







 该博客分享了一次针对全国美食网站的爬虫实战,目标站点数据源分析,使用Python的queue模块进行数据抓取。尽管网页响应速度较慢,但没有反爬策略,通过增加请求等待时间解决。文章中提到,使用2个线程和队列机制,配合requests库完成数据提取,最后整理并展示了爬取的50000条数据。代码已上传至CodeChina仓库,并邀请读者关注、点赞和收藏。
该博客分享了一次针对全国美食网站的爬虫实战,目标站点数据源分析,使用Python的queue模块进行数据抓取。尽管网页响应速度较慢,但没有反爬策略,通过增加请求等待时间解决。文章中提到,使用2个线程和队列机制,配合requests库完成数据提取,最后整理并展示了爬取的50000条数据。代码已上传至CodeChina仓库,并邀请读者关注、点赞和收藏。
本次要抓取的目标网站为【\u6574\u5f62\u533b\u751f\u6570\u636e】,其中用到的 queue 模块,需要在 预备知识篇 进行学习。
目标站点数据源分析
目标地址为:www.参考源码.net%2Fd%2Fpg_1%2F,爬取数据区域如下图所示:
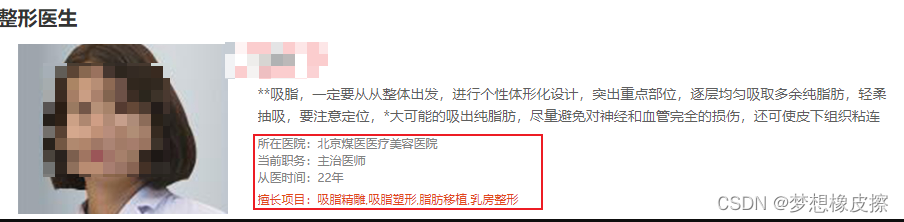
整理目标数据格式为:
姓名,所在医院,当前职务,从医时间,擅长项目
分页规则如下:
Python爬虫加密地址/d/pg_1/
Python爬虫加密地址/d/pg_2/
其中 pg_页码 为页码跳转规则,可以通过代码爬取获取,也可以直接手动输入。
测试过程中发现网页响应速度有点慢,但是没有反爬措施,顾将请求等待时间设置的长一些即可实现。
编码时间
下述编码中使用到了 queue 模块,即队列机制,不过并没有使用生产者与消费者模型,所谓的生产

 订阅专栏 解锁全文
订阅专栏 解锁全文


















 3323
3323

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











