







 这篇博客介绍了如何利用Python的CrawlSpider库进行二维抓取,目标站点是阅文集团作家中心。博主详细讲解了CrawlSpider的基本知识,包括LinkExtractor和Rule的使用,并展示了如何提取分页链接和内容详情页的标题。在编码实践中,重点在于设置URL提取规则和回调函数,以实现爬虫的自动化。文章还提及可以重写CrawlSpider的特定方法以进一步定制爬取行为。
这篇博客介绍了如何利用Python的CrawlSpider库进行二维抓取,目标站点是阅文集团作家中心。博主详细讲解了CrawlSpider的基本知识,包括LinkExtractor和Rule的使用,并展示了如何提取分页链接和内容详情页的标题。在编码实践中,重点在于设置URL提取规则和回调函数,以实现爬虫的自动化。文章还提及可以重写CrawlSpider的特定方法以进一步定制爬取行为。
本篇博客学习使用 CrawlSpider 进行二维抓取。
目标站点分析
本次要采集的目标站点为:阅文集团作家中心
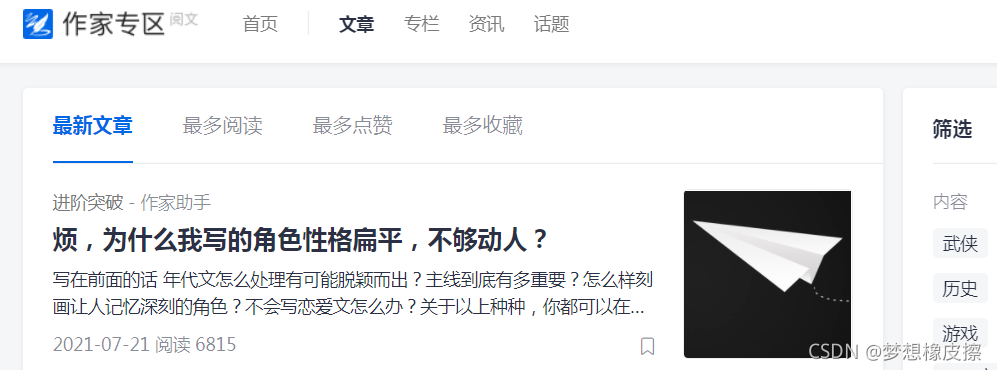
分页地址具备一定规则,具体如下:
https://write.qq.com/portal/article?filterType=0&page={页码}
由于本文重点学习内容为简单操作 scrapy 实现爬虫,所以目标详情页仅提取标题即可。
知识说明
本篇博客生成爬虫文件,使用 scrapy genspider -t crawl yw write.qq.com,默认生成的代码如下所示:
import scrapy
from scrapy.linkextrac
 订阅专栏 解锁全文
订阅专栏 解锁全文


















 37万+
37万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











