







 本文探讨Python爬虫实战中遇到的开发者工具与代码抓取网页源码数据差异问题。通过案例分析,解释了前端JS渲染导致的采集难题,并提供了如何解码URL编码进行数据抓取的方法。
本文探讨Python爬虫实战中遇到的开发者工具与代码抓取网页源码数据差异问题。通过案例分析,解释了前端JS渲染导致的采集难题,并提供了如何解码URL编码进行数据抓取的方法。
本篇博客是一个小小的 Python 爬虫实践,重点为解释在 Python 爬虫实战过程中,浏览器的开发者工具和代码抓取的网页源码,存在数据差异。
翻译一下就是开发者工具和爬虫采集到的源码,不一样。
本次案例来源为 《Python 爬虫 120》 专栏订阅者,5 年保爬虫更新。
⚡⚡ 学习注意事项 ⚡⚡
文章会自动省略http和https协议,学习时请自行在地址中进行补充。
目标站点域名为uisdc.com,在下文统一用橡皮擦代替,学习时请自行拼接。
文章目录
⛳️ 实战场景
如果你的目标是采集前文提及的站点,那你会碰到下述场景。使用开发者工具的【选择元素】操作时,选中目标元素,得到的 element 节点如下所示。
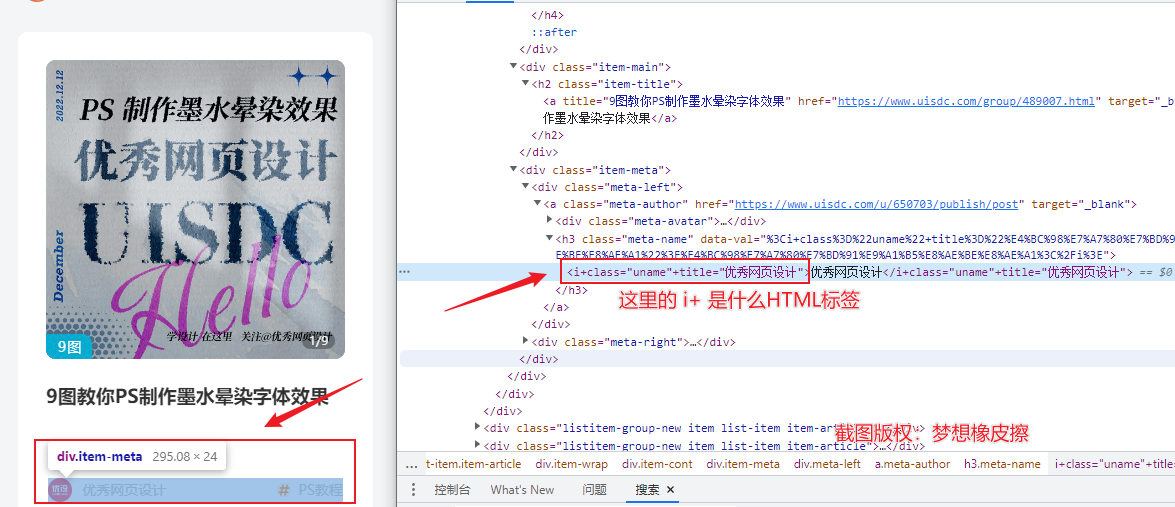
选定目标后,将得到一个名为 i+ 的标签。许多刚刚学习 Python 爬虫的爱好者可能不太了解这个标签的含义,这可能导致无法进行采集。
该标签其实是由前端 JS 脚本渲染而

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











