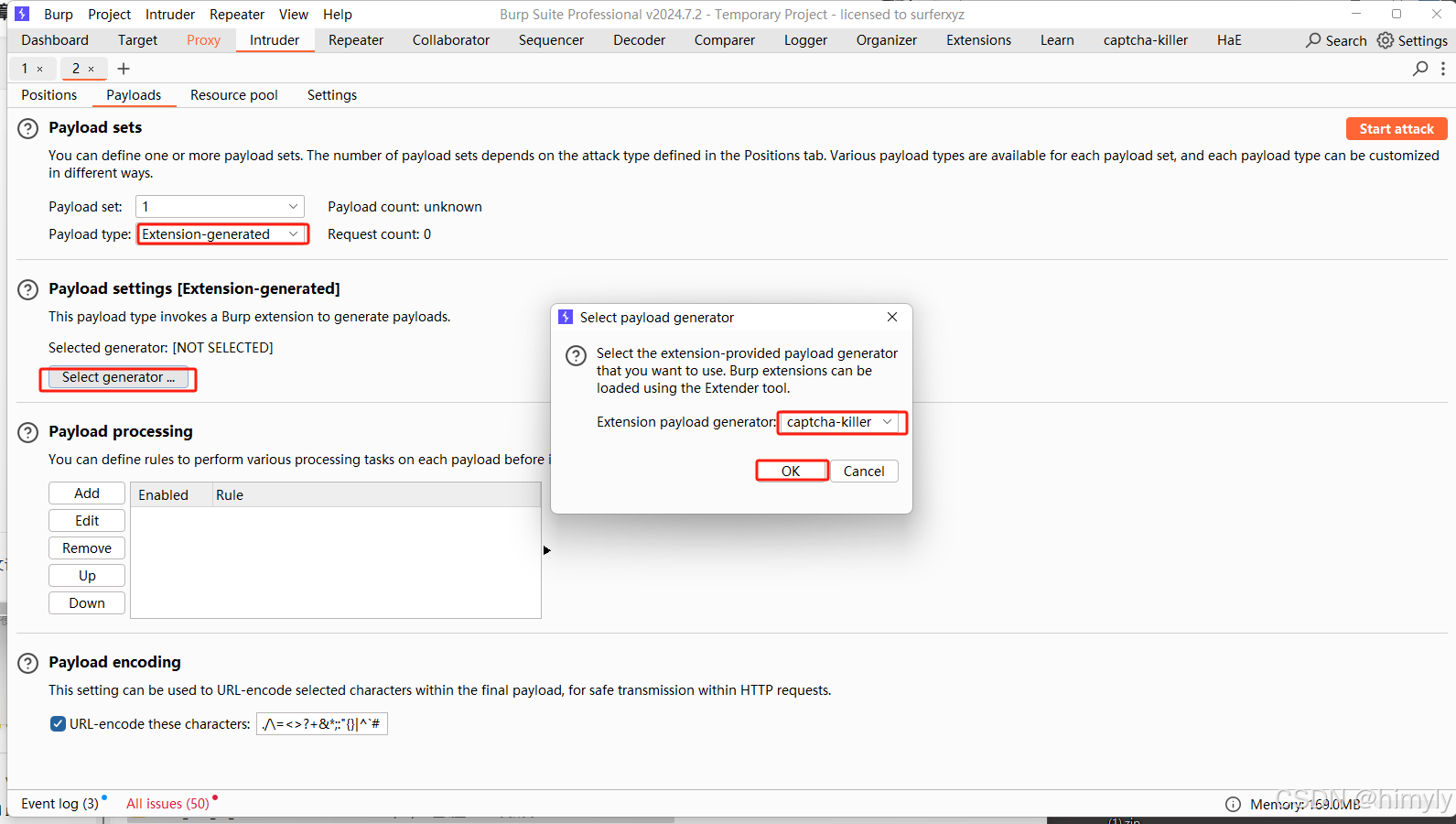
设置线程,开始攻击
查看攻击结果
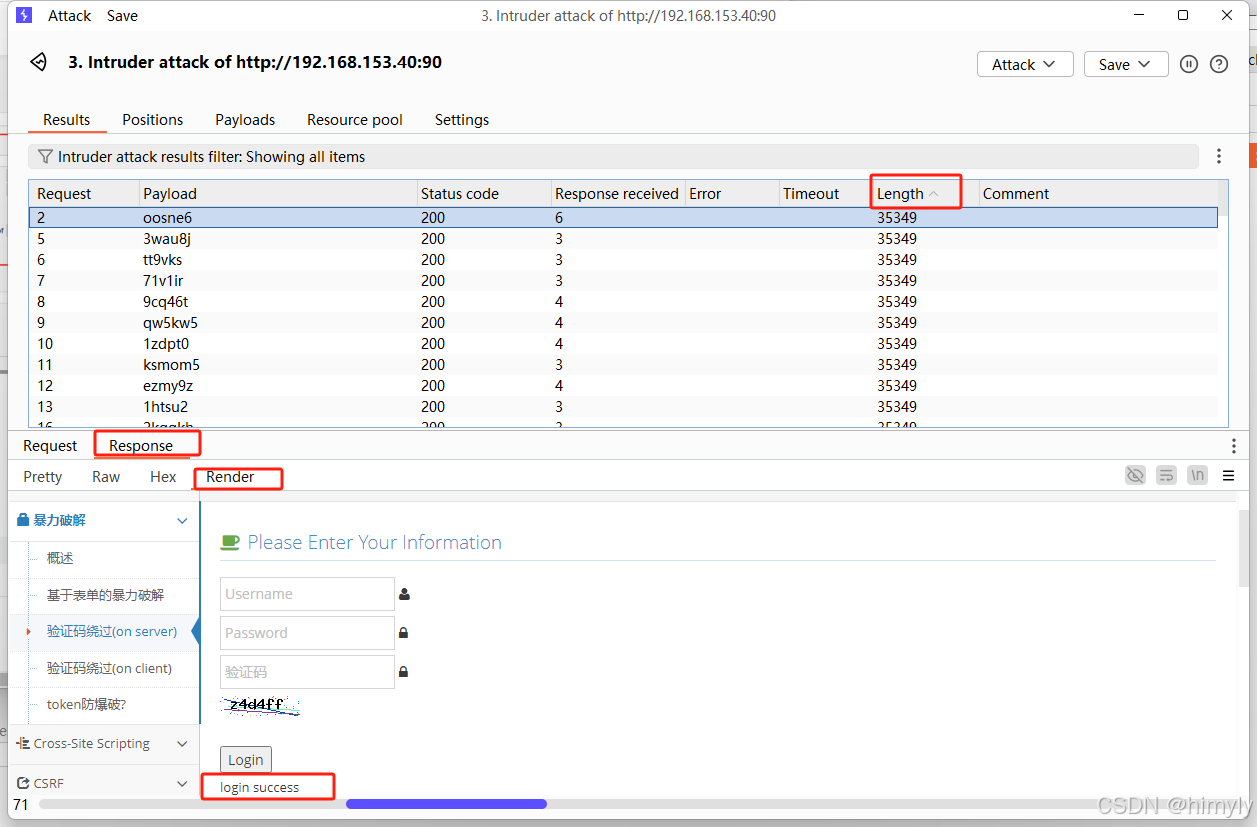
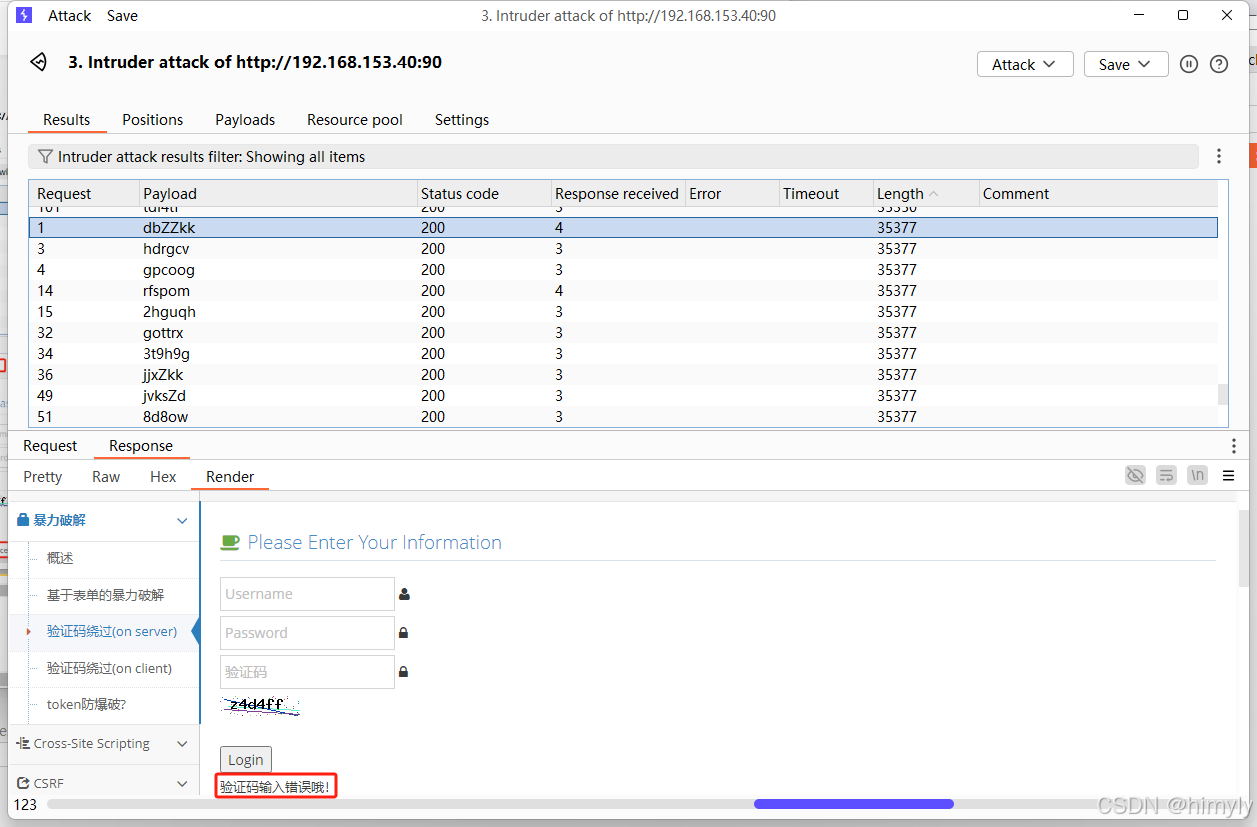
也有失败的,到这就完成了

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









