




 本文探讨了内部协变量漂移(Internal Covariate Shift, ICS)在深度学习中带来的问题,包括降低网络学习速度和导致梯度饱和。介绍了白化作为解决方法,但指出其计算成本高且可能削弱数据表达能力。随后,文章提出了BatchNormalization作为简化版的白化方法,旨在加速网络训练收敛,同时保持数据的原始表达能力。BatchNormalization通过对mini-batch进行规范化处理来实现这一目标。
本文探讨了内部协变量漂移(Internal Covariate Shift, ICS)在深度学习中带来的问题,包括降低网络学习速度和导致梯度饱和。介绍了白化作为解决方法,但指出其计算成本高且可能削弱数据表达能力。随后,文章提出了BatchNormalization作为简化版的白化方法,旨在加速网络训练收敛,同时保持数据的原始表达能力。BatchNormalization通过对mini-batch进行规范化处理来实现这一目标。
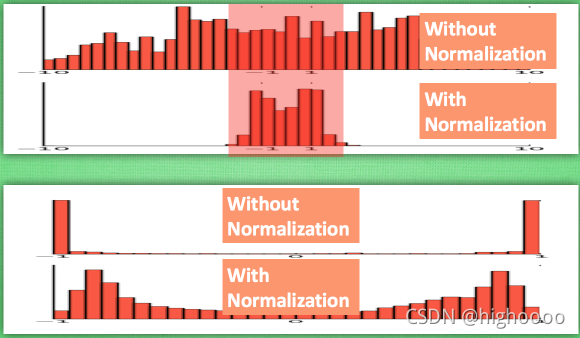
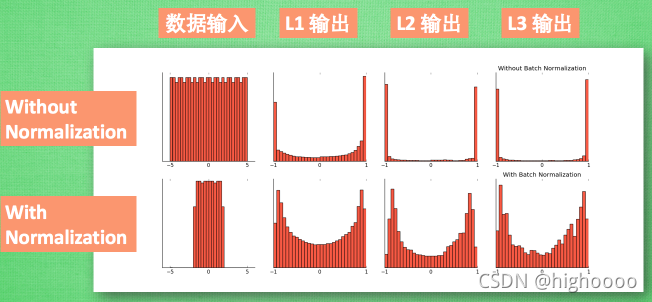
1.3 Internal Covariate Shift会带来什么问题?
(1)上层网络需要不停调整来适应输入数据分布的变化,导致网络学习速度的降低
我们在上面提到了梯度下降的过程会让每一层的参数 [公式] 和 [公式] 发生变化,进而使得每一层的线性与非线性计算结果分布产生变化。后层网络就要不停地去适应这种分布变化,这个时候就会使得整个网络的学习速率过慢。
(2)网络的训练过程容易陷入梯度饱和区,减缓网络收敛速度
当我们在神经网络中采用饱和激活函数(saturated activation function)时,例如sigmoid,tanh激活函数,很容易使得模型训练陷入梯度饱和区(saturated regime)。随着模型训练的进行,我们的参数 [公式] 会逐渐更新并变大,此时 [公式] 就会随之变大,并且 [公式] 还受到更底层网络参数 [公式] 的影响,随着网络层数的加深, [公式] 很容易陷入梯度饱和区,此时梯度会变得很小甚至接近于0,参数的更新速度就会减慢,进而就会放慢网络的收敛速度。
对于激活函数梯度饱和问题,有两种解决思路。第一种就是更为非饱和性激活函数,例如线性整流函数ReLU可以在一定程度上解决训练进入梯度饱和区的问题。另一种思路是,我们可以让激活函数的输入分布保持在一个稳定状态来尽可能避免它们陷入梯度饱和区,这也就是Normalization的思路。
1.4 我们如何减缓Internal Covariate Shift?
要缓解ICS的问题,就要明白它产生的原因。ICS产生的原因是由于参数更新带来的网络中每一层输入值分布的改变,并且随着网络层数的加深而变得更加严重,因此我们可以通过固定每一层网络输入值的分布来对减缓ICS问题。
(1)白化(Whitening)
白化(Whitening)是机器学习里面常用的一种规范化数据分布的方法,主要是PCA白化与ZCA白化。白化是对输入数据分布进行变换,进而达到以下两个目的:
使得输入特征分布具有相同的均值与方差。其中PCA白化保证了所有特征分布均值为0,方差为1;而ZCA白化则保证了所有特征分布均值为0,方差相同;
去除特征之间的相关性。
通过白化操作,我们可以减缓ICS的问题,进而固定了每一层网络输入分布,加速网络训练过程的收敛(LeCun et al.,1998b;Wiesler&Ney,2011)。
(2)Batch Normalization提出
既然白化可以解决这个问题,为什么我们还要提出别的解决办法?当然是现有的方法具有一定的缺陷,白化主要有以下两个问题:
白化过程计算成本太高,并且在每一轮训练中的每一层我们都需要做如此高成本计算的白化操作;
白化过程由于改变了网络每一层的分布,因而改变了网络层中本身数据的表达能力。底层网络学习到的参数信息会被白化操作丢失掉。
既然有了上面两个问题,那我们的解决思路就很简单,一方面,我们提出的normalization方法要能够简化计算过程;另一方面又需要经过规范化处理后让数据尽可能保留原始的表达能力。于是就有了简化+改进版的白化——Batch Normalization。
2 Batch Normalization
2.1 思路
既然白化计算过程比较复杂,那我们就简化一点,比如我们可以尝试单独对每个特征进行normalizaiton就可以了,让每个特征都有均值为0,方差为1的分布就OK。
另一个问题,既然白化操作减弱了网络中每一层输入数据表达能力,那我就再加个线性变换操作,让这些数据再能够尽可能恢复本身的表达能力就好了。
因此,基于上面两个解决问题的思路,作者提出了Batch Normalization,下一部分来具体讲解这个算法步骤。
2.2 算法
在深度学习中,由于采用full batch的训练方式对内存要求较大,且每一轮训练时间过长;我们一般都会采用对数据做划分,用mini-batch对网络进行训练。因此,Batch Normalization也就在mini-batch的基础上进行计算。

















 1974
1974

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









