







前言:
之前的章节中,我们已经学习了Linux的众多基础指令.现在,我们将进一步探索Linux强大的文本处理能力,这些指令在日常系统管理、日志分析和数据处理中扮演着至关重要的角色。
在本篇博客中,我们将重点介绍几个高效的文本查看与统计命令:
more和less—— 分页查看文件内容,避免终端输出过长导致的信息淹没
head和tail—— 快速查看文件的开头或末尾部分,尤其适用于日志分析
wc—— 统计文件内容的信息,常用于脚本编写和数据统计
whereis—— 快速定位命令的可执行文件、源码和手册位置
这些命令虽然简单,但组合使用时能极大提升工作效率。无论是分析日志、调试代码,还是编写Shell脚本,它们都是不可或缺的工具。接下来,让我们深入探索它们的使用技巧和实际应用场景!

如果对前面的内容不了解可以传送回去复习。
目录
零、 存在more/tail/head/tail的理由
1.cat缺陷
在前面的学习当中,我们了解了一个cat指令它同样是查看文件,可是既然有了一个cat为啥还要有下面的指令呢?
对于cat,我们前面输出的都是一些比较小的文件,那么如果遇到大的文件它还可以吗?
我们肯定不能自己一个一个敲进去,所以我们使用如下的简单程序创建一个大文本,最终我们可以看到在屏幕上打印了1w行文本
代码:
1 #include<stdio.h>
2
3
4 int main()
5 {
6
7 for(int i=0;i<10000;i++)
8 {
9 printf("这是第%d行\n",i);
10 }
11
12 return 0;
13 }
有了这样的效果,现在我们不让他打印到屏幕上,而是重定向到一个文件中
![]()
如果我们直接cat的话,会直接打印出来1w行,这太不便于查看某特定的一行。
所以说,cat不适合看大文本,cat适合看小文本
而操作系统也增添了我们一开始所说的几个指令,用于大文本文件的查看。
2.为啥要读大文件。
1. 避免内存和性能问题
大文件加载慢:直接用
vim或编辑器打开大文件(如几 GB 的日志)时,操作系统会尝试将整个文件加载到内存中,可能导致内存不足或卡顿。
less/more的流式读取:它们按需逐页加载文件,不会一次性占用大量内存,适合处理超大文件。2. 交互式浏览体验更好
分页显示:
more和less会将内容分页显示(按屏幕高度逐页展示),避免cat一次性输出全部内容导致终端快速滚动。
more:只能向下翻页,不支持回退。(传统Unix系统不支持,但在我们选择的CentOS 7当中支持按”b“回退)
less:更强大,支持上下滚动、搜索、跳转等(类似vim的快捷键)。3. 快速定位关键信息
搜索功能:
less支持正则表达式搜索(如/error快速定位错误日志),而cat需要结合grep(如cat file | grep "error")。
一、more指令
more 是一个基础的分页文本查看工具,允许用户逐屏浏览文件内容。它支持向前翻页(空格键)和基本搜索功能,但不支持向后翻页。适合快速查看中小型文件,是早期Unix系统中less的前身。
more
语法:more [选项][文件]
功能:more命令,功能类似 cat
常用选项:
-n 对输出的所有行编号
q 退出more
常用操作:
- 空格键: 显示下一页的内容
- 回车键: 显示下一行的内容
- b: 往回(向上)翻页,即显示上一页的内容
- f: 往前(向下)翻页,功能与空格键相同
- q: 退出 more
演示:
1)普通版,不带选项
如下所示,我们直接输入指令
more test.txt
那么就会是下面的这样子,只会打印出一个屏幕,然后不在打印

当我们想往下继续看的时候,我们直接按住回车/空格,它就会自顶向下,自动往下翻 ;
想往上翻,就按住f键就好。
当然这个连续的效果,不好展示大家可以自己试验一下。
2)-n
我们还可以对more指令带上一个数字选项,代表着到第多少行停止,如下面的就是到第100行停止
more -100 test.txt

3)/ + n
通过“/+n”快速找到某个特定的一行。
当我们想要查看一个文件的内容,但又不想一次性将整个文件内容全部加载到终端(或屏幕)上时,可以用more代替cat。
但是more指令我们也不常用,因为我们更方便的less来代替more。
二、less指令
less 是more的增强版,提供更灵活的文本浏览功能。支持前后翻页(PageUp/PageDown)、搜索高亮、跳转行号等高级操作,且不会一次性加载整个文件,适合查看大型日志或配置文件。可通过“/”搜索内容,按q退出。
less
语法: less [参数] 文件
功能:less与more类似,但使用less可以随意浏览文件,而且less在查看之前不会加载整个文件。
常用选项:
- -N 显示每行的行号
- / 字符串:向下搜索“字符串”的功能
- ? 字符串:向上搜索“字符串”的功能
- n :重复前一个搜索
- N:反向重复前一个搜索
- q:退出查看文件的界面。
注:less支持“上下左右”键来查看文件的上下内容, 但是不可以像more一样直接less -n进行定位。
演示:
1)普通版本
2)-N
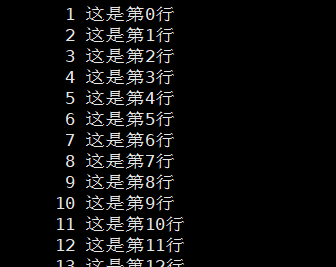
3)/n 与 ?n
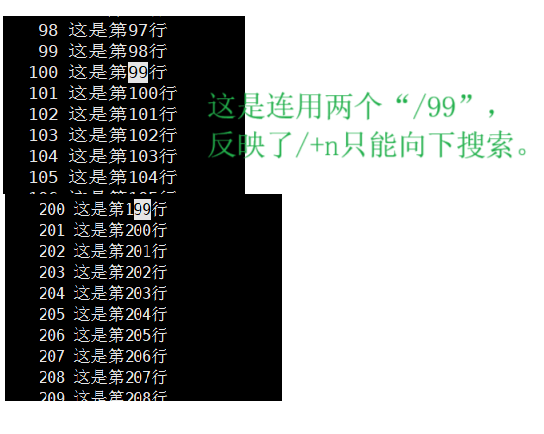
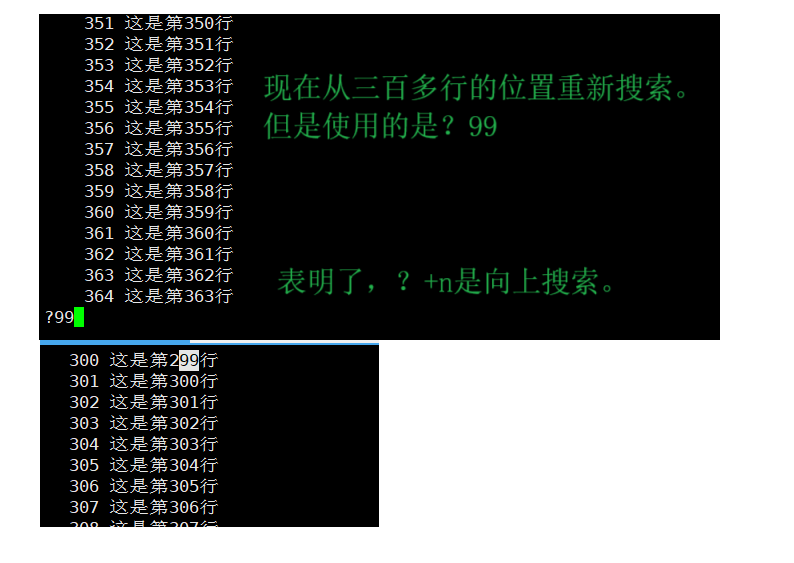
三、head
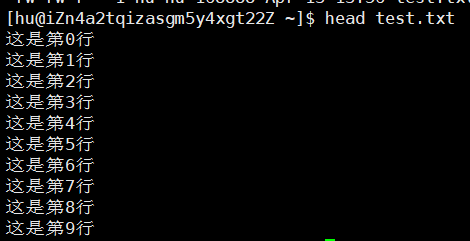
head 用于显示文件开头部分,默认输出前10行。常用参数-n可指定行数,适合快速检查文件结构或提取样本数据,尤其在处理未知文件时非常实用。
head
- 语法: head [参数]… [文件]…
- 功能:head 用来显示档案的开头至标准输出中,默认head命令打印其相应文件的开头10行。
- 选项:
-n<行数> 只显示前n行的内容。
演示 :
1)普通版本
2)-n
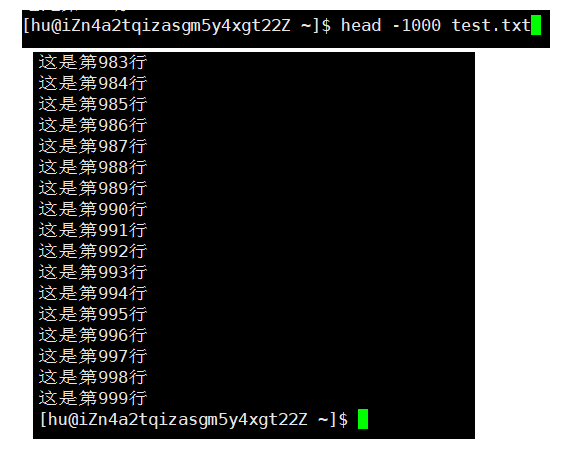
四、tail
tail 与head相反,专注文件末尾内容,默认输出最后10行。关键参数-f(follow)能实时追踪文件更新(如日志监控)。
tail
- 语法:head [参数]… [文件]…
- 功能: 用于显示指定文件末尾内容,不指定文件时,作为输入信息进行处理。常用查看日志文件。
- 选项:
-f 循环读取
-n<行数> 显示行数
演示:
1)普通版本
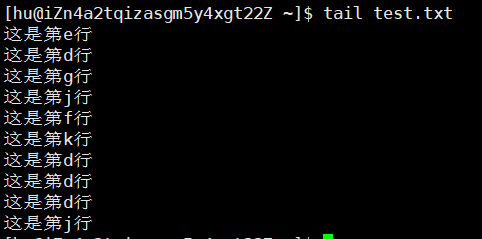
2)-f
tail -f命令中的"循环读取"指的是该命令会持续监控文件的变化并输出新增内容的行为。工作原理
初始读取:首先显示文件的最后10行(默认)或指定行数
持续监控:然后进入循环等待状态,不断检查文件是否有新内容追加
实时输出:当检测到文件有新内容写入时,立即将这些新内容输出到屏幕
特点
- 不会退出:与普通
tail不同,-f选项会使命令持续运行而不退出- 实时性:几乎是即时显示新写入的内容(通常有短暂的延迟)
- 低开销:使用高效的文件监控机制(如inotify)而非不断轮询
现在我像原本文件当中新增内容,观察现象
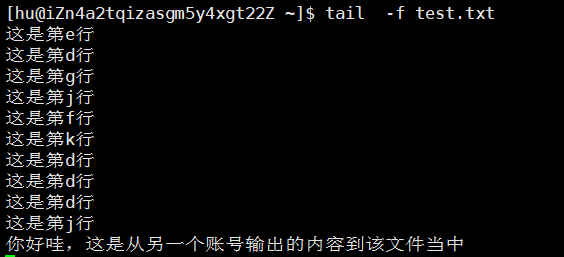
![]() 可以发现我们的指令一直处于检测状态,将新增内容输出出来。
可以发现我们的指令一直处于检测状态,将新增内容输出出来。
对大文件处理
当然在学习完上面的四个指令后面,我们就可以对一个大文件进行信息截取,但是具体的实现和相关新概念,我就不在这里赘述了,还是像之前那样,会有专门的博客进行介绍。
五、wc
wc 是一个常用的 Linux/Unix 命令,用于统计文件或输入流中的行数、单词数和字节数。
wc
- 用法:wc 【选项】[文件名]
- 用途:
统计行数:计算文件中的行数
统计单词数:计算文件中的单词数(以空格分隔)
统计字节数:计算文件的字节大小
统计字符数:计算文件中的字符数
- 常用选项:
选项 功能描述 -l只显示行数 -w只显示单词数 -c只显示字节数 -m只显示字符数 -L显示最长行的长度
演示
1)-l

其他的选项用法相同,在这里我就不再一一赘述了。
六、whereis
whereis 快速定位命令的二进制文件、源码和手册位置。相比which,它能同时返回帮助文档路径(如whereis python)。适合确认软件安装位置或排查环境问题。
whereis
- 语法:whereis 【选项】【命令名】
- 用途:
查找命令的可执行文件位置
查找命令的源代码位置(如果存在)
查找命令的手册页位置
常用选项
选项 功能描述 -b只搜索二进制文件 -m只搜索手册页 -s只搜索源代码 -u搜索不常见的条目 -B指定二进制文件的搜索路径 -M指定手册页的搜索路径 -S指定源代码的搜索路径
演示:
1)普通版本

其他选项用法一样这里就不再赘述,大家可以自己尝试一下。
总结
今天我们主要学习到了关于大文本文件的读取,那么我们的LInux的基础指令的学习就要告一段落了,但是在Linux仍然会有大量的指令等着我们学习,不过那些就是在后面的学习当中穿插的讲解了,码字不易,看到这里的你能否点一个免费的赞呢。



















 6844
6844

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









