




 本文深入讲解了Spark Core中的Action算子及其应用场景,并介绍了控制算子persist与checkpoint的使用技巧,帮助开发者提升Spark应用的性能。
本文深入讲解了Spark Core中的Action算子及其应用场景,并介绍了控制算子persist与checkpoint的使用技巧,帮助开发者提升Spark应用的性能。
【算子3】spark(五):spark core:控制算子(cache、persist)和action算子和checkpoint
文章目录
一. Action 行动算子
1. 行动算子概述
一、无输出
foreach(func):在数据集的每一个元素上,运行函数func进行更新
二、输出到文件系统
saveAsTextFile(path):将数据集的元素以textfile的形式保存到HDFS文件系统或者其他支持的文件系统
saveAsSequenceFile(path) :将数据集中的元素以Hadoop sequencefile的格式保存到指定的目录下,可以使HDFS或者其他Hadoop支持的文件系统
saveAsObjectFile(path):用于将RDD中的元素序列化成对象,存储到文件中
三、Scala集合和数据类型
reduce(func):通过func函数聚集RDD中的所有元素,先聚合分区内数据,再聚合分区间数据
collect() : 在驱动程序(Driver)中,以数组的形式返回数据集的所有元素
count():返回元素个数
take(n):返回RDD中前n个元素组成的数组
takeOrdered(n):返回该RDD排序后前n个元素组成的数据
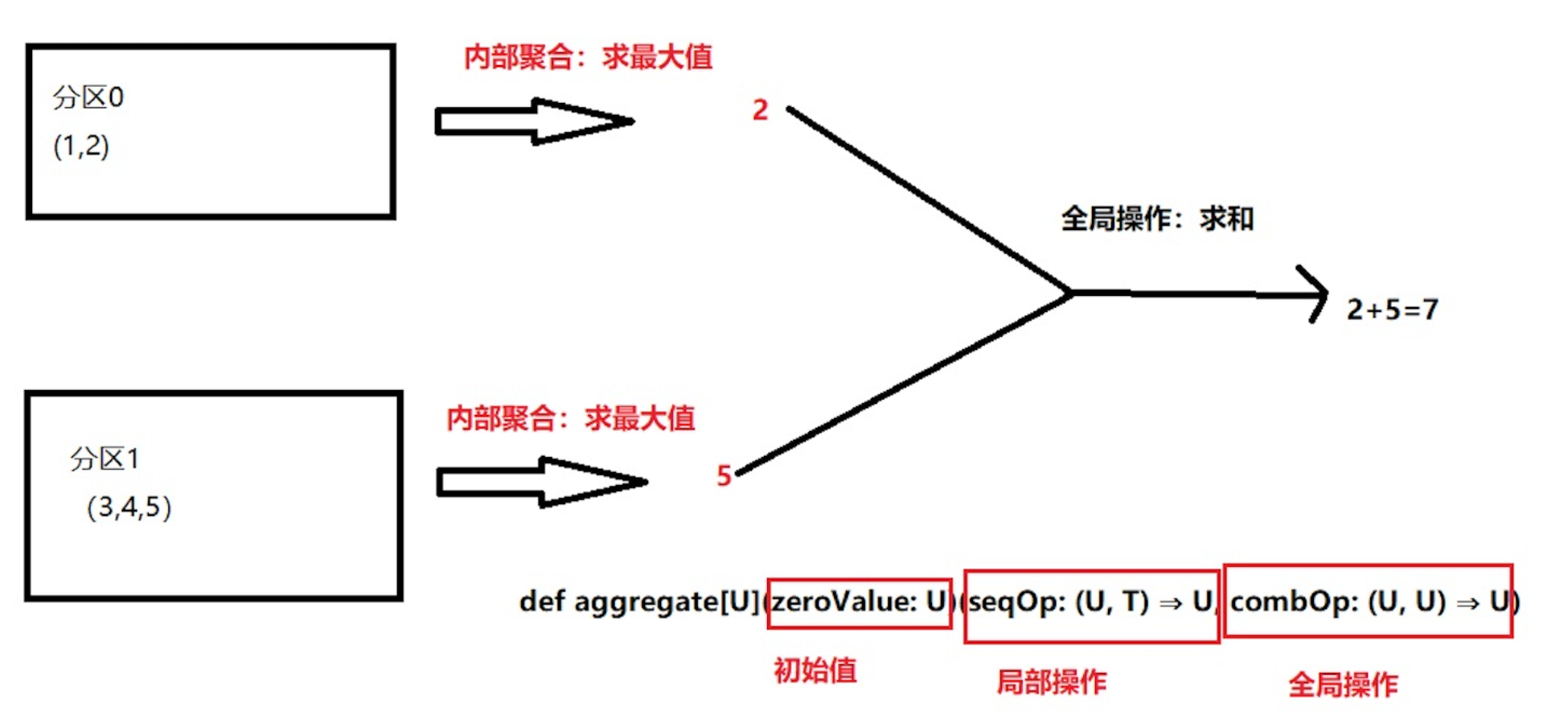
aggregate():先对局部聚合,再对全局聚合
fold(num)(func):aggregate的简化操作
countByKey():针对(K,V)类型的RDD,返回一个(K,Int)的map,即每个key出现的次数
2. 行动算子使用
reduce
val listRDD: RDD[Int] = sc.makeRDD(List(1,11,5,6,7))
//1、k数据求和
println(listRDD.reduce(_+_))
//2、kv数据相加
val rdd2 = sc.makeRDD(Array(("a",1),("a",3),("c",3),("d",5)))
println(rdd2.reduce((x,y)=>(x._1+y._1,x._2+y._2)))
collect()、count()、first()、take(n)、takeOrdered(n)
listRDD.collect().foreach(println)
println(rdd2.count())
println(rdd2.first())
listRDD.take(2).foreach(println)
listRDD.takeOrdered(2).foreach(println)
aggregate()/fold()
两个都是聚合函数:先分区内聚合,然后再分区外聚合。
fold()函数
aggregate的简化操作:分区内和分区间的操作都是一致的。
println(listRDD.fold(0)(_ + _))
aggregate
函数说明
统计一下在raw这个list中,比"f"大与比"f"小的元素分别有多少个。
val raw = List("a", "b", "d", "f", "g", "h", "o", "q", "x", "y")
val (biggerthanf, lessthanf) = sc.parallelize(raw, 1).aggregate((0, 0))(
//分区内的统计逻辑
(cc, str) => {
var biggerf = cc._1
var lessf = cc._2
if (str.compareTo("f") >= 0) biggerf = cc._1 + 1
else if(str.compareTo("f") < 0) lessf = cc._2 + 1
(biggerf, lessf)
},
//分区外的统计逻辑
(x, y) => (x._1 + y._1, x._2 + y._2)
)
二. 控制算子与检查点
两者的作用:当血缘关系比较长会运行效率较差,此时通过缓存或者checkpoint,可以提高效率。
1. persist或cache
概述
RDD通过persist或cache方法可以将之前rdd的计算结果(所有数据的))进行缓存。触发action之后,该RDD将会被缓存到节点的内存中(默认),供重复使用。
persist/cache的区别
• Cache调用了persist方法,且只有一个缓存级别MEMORY_ONLY
• persist可以根据情况设置其他的缓存级别
注意:使用内存级缓存时注意:当数据达到内存放不下时就会报溢出
缓存级别
存储在磁盘、内存,存储两份,序列化
堆外内存:非JVM中的内存
使用
val conf = new SparkConf().setMaster("local[6]").setAppName("debug_string")
val sc = new SparkContext(conf)
val interimRDD = sc.textFile("dataset/access_log_sample.txt")
.map(item => (item.split(" ")(0), 1))
.filter(item => StringUtils.isNotBlank(item._1))
.reduceByKey((curr, agg) => curr + agg)
.cache() //interimRDD 的结果进行缓存
val resultLess = interimRDD.sortBy(item => item._2, ascending = true).first()
val resultMore = interimRDD.sortBy(item => item._2, ascending = false).first()
println(s"出现次数最少的 IP : $resultLess, 出现次数最多的 IP : $resultMore")
sc.stop()
cache之后一定不能立即有其它算子,不能直接去接算子。因为在实际工作的时候,cache后有算子的话,它每次都会重新触发这个计算过程。
2. 检查点
当血缘过长(多个action串联)时容错成本会提高,可以在中间计算阶段做检查点容错。当有节点出现分区(数据)丢失时,可以从检查点的RDD开始根据血缘进行计算,减少开销
触发:checkpoint的操作也是在Action算子后触发
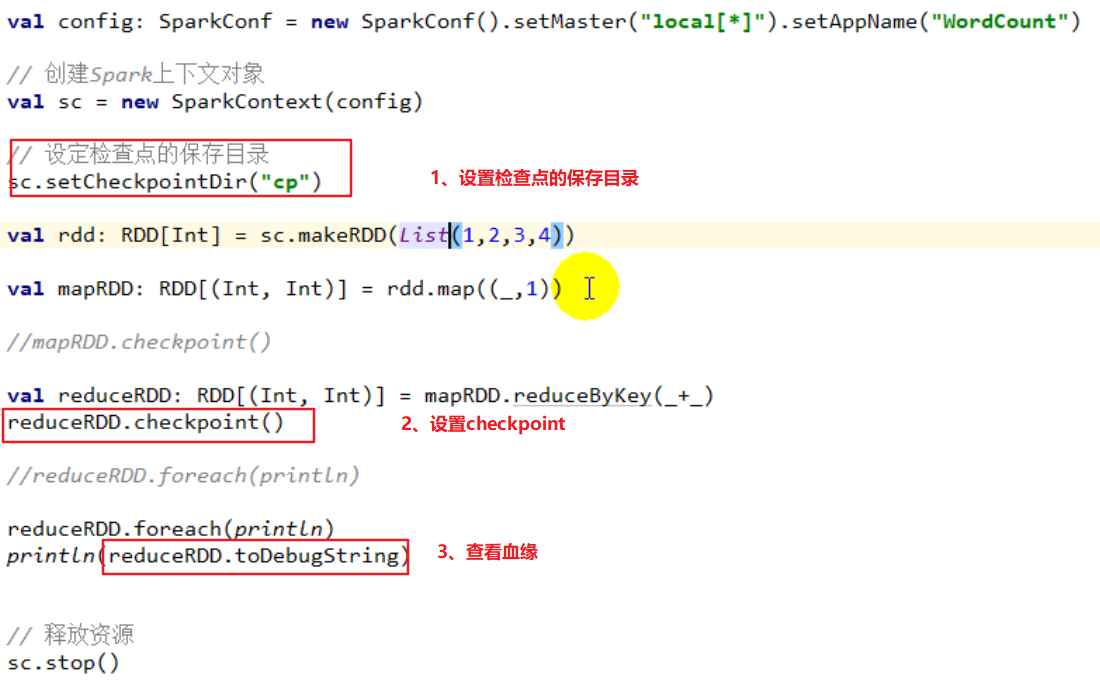
特点:
将血缘关系保存成文件,即使是宕机文件也不会丢失。保存在HDFS上则会实现,高容错
此时RDD不会记录完整的血缘关系,因为可以从检查点重新计算血缘


















 964
964

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











