







文章目录
Transformer 模型是由Google的研究员在2017年提出的,它在自然语言处理(NLP)依赖于循环神经网络(RNN)结构如LSTM或GRU,这使得它在处理长距离依赖问题时更加高效,并且可以并行处理序列数据,从而大大加快了训练速度。
Transformer 模型彻底摒弃了LSTM,单纯使用注意力机制对序列进行建模,也进一步刷新了机器翻译任务的最佳表现,并随后成为几乎所有自然语言处理任务的通用模型结构。
零. 架构概述
1. 架构组成
Transformer 由编码器和解码器两大部分组成,每个部分都由多个堆叠的层构成.
- 编码器:将文本化为词向量
编码器将输入序列编码成一个固定维度的向量表示,它由多个编码器层组成,每个编码器层包含两个子层,分别是多头自注意力机制和前馈神经网络,并且在每个子层后都有残差连接和层归一化。- 解码器:接收编码器生成的词向量(K、V),然后通过这个 “词向量” 去生成翻译的结果。
解码器根据编码器的输出以及之前生成的输出序列来生成下一个输出,它同样由多个解码器层组成,每个解码器层包含三个子层,分别是多头自注意力机制、多头注意力机制(编码器解码器注意力机制)和前馈神经网络,且每层之间也有残差连接和层归一化。
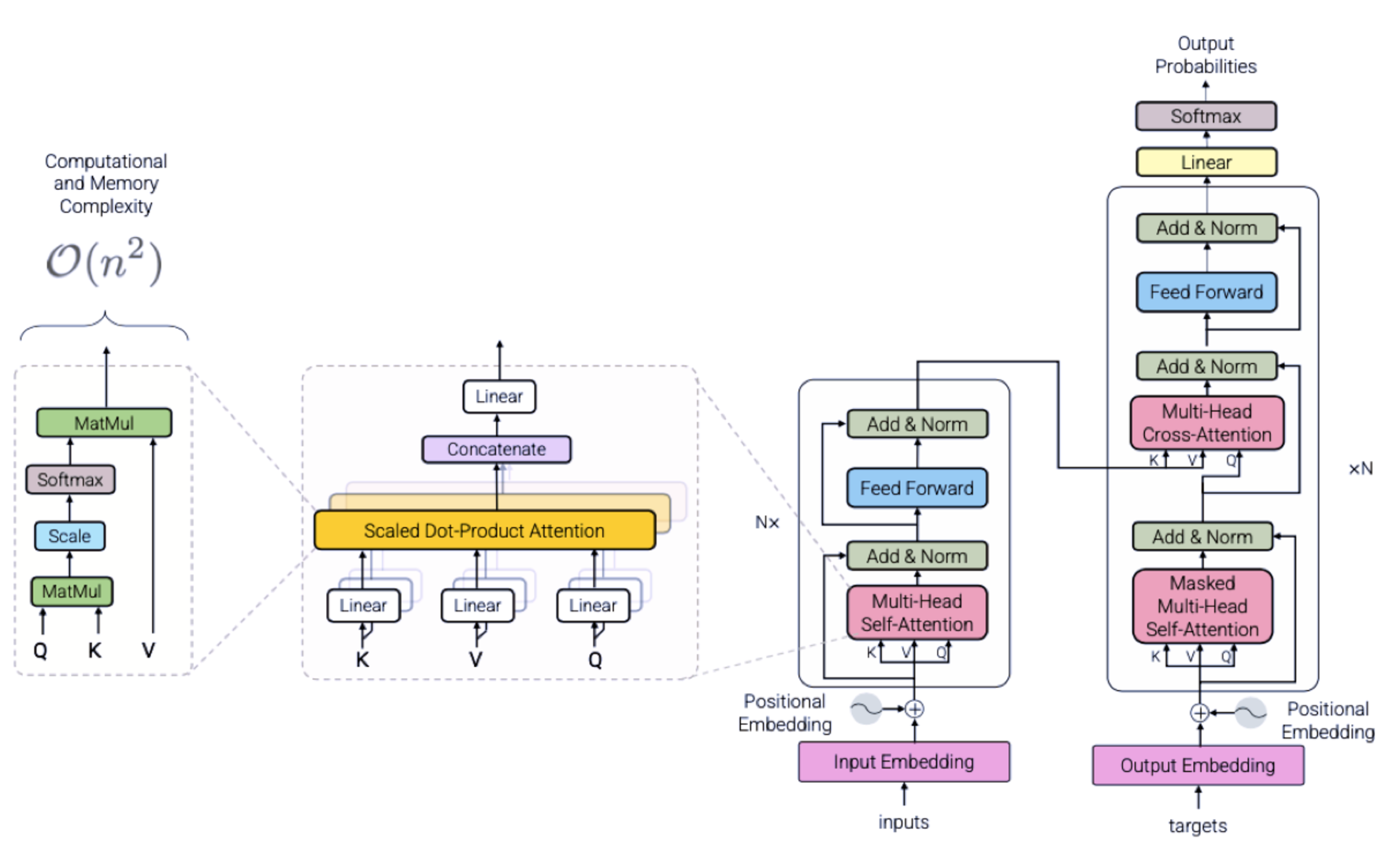
2. 处理流程
2.1. 数据预处理阶段
| 分词 | 将输入的文本数据按照一定的规则分割成单词或子词单元。 例如,对于英文句子“Transformer is a powerful model”,可以将其分割为[“Transformer”, “is”, “a”, “powerful”, “model”]。分词的方法有多种,像基于空格的简单分词、使用专门的分词工具(如NLTK库对于英文的分词)。 |
| 构建词汇表 | 把分词后的所有单词或子词进行统计,构建一个词汇表。词汇表中的每个单词都有一个对应的索引,用于后续的模型输入表示。 比如,假设词汇表大小为 (V),每个单词都被赋予一个从0到 (V - 1) 的整数索引。 |
| 向量化 | 将每个单词转换为词向量。词向量是一种低维的向量表示,能够在一定程度上体现单词的语义信息。可以使用预训练的词向量(如Word2Vec、GloVe),也可以在Transformer模型训练过程中一起学习得到。 例如,一个单词的词向量维度可能是512维,那么每个单词都被表示为一个长度为512的向量。 |
| 添加位置编码 | 由于Transformer模型本身没有对序列顺序的内在感知,所以需要为每个输入的单词向量添加位置编码。 位置编码可以是通过学习得到的向量,也可以是像Transformer原始论文中使用的基于正弦和余弦函数生成的固定编码。 这种编码能够为模型提供单词在序列中的位置信息。 |
2.2. 编码器阶段
- 多头自注意力机制(Multi - Head Self - Attention)阶段
| 输入映射 | - 对于输入序列中的每个单词向量,通过三个不同的线性变换(即乘以三个不同的权重矩阵 W Q 、 W K 、 W V W_Q、W_K、W_V WQ、WK、WV,分别生成Query(查询)向量、Key(键)向量和Value(值)向量。 - 例如,输入的单词向量维度为 d m o d e l d_{model} dmodel,经过线性变换后,Query、Key和Value向量的维度可能为 d k 、 d k 和 d v d_k、d_k和 d_v dk、dk和d |
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











