







 本文介绍了一个Python爬虫案例,采用多线程+队列技术,目标是抓取提供网站排行榜数据的站点,样本数量为58341。爬虫逻辑包括请求第一页获取总页码,通过生产者-消费者模型处理分页,解析目标数据。代码仓库已分享,供学习参考。
本文介绍了一个Python爬虫案例,采用多线程+队列技术,目标是抓取提供网站排行榜数据的站点,样本数量为58341。爬虫逻辑包括请求第一页获取总页码,通过生产者-消费者模型处理分页,解析目标数据。代码仓库已分享,供学习参考。
今天要实现的是《爬虫120例》中的第28例,采用的技术方案为多线程+队列。
目标站点分析
本次要抓取的目标站点为:\u4e2d\u4ecb\u7f51,这个网站提供了网站排行榜、互联网网站排行榜、中文网站排行榜等数据。
网站展示的样本数据量是 :58341。
采集页面地址为 Python爬虫地址自己找/top/rank_all_1.html,UI如下所示:
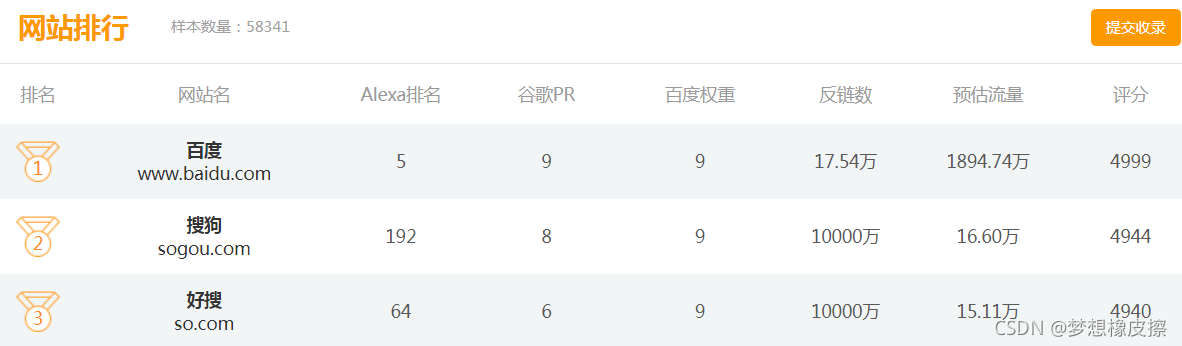
由于页面存在一个【尾页】超链接,所以直接通过该超链接获取累计页面即可。
其余页面遵循简单分页规则:
Python爬虫地址/top/rank_all_1.html
Python爬虫地址/top/rank_all_2.html
基于此,本次Python爬虫的解决方案如下,页面请求使用 requests 库,页面解析使用 lxml,多线程使用 threading 模块,队列依旧采用 queue 模块。
编码时间
在正式编码前,先通过一张图将逻辑进行梳理。
本爬虫编写步骤文字描述如下:

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











