




想象一下,你是一个探险家,在一个未知的岛屿上寻找宝藏。你不仅要学习"哪些地方可能有宝藏"(评估状态),还要决定"应该去哪里探索"(选择动作)。这就是主动强化学习:智能体不仅要学习环境,还要主动决策。
主动强化学习比被动强化学习更复杂,但也更强大。通过主动选择动作,智能体可以更快地学习环境,发现更好的策略。但这也带来了新的挑战:如何平衡探索和利用?如何避免过早收敛到次优策略?如何在实际应用中保证安全?
核心观点
主动强化学习是智能体不仅要学习状态价值,还要主动选择动作以最大化奖励的过程。它面临探索与利用的核心矛盾:既要尝试新动作发现更好策略,又要利用已知的好动作获得奖励。
这个观点的核心在于:主动学习不仅要"评估",还要"决策"。被动学习智能体有一个固定的策略来决定其行为,而主动学习智能体必须自己决定"应该做什么"。这就像你不仅要学习"哪条路好走",还要决定"应该走哪条路"。
主动强化学习的核心挑战是探索与利用的平衡。如果只利用已知的好动作,可能错过更好的策略;如果只探索新动作,可能浪费时间和资源。成功的主动学习需要在两者之间找到平衡,既要快速学习,又要获得高奖励。
一、什么是主动强化学习?
1.1 主动学习与被动学习的区别
被动学习智能体有一个固定的策略来决定其行为,它只需要跟随策略,观察结果,学习状态价值。主动学习智能体必须自己决定"应该做什么",它不仅要学习状态价值,还要学习动作价值,并选择最优动作。
这就像两个学生:一个学生按照老师给的路线学习(被动学习),只需要记住"这条路好不好";另一个学生自己决定走哪条路(主动学习),不仅要学习"路好不好",还要决定"应该走哪条路"。
1.2 主动学习的优势
主动学习的优势是:它可以更快地学习环境,发现更好的策略。通过主动选择动作,智能体可以优先探索有价值的状态,而不是随机探索。这就像聪明的探险家会优先探索可能有宝藏的地方,而不是盲目地到处走。
另外,主动学习可以让智能体适应环境变化。如果环境改变了,智能体可以通过探索发现新的好策略,而不是固守旧的策略。这使得主动学习更适合动态、变化的环境。
1.3 主动学习的挑战
主动学习也面临挑战。
- 首先是探索与利用的平衡:如果只利用已知的好动作,可能错过更好的策略;如果只探索新动作,可能浪费时间和资源。
- 其次是可能过早收敛到次优策略:如果智能体过早地认为某个策略是"最好的",可能停止探索,错过真正的最优策略。
在实际应用中,主动学习还面临安全挑战。在真实世界中,很多动作是不可逆的,智能体可能进入"吸收状态"(无法恢复或获得进一步奖励的状态)。比如自动驾驶汽车,错误的动作可能导致严重事故,无法挽回。
二、探索与利用的平衡
2.1 贪心策略的问题
最简单的主动学习方法是贪心策略:智能体总是选择根据当前学习的模型认为最优的动作。这就像你总是选择"看起来最好"的路,不尝试其他路。
但贪心策略有问题:如果学习的模型不完美,智能体可能收敛到次优策略。比如,在4×3世界中,如果智能体过早地认为"通过(2,1)到达终点"是好的,可能停止探索,错过"通过(1,3)到达终点"这个更好的路径。
图22-6展示了贪心ADP智能体的表现:策略损失快速收敛到次优策略(损失0.235),只用了8次试验。这说明贪心策略虽然快速,但可能错过最优策略。
2.2 探索的重要性
探索的重要性在于:动作不仅提供奖励,还提供信息。通过尝试新动作,智能体可以学习环境的更多信息,发现更好的策略。这就像多臂老虎机问题:如果你只拉已知最好的手臂,可能错过更好的手臂。
为了确保收敛到最优策略,需要"在无限探索的极限下贪心"(GLIE)策略:确保每个状态-动作对都被尝试无限次。这保证了智能体最终会探索所有可能性,找到最优策略。
2.3 探索策略
简单的GLIE策略是:在时间t,智能体以概率1/t随机选择动作,否则选择贪心动作。这确保了随着时间推移,随机探索的概率逐渐降低,但永远不会完全消失。
更复杂的方法是:为较少尝试的状态-动作对分配更高的效用估计。这鼓励智能体探索未知区域,同时仍然利用已知的好动作。修改后的贝尔曼方程是: U ∗ ( s ) ← m a x f ( P ( s ′ ∣ s , a ) [ R ( s , a , s ′ ) + γ U ∗ ( s ′ ) ] , N ( s , a ) ) U*(s) ← max f(P(s'|s,a)[R(s,a,s') + γU*(s')], N(s,a)) U∗(s)←maxf(P(s′∣s,a)[R(s,a,s′)+γU∗(s′)],N(s,a)),其中f(u,n)是探索函数,平衡贪心选择(更高的效用u)和好奇心(更低的尝试次数n)。
探索函数的一个例子是: f ( u , n ) = { R ∗ , 当 n < N e 时 ; u , 否则 } f(u,n) = \{R*, 当n < N_e时; u, 否则\} f(u,n)={R∗,当n<Ne时;u,否则},其中R*是对最佳可能奖励的乐观估计,N_e是固定参数,强制智能体至少尝试每个状态-动作对N_e次。
使用乐观的效用估计U*而不是悲观的U,对于有效探索至关重要,因为它鼓励智能体进一步探索未知区域。
2.4 探索性智能体的表现
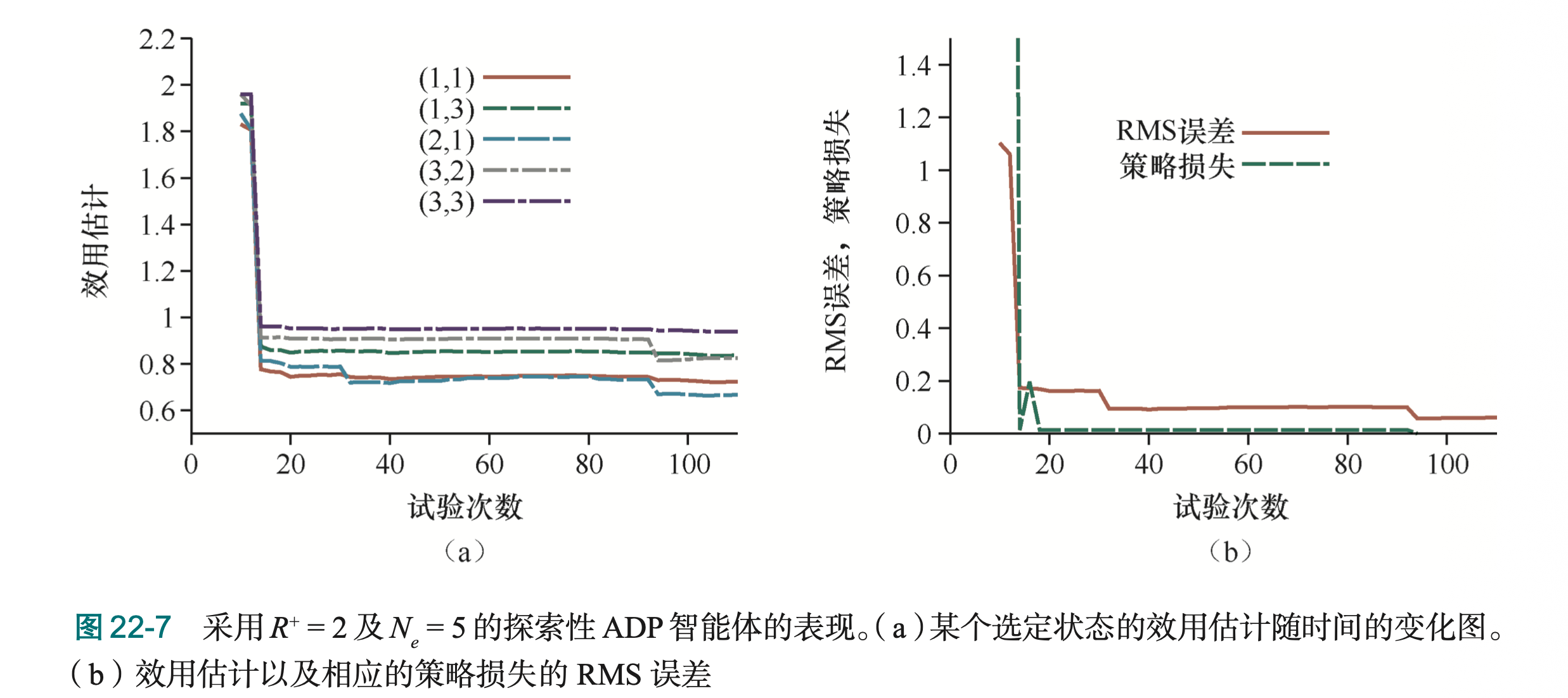
图22-7展示了探索性ADP智能体的表现(R*=2,N_e=5):经过大约30次试验,效用估计和策略损失都收敛到接近零,说明智能体成功找到了最优策略。这比贪心智能体好得多,说明探索的重要性。
三、安全探索
3.1 真实世界的挑战
在真实世界中,探索面临安全挑战。与理想化环境(如游戏或模拟)不同,在真实世界中,很多动作是不可逆的,智能体可能进入"吸收状态"。比如自动驾驶汽车,错误的动作可能导致严重事故、开进沟里(不可逆状态)、或损坏发动机(永久限制未来奖励)。
这就像你在真实世界中探险:如果走错路,可能掉进陷阱,无法恢复。这与游戏不同,游戏中你可以"重新开始",但真实世界中不行。
3.2 模型不确定性的问题
智能体可能因为对世界的未知或错误模型而做出糟糕的决策。如果使用最大似然估计学习转移模型,然后推导策略,可能导致"荒谬的策略"。比如,如果出租车在几次未受惩罚的情况下闯红灯,可能认为"闯红灯是好的",导致危险行为。
这就像你根据有限的观察得出结论:“这条路很安全”,但实际上这条路很危险,只是你还没遇到危险。在真实世界中,这种错误可能是致命的。
3.3 安全探索的方法
更好的方法是选择对所有合理模型都足够稳健的策略,即使它们对最大似然模型是次优的。这包括三种数学方法:
贝叶斯强化学习(Bayesian Reinforcement Learning)使用模型的先验和后验概率,推导最大化期望效用的最优策略。当涉及持续学习时,这变得复杂,导致"探索POMDP"问题。但即使贝叶斯方法,如果没有关于危险的充分先验知识,也不能保证安全。
健壮控制理论(Robust Control Theory)考虑一组可能的模型,不分配概率,旨在找到在这些模型的最坏情况下产生最佳结果的策略。这类似于极小极大游戏。虽然健壮,但这种方法可能导致过于保守的行为(比如,如果假设所有其他司机都会撞车,自动驾驶汽车可能拒绝移动)。
最坏情况假设虽然健壮,但可能导致过于保守。关键是要在安全性和性能之间找到平衡。
3.4 人类知识的作用
人类知识在确保系统安全方面起着重要作用,要么通过专家演示,要么通过对学习系统施加约束。比如,在危险情况下,安全控制器可以接管自主直升机,确保系统不会进入危险状态。
这就像教练在关键时刻介入,防止学生做出危险动作。在强化学习中,人类专家可以提供安全约束,确保智能体不会学习危险行为。
四、时序差分Q学习
4.1 Q学习的思想
时序差分Q学习(Temporal Difference Q-learning)是一种无模型的主动学习方法。它直接学习动作-效用函数Q(s,a),表示"在状态s选择动作a,然后按照最优策略行动,期望能获得多少累积奖励"。
如果知道了Q函数,最优动作可以通过 a r g m a x a Q ( s , a ) argmax_a Q(s,a) argmaxaQ(s,a)实现,不需要转移模型。这就像你知道了"每条路的价值",就可以直接选择"最好的路",不需要知道"这条路通向哪里"。
4.2 Q学习的更新规则
Q学习的更新规则来自贝尔曼方程: Q ( s , a ) = Σ P ( s ′ ∣ s , a ) [ R ( s , a , s ′ ) + γ m a x Q ( s ′ , a ′ ) ] Q(s,a) = Σ P(s'|s,a)[R(s,a,s') + γ max Q(s',a')] Q(s,a)=ΣP(s′∣s,a)[R(s,a,s′)+γmaxQ(s′,a′)]。时序差分更新规则是: Q ( s , a ) ← Q ( s , a ) + α [ R ( s , a , s ′ ) + γ m a x Q ( s ′ , a ′ ) − Q ( s , a ) ] Q(s,a) ← Q(s,a) + α[R(s,a,s') + γ max Q(s',a') - Q(s,a)] Q(s,a)←Q(s,a)+α[R(s,a,s′)+γmaxQ(s′,a′)−Q(s,a)],其中α是学习率。
这个更新规则与效用函数更新规则(22-3)类似。项 R ( s , a , s ′ ) + γ m a x Q ( s ′ , a ′ ) − Q ( s , a ) R(s,a,s') + γ max Q(s',a') - Q(s,a) R(s,a,s′)+γmaxQ(s′,a′)−Q(s,a)表示误差,更新旨在减少这个误差。这个方程的一个关键特性是:它不需要转移模型P(s’|s,a),这使得Q学习成为一种无模型方法,适合复杂领域。
4.3 Q学习的优势
Q学习的优势是:它是无模型的,不需要学习环境的转移模型,可以直接从经验中学习Q函数。这使得它适合复杂、动态的环境,其中转移模型可能难以学习或经常变化。
另外,Q学习可以处理稀疏奖励。即使奖励很少(比如只有最终奖励),Q学习也可以通过时序差分更新,逐步传播奖励信息,学习中间状态和动作的价值。
4.4 Q学习的挑战
Q学习也面临挑战。首先是稀疏奖励问题:如果奖励很少,可能需要很长的动作序列才能到达奖励状态,学习可能很慢。其次是探索问题:如果只选择已知的好动作,可能错过更好的策略。
解决这些挑战的方法包括:奖励塑形(提供中间奖励)、分层强化学习(将复杂任务分解为简单子任务)、探索策略(如ε-贪婪、UCB等)。
五、SARSA算法
5.1 SARSA与Q学习的区别
SARSA是"状态(State)、动作(Action)、奖励(Reward)、状态(State)、动作(Action)"的缩写。它的更新规则与Q学习非常相似:Q(s,a) ← Q(s,a) + α[R(s,a,s’) + γ Q(s’,a’) - Q(s,a)]。
关键区别在于:SARSA使用Q(s’,a’),其中a’是在下一个状态s’中实际采取的动作,而Q学习使用max_a’ Q(s’,a’)。这就像两个学生:一个学生根据"下一步实际会做什么"来学习(SARSA),另一个学生根据"下一步最好做什么"来学习(Q学习)。
5.2 在线策略与离线策略
Q学习和SARSA的区别反映了"在线策略"(on-policy)和"离线策略"(off-policy)的区别。Q学习是离线策略算法:它学习最优策略的值,同时遵循探索性策略。SARSA是在线策略算法:它学习当前遵循的策略的值。
如果智能体是贪心的(总是选择Q值最高的动作),Q学习和SARSA是相同的。但在探索期间,它们不同:Q学习学习最优策略,即使它正在探索;SARSA学习当前策略,包括探索性动作。
5.3 适用场景
Q学习适合需要学习最优策略,但当前策略是探索性的场景。比如,在训练期间使用探索性策略,但希望学习最优策略用于部署。
SARSA适合需要学习当前策略的场景。比如,在在线学习中,智能体需要学习当前策略的值,以便改进当前策略。SARSA通常更保守,因为它考虑了探索性动作的后果。
5.4 实际应用
在实际应用中,Q学习更常用,因为它可以学习最优策略,即使使用探索性策略。但SARSA在某些场景中更合适,特别是当探索性动作有负面后果时(比如在真实世界中,探索性动作可能导致危险)。
六、主动学习的实际应用
6.1 游戏中的应用
在游戏中,主动强化学习已经取得了巨大成功。DQN(Deep Q-Network)是第一个现代深度强化学习系统,使用深度神经网络表示Q函数。它在49种不同的Atari电子游戏上训练,从原始图像数据学习玩模拟赛车、射击外星人、打乒乓球等游戏。
AlphaGo使用深度强化学习击败了顶级人类围棋选手。它使用价值函数和Q函数,用卷积神经网络指导搜索,通过自我对弈不断改进。
6.2 机器人控制中的应用
在机器人控制中,主动强化学习让机器人学会了复杂动作。倒立摆平衡问题(cart-pole balancing)是一个经典例子:智能体需要控制推车左右移动,保持杆子大致垂直,同时保持推车位置在轨道限制内。
这个问题很困难,因为状态变量是连续的(位置x、角度θ、速度ẋ、角速度θ̇),而动作是离散的(急左或急右)。早期工作使用"BOXES"算法,将4D状态空间离散化,经过约30次试验后实现了超过一小时的平衡。
通过自适应状态空间划分和非线性函数近似器(如神经网络),性能得到了改进。平衡"三段倒立摆"(三根杆子首尾相连)是一个常见的训练任务,远远超过人类能力,但强化学习可以实现。
6.3 自动驾驶中的应用
在自动驾驶中,主动强化学习帮助车辆学习安全驾驶策略。但这也面临安全挑战:错误的动作可能导致严重事故。因此,安全探索和安全约束在自动驾驶中至关重要。
七、总结
主动强化学习是智能体不仅要学习状态价值,还要主动选择动作以最大化奖励的过程。它的核心在于:不仅要"评估",还要"决策"。
主动强化学习的核心挑战是探索与利用的平衡。贪心策略虽然快速,但可能收敛到次优策略。探索性策略可以找到最优策略,但需要更多时间和资源。成功的主动学习需要在两者之间找到平衡。
Q学习和SARSA是两种主要的主动学习方法。Q学习是离线策略的,学习最优策略;SARSA是在线策略的,学习当前策略。每种方法都有其适用场景。
记住:主动学习比被动学习更强大,但也更复杂。通过理解探索与利用的平衡,以及Q学习和SARSA的区别,我们可以更好地应用主动强化学习来解决实际问题。
参考:
《人工智能:现代方法(第四版)》


















 2828
2828

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











