




文章目录
一. RDD序列化的原因
Spark初始化工作是在Driver端进行的,而实际运行程序是在Executor端进行的,这就涉及到了跨进程通信,是需要序列化的。所以用户开发的关于RDD的map,flatMap,reduceByKey等transformation 操作(闭包)有如下执行过程:
- 代码中对象在driver本地序列化
- 对象序列化后传输到远程executor节点
- 远程executor节点反序列化对象,最终在远程executor节点中执行。
在spark中4个地方用到了序列化:
- 算子中用到了driver定义的外部变量时;
- 将自定义的class作为RDD的数据类型时;
- 使用可序列化的持久化策略的时候。比如:MEMORY_ONLY_SER,spark会将RDD中每个分区都序列化成一个大的字节数组;
- shuffle。
二. Kryo序列化框架
官网地址: https://github.com/EsotericSoftware/kryo
Java的序列化能够序列化任何的类。但是比较重,序列化后对象的体积也比较大。
Spark出于性能的考虑,Spark2.0开始支持另外一种Kryo序列化机制。Kryo速度是Serializable的10倍。当RDD在Shuffle数据的时候,简单数据类型、数组和字符串类型已经在Spark内部使用Kryo来序列化。
spark使用Kryo序列化框架
public class Test02_Kryo {
public static void main(String[] args) throws ClassNotFoundException {
// 1.创建配置对象
SparkConf conf = new SparkConf().setMaster("local[*]").setAppName("sparkCore")
// 替换默认的序列化机制
.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
// 注册需要使用 kryo 序列化的自定义类(非必须,但是强烈建议做)
// 虽说该步不是必须要做的(不做Kryo仍然能够工作),但是如果不注册的话,
// Kryo会存储自定义类中用到的所有对象的类名全路径,这将会导致耗费大量内存。
.registerKryoClasses(new Class[]{Class.forName("com.atguigu.bean.User")});
// 2. 创建sparkContext
JavaSparkContext sc = new JavaSparkContext(conf);
// 3. 编写代码
User zhangsan = new User("zhangsan", 13);
User lisi = new User("lisi", 13);
JavaRDD<User> userJavaRDD = sc.parallelize(Arrays.asList(zhangsan, lisi), 2);
JavaRDD<User> mapRDD = userJavaRDD.map(new Function<User, User>() {
@Override
public User call(User v1) throws Exception {
return new User(v1.getName(), v1.getAge() + 1);
}
});
mapRDD. collect().forEach(System.out::println);
sc.stop();
}
}
public class User implements Serializable {
private String name;
private Integer age;
// getter 、setter、tostring
}
三. spark 配置 kryo 序列化
1. 设定kryo序列化
1.配置文件方式
可以在配置文件spark-default.conf中添加该配置项(全局生效)
spark.serializer org.apache.spark.serializer.KryoSerializer
2.业务代码中配置
在业务代码中通过SparkConf进行配置(针对当前application生效)
val spark = SparkSession.builder().master("local[*]").appName("test").getOrCreate()
val conf = new SparkConf
conf.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
3.在spark-shell、spark-submit脚本中启动
可以在命令中加上
--conf spark.serializer=org.apache.spark.serializer.KryoSerializer
2. 注册序列化类(非必须,但是强烈建议做)
......
conf.registerKryoClasses(Array(classOf[Test1], classOf[Test2]))
// 其中Test1.java 和 Test2.java 是自定义的类
如果是scala类Test1(scala中的trait就相当于java中的接口):
class Test1 extends Serializable {
......
}
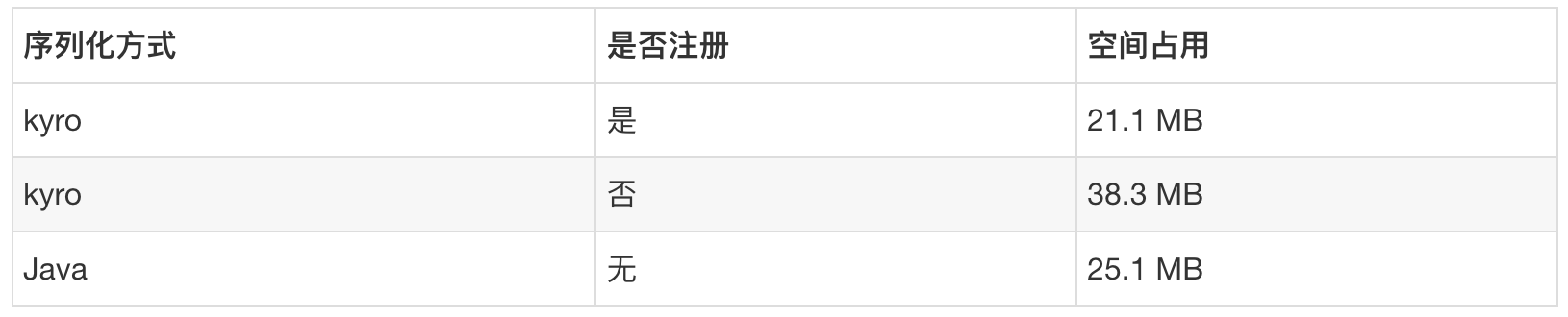
注意:虽说该步不是必须要做的(不做Kryo仍然能够工作),但是如果不注册的话,Kryo会存储自定义类中用到的所有对象的类名全路径,这将会导致耗费大量内存,耗费内存比使用java更大。
3. 配置 spark.kryoserializer.buffer
如果要被序列化的对象很大,可以将spark.kryoserializer.buffer (默认64k)设置的大些,使得其能够hold要序列化的最大的对象。
参考:
https://blog.51cto.com/u_12902538/3727315
尚硅谷2024spark教程


















 3187
3187

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











