






文章目录
- 📚 核心逻辑(Core Logic):五大设计原则组合实现灵活适配和自动化处理
- 一、模块化设计(Modularity & Separation of Concerns):分层架构统一入口管理
- 二、配置驱动(Configuration-Driven Design):最小配置+自动推导策略
- 三、自动化智能(Automation & Intelligence):自动检测处理减少人工干预
- 四、可观测性(Observability & Traceability):统一日志实现执行透明化
- 五、容错机制(Fault Tolerance & Degradation):重试降级确保系统可用性
- 📝 总结(Summary):核心价值和快速借鉴指南
📌 适合对象:系统架构师、运维工程师、技术管理者
⏱️ 预计阅读时间:15分钟
🎯 学习目标:理解Starrocks生产级运维脚本设计的五大核心原则及其落地实现
📚 核心逻辑(Core Logic):五大设计原则组合实现灵活适配和自动化处理
要设计一套Starrocks生产级运维脚本,核心在于通过模块化设计、配置驱动、自动化智能、可观测性和容错机制的组合策略,实现脚本对不同环境的灵活适配、对常见问题的自动化处理,以及长期的便捷维护与扩展。
具体项目demo见:
github-StarRock部署的脚本化方案,支持三节点高可用部署。
五大核心原则(Five Core Principles):五个核心设计原则概述
-
模块化设计:统一入口管理所有运维操作,公共函数库提供日志、配置、工具等可复用功能,组件操作脚本分别处理FE/BE/运维操作,环境初始化脚本负责环境准备,实现从初始化Java环境、生成配置文件、启停集群、查看状态日志到清理集群的完整运维流程
-
配置驱动:从配置文件读取最小必要配置(节点IP、端口、数据目录等),自动根据节点IP生成网络配置,自动检测端口冲突并分配可用端口,自动生成运行时配置文件,启动前验证配置完整性
-
自动化智能:自动检测端口冲突并分配可用端口,监控进程状态并实时反馈启动进度,自动检测JDK环境并配置Java路径,自动管理启动顺序(FE先启动,等待就绪后启动BE),自动等待FE就绪并注册BE到集群
-
可观测性:统一日志格式(时间戳+级别+消息),记录每个操作的命令和参数、操作结果、配置变更,捕获完整错误上下文(标准输出和错误输出),通过标记文件记录组件状态,支持查看日志和集群状态命令
-
容错机制:遍历所有FE节点重试连接(最多60次,每次间隔2秒),自动尝试有密码/无密码的数据库连接,遍历所有FE节点尝试注册BE,在找不到FE时先启动BE进程(降级处理),通过标记文件避免重复注册
知识地图(Knowledge Map):知识结构可视化
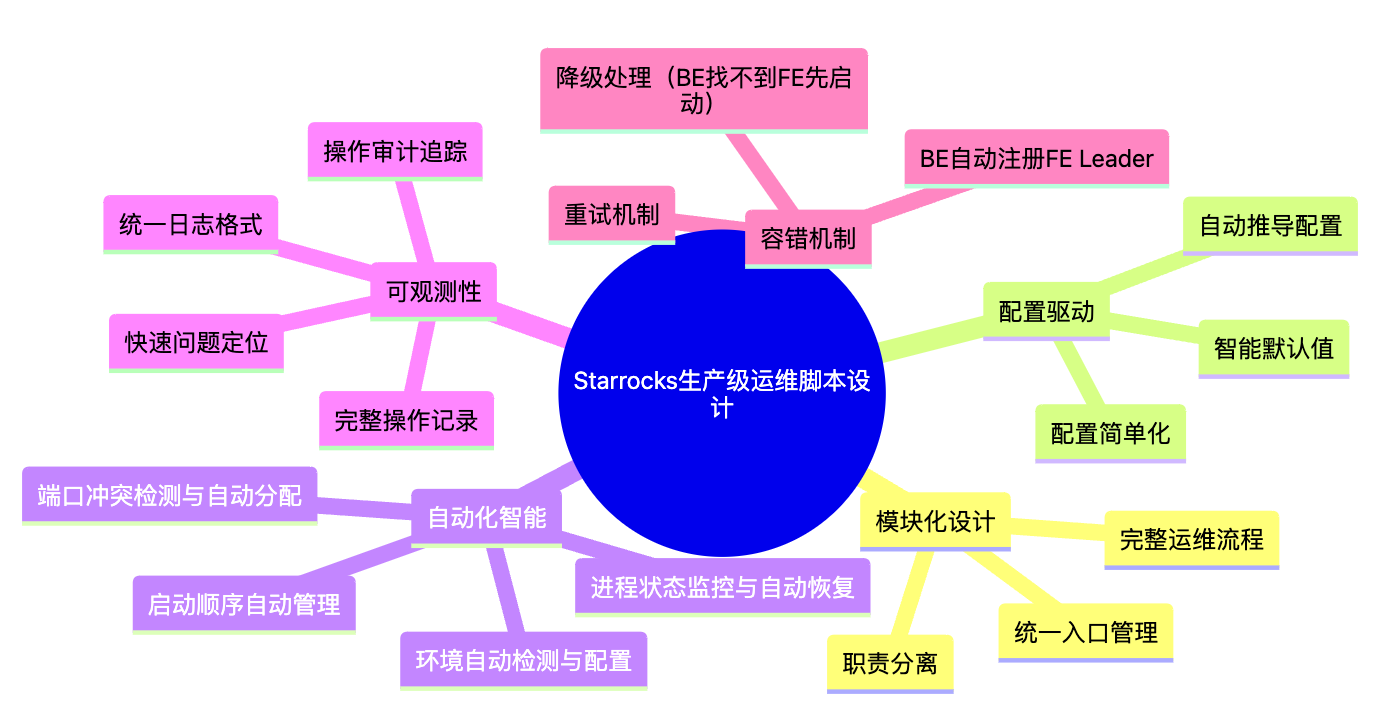
一、模块化设计(Modularity & Separation of Concerns):分层架构统一入口管理
设计思路(Design Approach):解决代码耦合问题
核心问题:传统运维脚本将所有功能混在一起,导致代码耦合严重、难以维护、无法复用。如何组织脚本结构,让运维操作清晰可控?
解决方案:采用分层模块化设计,将脚本拆分为主入口、公共函数库、组件操作脚本三个层次,每个层次职责清晰,通过统一入口管理所有运维操作。
落地实现(Implementation):三层架构实现完整生命周期管理
三层架构设计:
-
主入口层:统一命令接口,解析用户命令并路由到对应模块
- 支持的命令:初始化、启动、停止、状态查看、重启、日志查看、配置查看、清理、详细信息、健康检查、集群信息
- 统一加载公共函数库和组件操作脚本
- 统一处理命令参数验证和错误处理
-
公共函数库层:提供可复用的基础能力
- 日志系统:统一日志格式(时间戳+级别+消息),支持INFO/WARN/ERROR三级日志
- 配置管理:加载和验证配置文件,提供默认值机制
- 工具函数:进程状态监控、数据库连接执行、组件参数验证等
-
组件操作层:分别处理不同组件的专门操作
- FE操作:启动、停止、状态检查(处理Leader/Follower逻辑)
- BE操作:启动、停止、状态检查、注册到集群(处理注册逻辑)
- 运维操作:日志查看、配置查看、清理、健康检查、集群信息查询
完整运维流程:
从环境初始化到集群清理的完整生命周期管理:
- 环境初始化:自动检测和配置Java环境
- 配置生成:根据最小配置自动生成运行时配置
- 集群启停:统一的启停命令,自动处理组件依赖关系
- 状态查看:实时查看集群状态和组件健康
- 日志管理:统一的日志查看接口
- 集群清理:一键清理集群数据、日志、临时文件
可借鉴点(Key Takeaways):三个核心设计原则
- 统一入口原则:所有运维操作通过一个入口命令完成,降低学习成本和使用复杂度
- 职责分离原则:公共功能抽取到公共函数库,组件特定功能独立到组件脚本,便于维护和扩展
- 完整生命周期管理:覆盖从初始化到清理的完整流程,避免遗漏关键步骤
架构图:
二、配置驱动(Configuration-Driven Design):最小配置+自动推导策略
设计思路(Design Approach):解决配置复杂问题
核心问题:不同环境需要不同配置,如果要求用户配置所有参数,配置复杂且容易出错。如何让配置简单化,同时保持灵活性?
解决方案:采用"最小配置+自动推导"的策略,用户只需配置核心参数,脚本自动推导其他配置,自动检测和处理配置冲突,启动前验证配置完整性。
落地实现(Implementation):最小化配置和自动推导机制
配置简化策略:
-
最小化配置:用户只需配置核心参数
- 节点IP地址(FE_NODES、BE_NODES)
- 数据目录(DATA_DIR)
- StarRocks安装路径(STARROCKS_HOME)
- Java环境路径(JAVA_HOME)
-
自动推导配置:根据核心参数自动生成其他配置
- 根据节点IP自动生成网络配置(priority_networks = IP/24)
- 根据数据目录自动生成日志目录
- 根据节点角色自动判断是否为Leader节点
-
智能默认值:非关键配置使用合理默认值
- 数据库密码默认值
- 端口默认值(可自动调整)
- JVM参数默认值
-
冲突自动处理:自动检测和处理配置冲突
- 端口冲突检测:启动前检测端口是否被占用
- 自动分配可用端口:端口被占用时自动查找可用端口并更新配置
- 记录端口变更:记录端口变更日志,便于后续排查
配置验证机制:
- 启动前检查配置文件是否存在
- 验证必需配置项是否完整
- 验证路径是否存在(安装目录、Java目录)
- 验证Java环境是否为JDK(检查javac)
可借鉴点(Key Takeaways):四个配置设计原则
- 最小配置原则:只要求用户配置最核心的参数,降低配置复杂度
- 自动推导原则:根据核心参数自动推导其他配置,减少用户工作量
- 冲突自动处理:自动检测和处理配置冲突,避免手动排查
- 配置验证机制:启动前验证配置完整性,提前发现问题
配置驱动流程图:
三、自动化智能(Automation & Intelligence):自动检测处理减少人工干预
设计思路(Design Approach):解决重复性工作问题
核心问题:运维操作涉及大量重复性工作和细节处理,如果都依赖人工,既繁琐又容易出错。如何让脚本自动处理常见问题,减少人工干预?
解决方案:让脚本具备自动检测、自动处理、自动恢复的能力,自动处理端口冲突、进程监控、环境检测、启动顺序等常见问题,减少人工干预,提高操作成功率。
落地实现(Implementation):端口冲突、进程监控、环境检测、启动顺序自动处理
自动化能力:
-
端口冲突自动处理
- 启动前自动检测端口是否被占用
- 端口被占用时自动查找可用端口(从指定端口向上查找,最多尝试100次)
- 自动更新配置文件,记录端口变更日志
-
进程状态自动监控
- 启动后持续监控进程状态(最多等待80秒,每2秒检查一次)
- 实时反馈启动进度(每5次检查显示进度)
- 进程异常退出时自动检测并记录
-
环境自动检测与配置
- 自动检测Java环境路径是否存在
- 验证是否为JDK(检查javac文件)
- 自动创建Java软链接,统一Java路径
-
启动顺序自动管理
- FE先启动,等待FE就绪后再启动BE(启动all时自动处理)
- 自动检测FE Leader选举完成
- BE启动时自动等待FE就绪并注册到集群
-
组件状态自动判断
- 通过标记文件判断组件是否已加入集群(fe_flag、be_registered_flag)
- 首次启动和后续启动采用不同策略
- 自动判断节点角色(Leader/Follower)
可借鉴点(Key Takeaways):四个自动化设计原则
- 冲突自动处理:自动检测和处理端口冲突,避免手动排查
- 状态自动监控:自动监控进程状态并实时反馈,避免盲目等待
- 环境自动检测:自动检测和配置运行环境,避免环境问题导致失败
- 依赖自动管理:自动管理组件启动顺序和依赖关系,避免手动协调
自动化处理流程图:
四、可观测性(Observability & Traceability):统一日志实现执行透明化
设计思路(Design Approach):解决问题定位困难
核心问题:生产环境中,出问题时需要知道发生了什么、什么时候发生的、为什么发生。没有完整的日志记录,就像"盲人摸象",无法定位问题。如何让脚本执行过程完全透明化?
解决方案:建立统一的日志系统,记录每一步操作的命令、参数、结果,捕获完整的错误上下文,通过标记文件记录组件状态,让脚本执行过程完全可追溯。
落地实现(Implementation):统一日志格式和完整操作记录
日志记录策略:
-
统一日志格式
- 时间戳:精确到秒(YYYY-MM-DD HH:MM:SS)
- 日志级别:INFO(正常流程)、WARN(警告信息)、ERROR(错误信息)
- 消息内容:包含操作模块、命令、参数、结果等完整信息
-
完整操作记录
- 记录执行的命令和参数(如:尝试连接FE节点: mysql -h f e n o d e − P fe_node -P fenode−Pquery_port)
- 记录操作结果(成功/失败,包含详细信息)
- 记录配置变更(更新配置: key = value (原值: old_value))
- 记录关键决策点(如:BE已注册过,直接启动)
-
错误上下文捕获
- 分别捕获标准输出和错误输出
- 记录完整的错误信息(包括执行的命令、参数、错误输出)
- 启动失败时输出最后N行应用日志
-
状态标记机制
- 通过标记文件记录组件状态(fe_flag、be_registered_flag)
- 标记文件存在表示组件已加入集群或已注册
- 支持快速判断组件状态,避免重复操作
实际应用场景:
- 问题排查:当集群启动失败时,通过日志快速定位是哪个步骤失败、失败原因是什么
- 操作审计:记录所有操作的时间、命令、结果,满足审计要求
- 故障分析:通过完整的操作历史,分析故障发生的根本原因
- 性能优化:通过日志分析操作耗时,找出性能瓶颈
可借鉴点(Key Takeaways):四个可观测性设计原则
- 统一日志格式:所有日志使用统一格式,便于分析和过滤
- 完整操作记录:记录每个操作的命令、参数、结果,让执行过程完全透明
- 错误上下文捕获:捕获完整的错误信息,包括执行的命令和错误输出
- 状态标记机制:通过标记文件记录组件状态,支持快速判断和避免重复操作
日志系统架构图:
五、容错机制(Fault Tolerance & Degradation):重试降级确保系统可用性
设计思路(Design Approach):解决系统可用性问题
核心问题:分布式系统中,组件之间相互依赖,网络可能抖动,节点可能故障。如果脚本在遇到这些问题时直接失败,会导致操作成功率低、系统可用性差。如何让脚本优雅地处理各种异常情况?
解决方案:采用重试机制、多节点容错、降级处理等策略,让脚本在遇到临时问题时自动重试,在关键依赖不可用时优雅降级,确保系统在部分组件失败时仍能正常运行。
落地实现(Implementation):重试机制和多节点容错
核心容错策略:
-
重试机制
- 网络连接失败时自动重试(最多60次,每次间隔2秒,最多等待120秒)
- 遍历所有可用节点,任意一个成功即可
- 每10次尝试显示进度,避免用户等待焦虑
- 记录重试过程,便于问题分析
-
多节点容错
- FE节点容错:遍历所有FE节点尝试连接,任意一个可用即可
- BE节点容错:单个BE节点失败不影响其他BE节点运行
- 集群查询容错:尝试连接所有FE节点,任意一个成功即可
-
自动降级处理
- BE找不到FE时的降级:BE启动时如果找不到FE Leader,先启动BE进程,然后后台持续尝试连接FE并注册(通过StarRocks的心跳机制自动注册)
- 注册失败时的降级:BE注册失败时记录警告但继续启动BE进程,后续通过心跳机制自动注册
- 非关键依赖降级:对于非关键依赖,失败时记录警告但继续执行主流程
-
状态标记避免重复操作
- 通过标记文件(be_registered_flag)记录BE是否已注册
- 已注册的BE直接启动,跳过注册步骤
- 避免重复注册导致的错误
实际应用场景:
- 集群启动:FE先启动,BE启动时如果FE还未完全就绪,BE先启动等待,然后自动注册
- 节点故障:单个节点故障不影响其他节点,系统降级运行
- 网络抖动:临时网络问题通过重试机制自动恢复
- 配置错误:非关键配置错误时记录警告但继续运行,关键配置错误时立即报错
可借鉴点(Key Takeaways):四个容错设计原则
- 重试机制:网络操作失败时自动重试,避免临时问题导致操作失败
- 多节点容错:遍历所有可用节点,任意一个成功即可,不依赖单一节点
- 降级处理:关键依赖不可用时优雅降级,先启动进程,后续自动恢复
- 状态标记:通过标记文件避免重复操作,提高操作效率
容错机制流程图:
📝 总结(Summary):核心价值和快速借鉴指南
设计原则的核心价值(Core Value):五大设计原则的核心价值
- 模块化设计:通过分层架构和职责分离,让脚本结构清晰、易于维护和扩展
- 配置驱动:通过最小配置和自动推导,降低配置复杂度,提高易用性
- 自动化智能:通过自动检测和处理,减少人工干预,提高操作成功率
- 可观测性:通过统一日志和完整记录,让执行过程透明化,便于问题排查
- 容错机制:通过重试和降级,提高系统健壮性和可用性
快速借鉴指南
- 统一入口:所有运维操作通过一个入口命令完成
- 最小配置:只要求用户配置核心参数,其他自动推导
- 自动处理:自动检测和处理常见问题(端口冲突、环境检测等)
- 完整日志:记录每个操作的命令、参数、结果,便于问题排查
- 优雅降级:关键依赖不可用时先启动进程,后续自动恢复



















 1508
1508

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











