







 本文介绍了使用Python Scrapy框架进行爬虫项目实践,重点讲解了Scrapy管道的运用,目标是爬取在行网站的高手数据并存储到MySQL数据库。首先分析目标站点,设计数据库表结构,然后编写爬虫代码,包括分页处理和数据解析。在settings.py中启用ITEM_PIPELINES,并在pipelines.py中定义保存数据到数据库的逻辑。文章还展示了爬取结果,并鼓励读者关注和互动。
本文介绍了使用Python Scrapy框架进行爬虫项目实践,重点讲解了Scrapy管道的运用,目标是爬取在行网站的高手数据并存储到MySQL数据库。首先分析目标站点,设计数据库表结构,然后编写爬虫代码,包括分页处理和数据解析。在settings.py中启用ITEM_PIPELINES,并在pipelines.py中定义保存数据到数据库的逻辑。文章还展示了爬取结果,并鼓励读者关注和互动。
本篇博客的重点为 scrapy 管道 pipelines 的应用,学习时请重点关注。
爬取目标站点分析
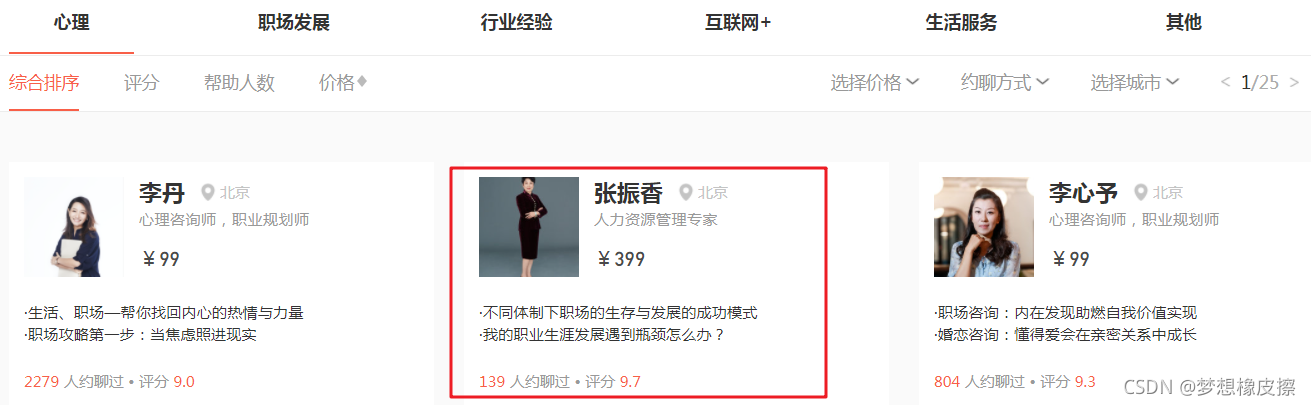
本次采集的目标站点为:https://www.zaih.com/falcon/mentors,目标数据为在行高手数据。
本次数据保存到 MySQL 数据库中,基于目标数据,设计表结构如下所示。
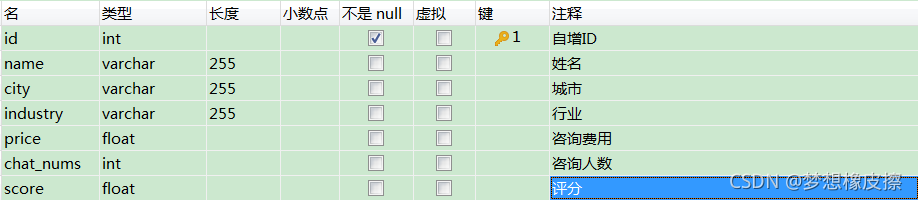
对比表结构,可以直接将 scrapy 中的 items.py 文件编写完毕。
class ZaihangItem(scrapy本篇博客的重点为 scrapy 管道 pipelines 的应用,学习时请重点关注。
本次采集的目标站点为:https://www.zaih.com/falcon/mentors,目标数据为在行高手数据。
本次数据保存到 MySQL 数据库中,基于目标数据,设计表结构如下所示。
对比表结构,可以直接将 scrapy 中的 items.py 文件编写完毕。
class ZaihangItem(scrapy
 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言





 订阅专栏 解锁全文
订阅专栏 解锁全文

























