




 本文详细介绍如何使用SQL窗口函数Dense Rank对员工薪水进行排名,对比RANK和ROW_NUMBER函数,通过具体案例演示相同薪水并列排名的实现方法。
本文详细介绍如何使用SQL窗口函数Dense Rank对员工薪水进行排名,对比RANK和ROW_NUMBER函数,通过具体案例演示相同薪水并列排名的实现方法。
窗口函数 dense_rank()
题目描述
对所有员工的当前(to_date='9999-01-01')薪水按照salary进行按照1-N的排名,相同salary并列且按照emp_no升序排列
CREATE TABLE `salaries` (
`emp_no` int(11) NOT NULL,
`salary` int(11) NOT NULL,
`from_date` date NOT NULL,
`to_date` date NOT NULL,
PRIMARY KEY (`emp_no`,`from_date`));
输出描述
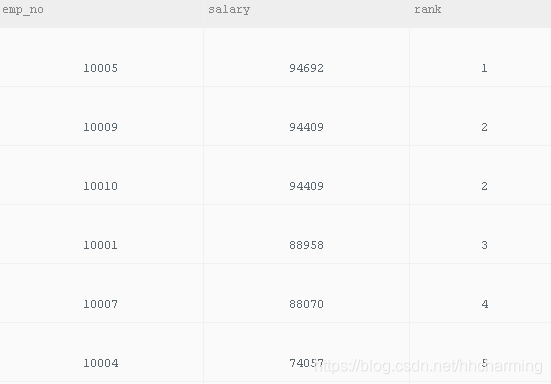
分析1:窗口函数法
三种用于进行排序的专用窗口函数
- 1.RANK()
在计算排序时,若存在相同位次,会跳过之后的位次。
例如,1,1,1,4······
- 2.DENSE_RANK()
题目中所用到的函数,在计算排序时,若存在相同位次,不会跳过之后的位次。
例如,1,1,1,2······
- 3.ROW_NUMBER()
这个函数赋予唯一的连续位次。
例如,有3条排在第1位时,排序为:1,2,3,4······
窗口函数用法:
<窗口函数> OVER ( [PARTITION BY <列清单> ]
ORDER BY <排序用列清单> )
其中[ ]中的内容可以忽略
select emp_no,salary,dense_rank() over (order by salary desc) as rank from salaries
where to_date='9999-01-01'
order by rank,emp_no
分析2:复用salaries表进行比较排名
1.s1.salary <= s2.salary,意思是在输出s1.salary的情况下,有多少个s2.salary大于等于s1.salary,比如当s1.salary=94409时,有3个s2.salary(分别为94692,94409,94409)大于等于它,但由于94409重复,利用COUNT(DISTINCT s2.salary)去重可得工资为94409的rank等于2。其余排名以此类推。
2.GROUP BY s1.emp_no,否则输出的记录只有一条,因为用了合计函数COUNT()
3.最后先以 rank排序,再以 s1.emp_no 顺序排列输出结果
select s1.emp_no,s1.salary,count(distinct s2.salary) as rank
from salaries as s1,salaries as s2
where s1.salary<=s2.salary
and s1.to_date='9999-01-01'
and s2.to_date='9999-01-01'
group by s1.emp_no
order by s1.salary desc,s1.emp_no asc
--或者order by rank

















 2014
2014

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









