







Code:
"Title":2021 ACM MM oral,北航和鹏城实验室
💡Whats New
- an Efficient and Effective SOD model
- 网络结构创新:
- U-shape → Trilateral Decoder(layer by layer → “coarse-fine-finer”)
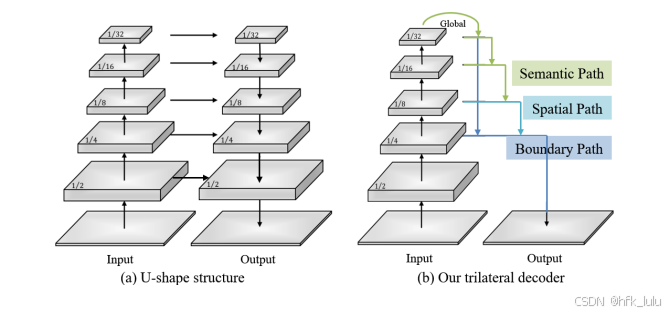
- U-shape的不足: ① 底层特征分辨率较大,导致计算复杂度大速度慢 ② 空间信息在下采样中丢失,仅合并层级特征很难恢复 ③ 高层语义信息被稀释,由于局限的感受野,全局上下文被忽略,导致欠分割 ④ 缺乏边界信息,导致边界分割质量差
- U-shape → Trilateral Decoder(layer by layer → “coarse-fine-finer”)
- 三个分支的Complementary体现在: ① 来自encoder的不同阶段,且encoder共享 ② 提出了三种融合模块
⌨️Paper with Code
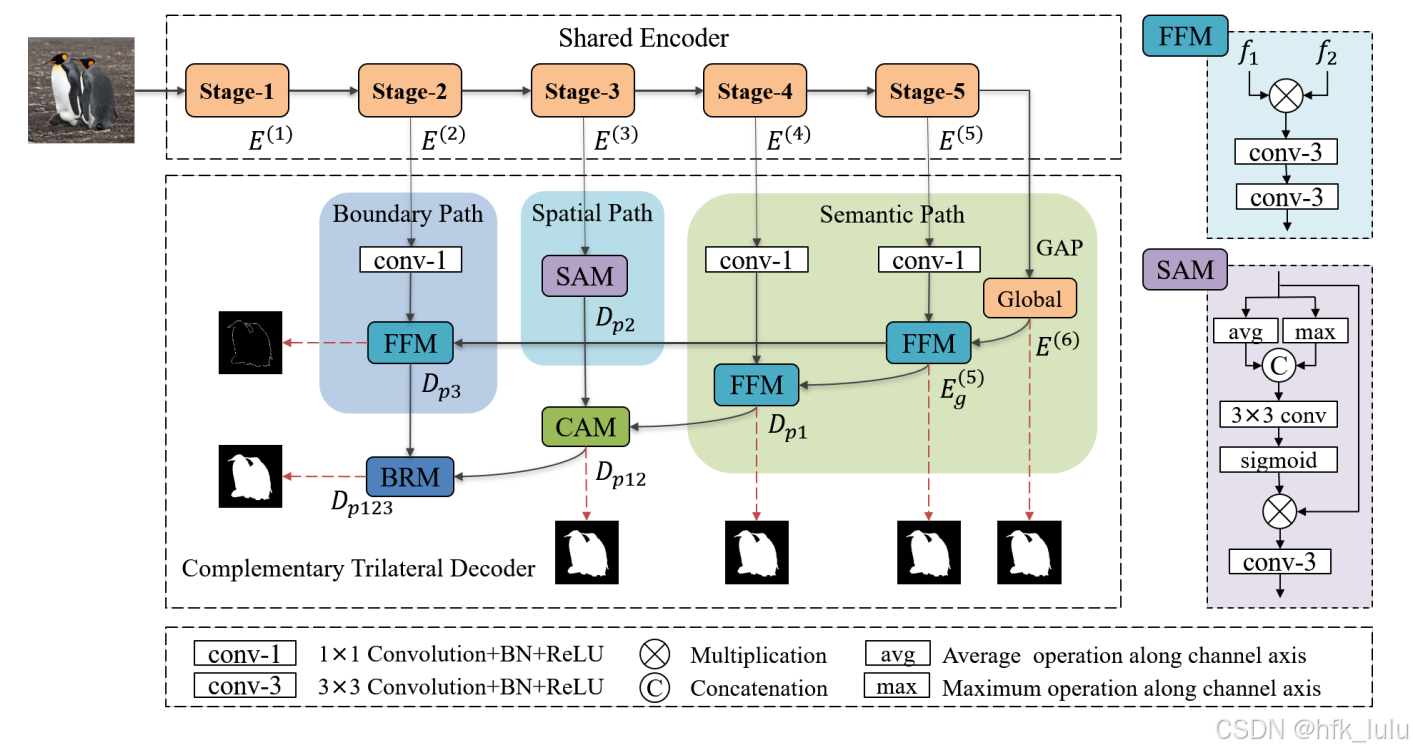
Encoder
- Backbone使用的是在ImageNet上预训练的ResNet-50/ResNet-18
- 舍弃最底层Stage-1,以加快计算速度
Decoder
Semantic Path
初始"coarse"阶段:通过较大的感受野,捕获丰富的语义上下文和全局上下文,获得显著目标的准确位置,粗糙的边界。
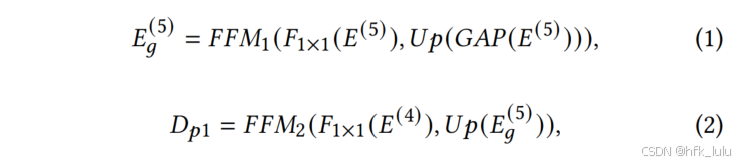
- 通道注意力机制:backbone尾部嵌入Global Average Pooling (GAP),数据最后两维降为1×1(相当于通道权重)
- 加快计算速度:对Stage-4和Stage-5使用1×1卷积+BN+ReLU (conv-1) 将通道数限制在64
- 局部U-shape结构:使用FFM融合GAP的上采样和最高两层(Stage-4和Stage-5)的特征
- FFM的融合策略:与相加或拼接相比,相乘运算可以避免冗余信息,抑制背景噪声,且更快。
![]()
# Feature Fusion Module
class FFM(nn.Module):
def __init__(self, channel):
'''两层卷积'''
super(FFM, self).__init__()
self.conv_1 = conv3x3(channel, channel)
self.bn_1 = nn.BatchNorm2d(channel)
self.conv_2 = conv3x3(channel, channel)
self.bn_2 = nn.BatchNorm2d(channel)
def forward(self, x_1, x_2):
out = x_1 * x_2 # x1和x2的特征融合即相乘
out = F.relu(self.bn_1(self.conv_1(out)), inplace=True)
out = F.relu(self.bn_2(self.conv_2(out)), inplace=True)
return out
def initialize(self):
weight_init(self)Special Path
相对"fine"阶段:保留更多的空间细节,获得显著目标的精确结构,较为精确的边界。
- 下采样8倍的特征:丰富的空间细节
- SAM空间注意力机制:在通道维度做全局平均池化和全局最大池化,合并这两个通道并卷积为单通道,+sigmoid函数映射到(0,1)作为注意力权重与所有通道的元素相乘,卷积至64通道
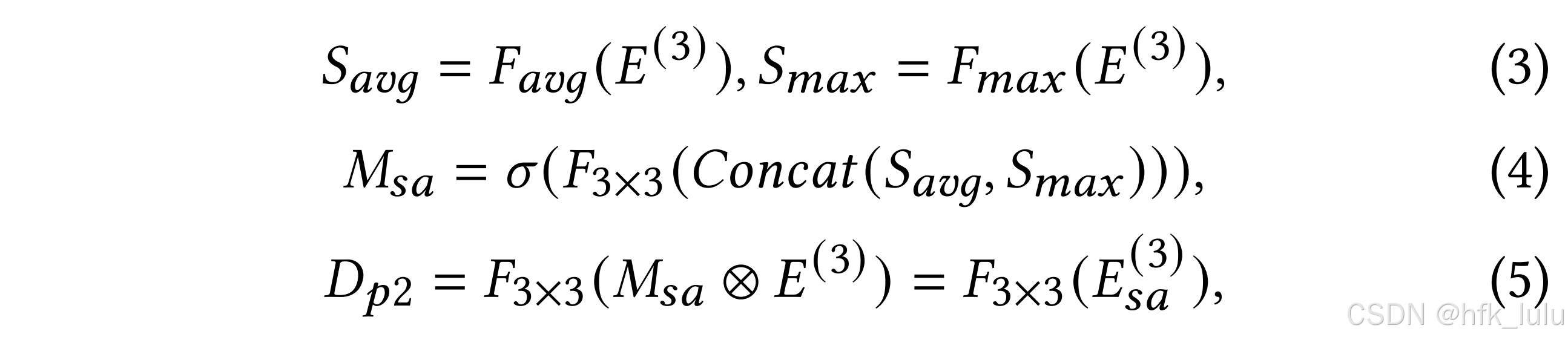
- CAM的融合策略:针对互补的Dp1和Dp2,上下采样(Dp2分辨率是Dp1的两倍,分别bilinear插值至对方的分辨率),交叉融合(两种分辨率分别做积并卷积,将低分辨率的特征上采样再用FFM融合),以增强特征表达
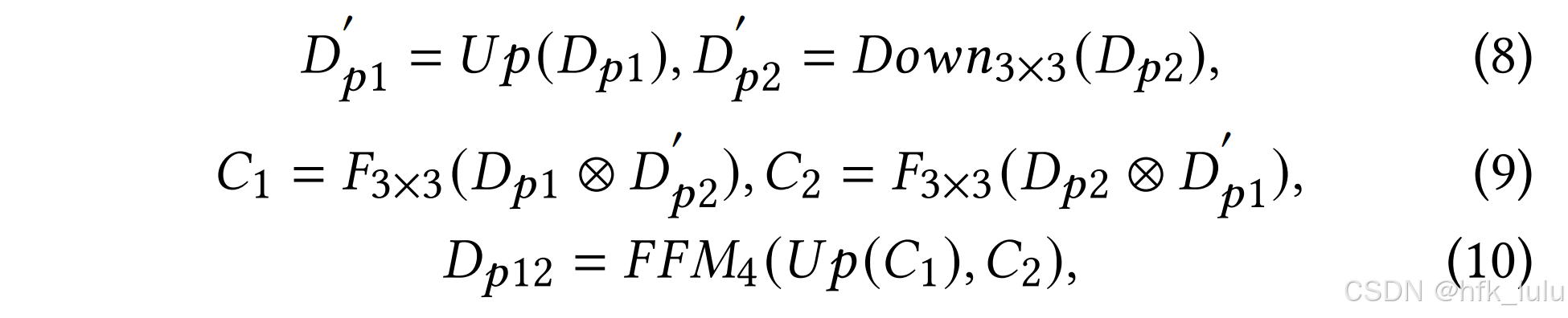
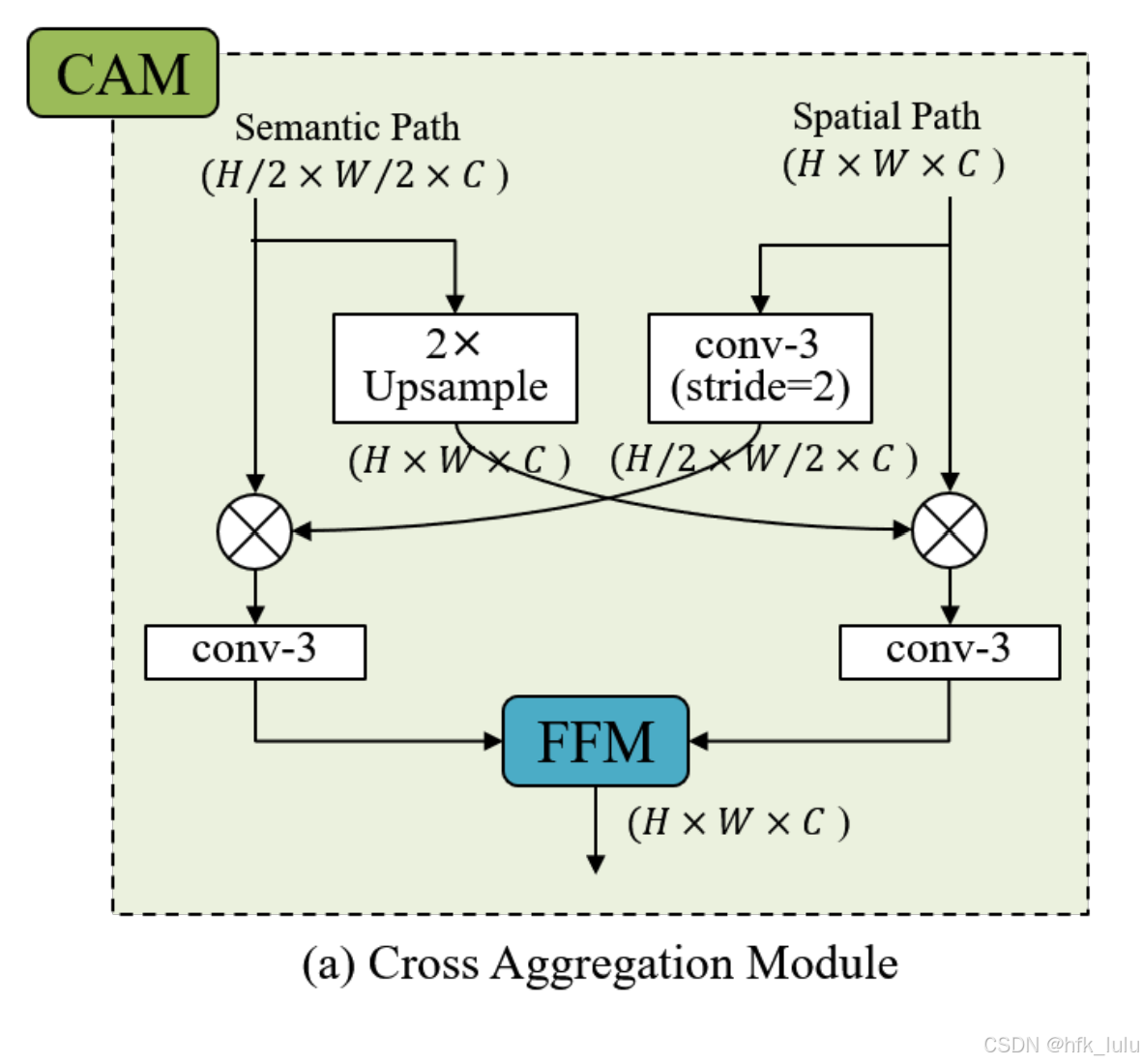
# Spatial Attention Module
class SAM(nn.Module):
def __init__(self, in_chan, out_chan):
super(SAM, self).__init__()
self.conv_atten = conv3x3(2, 1)
self.conv = conv3x3(in_chan, out_chan)
self.bn = nn.BatchNorm2d(out_chan)
def forward(self, x):
avg_out = torch.mean(x, dim=1, keepdim=True)
max_out, _ = torch.max(x, dim=1, keepdim=True)
atten = torch.cat([avg_out, max_out], dim=1)
atten = torch.sigmoid(self.conv_atten(atten))
out = torch.mul(x, atten)
out = F.relu(self.bn(self.conv(out)), inplace=True)
return out
def initialize(self):
weight_init(self)# Cross Aggregation Module
class CAM(nn.Module):
def __init__(self, channel):
super(CAM, self).__init__()
self.down = nn.Sequential(
conv3x3(channel, channel, stride=2),
nn.BatchNorm2d(channel)
)
self.conv_1 = conv3x3(channel, channel)
self.bn_1 = nn.BatchNorm2d(channel)
self.conv_2 = conv3x3(channel, channel)
self.bn_2 = nn.BatchNorm2d(channel)
self.mul = FFM(channel)
def forward(self, x_high, x_low):
left_1 = x_low
left_2 = F.relu(self.down(x_low), inplace=True)
right_1 = F.interpolate(x_high, size=x_low.size()[2:], mode='bilinear', align_corners=True)
right_2 = x_high
left = F.relu(self.bn_1(self.conv_1(left_1 * right_1)), inplace=True)
right = F.relu(self.bn_2(self.conv_2(left_2 * right_2)), inplace=True)
# left = F.relu(left_1 * right_1, inplace=True)
# right = F.relu(left_2 * right_2, inplace=True)
right = F.interpolate(right, size=x_low.size()[2:], mode='bilinear', align_corners=True)
out = self.mul(left, right)
return out
def initialize(self):
weight_init(self)Boundary Path
最终"finer"阶段:底层局部特征+高层位置特征(额外的边界监督),获得显著目标的清晰边界。
- 下采样4倍的特征:更好的边界信息,但也存在非显著目标边界的噪声干扰
- 引入高层特征:高层语义的定位信息作为指导,增强显著目标边界,抑制非显著目标边界
![]()
- BRM的融合策略:上采样Dp12至Dp3的分辨率并相加,全局池化+conv1x1+sigmoid获得通道注意力来reweight相加后的特征,融合(相加)并增强(两层卷积)相加后与reweight后的特征
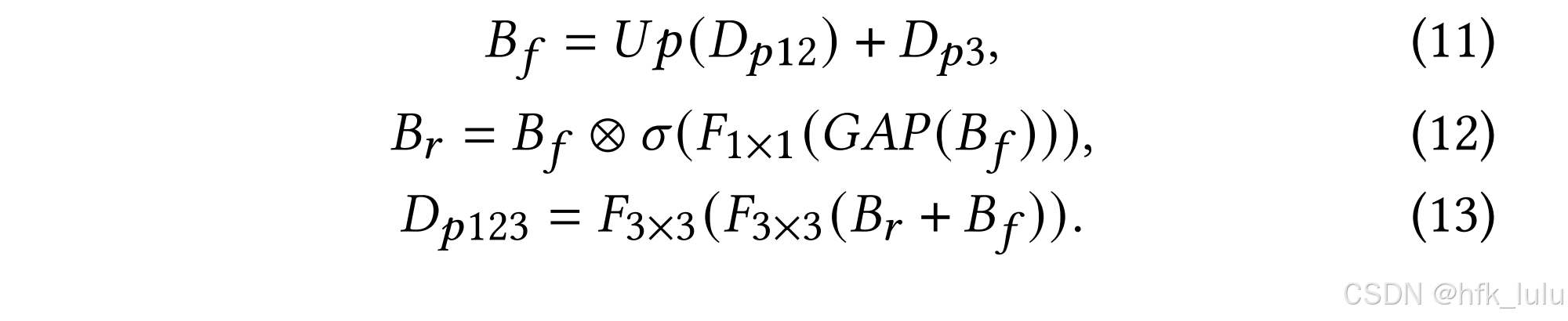
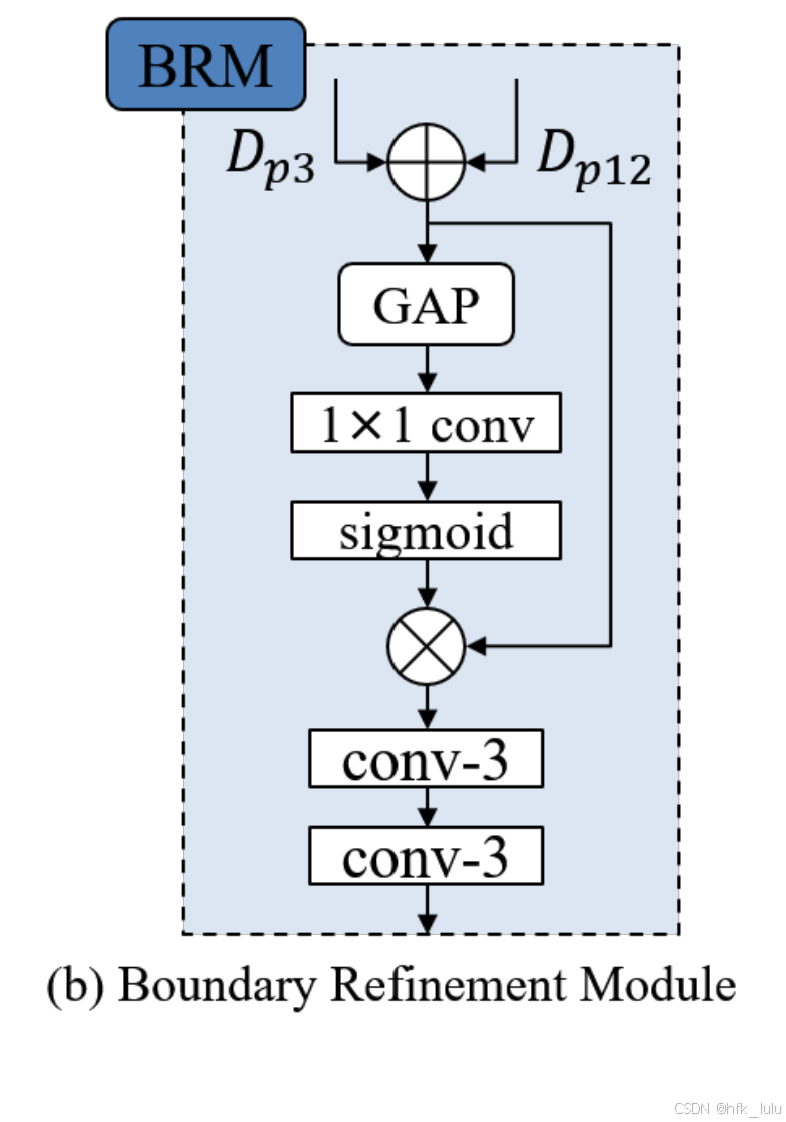
# Boundary Refinement Module
class BRM(nn.Module):
def __init__(self, channel):
super(BRM, self).__init__()
self.conv_atten = conv1x1(channel, channel)
self.conv_1 = conv3x3(channel, channel)
self.bn_1 = nn.BatchNorm2d(channel)
self.conv_2 = conv3x3(channel, channel)
self.bn_2 = nn.BatchNorm2d(channel)
def forward(self, x_1, x_edge):
# x = torch.cat([x_1, x_edge], dim=1)
x = x_1 + x_edge
atten = F.avg_pool2d(x, x.size()[2:])
atten = torch.sigmoid(self.conv_atten(atten))
out = torch.mul(x, atten) + x
out = F.relu(self.bn_1(self.conv_1(out)), inplace=True)
out = F.relu(self.bn_2(self.conv_2(out)), inplace=True)
return out
def initialize(self):
weight_init(self)
CTDNet整体模型定义:
class CTDNet(nn.Module):
def __init__(self, cfg):
super(CTDNet, self).__init__()
self.cfg = cfg
block = BasicBlock
self.bkbone = ResNet(block, [2, 2, 2, 2])
self.path1_1 = nn.Sequential(
conv1x1(512 * block.expansion, 64),
nn.BatchNorm2d(64)
)
self.path1_2 = nn.Sequential(
conv1x1(512 * block.expansion, 64),
nn.BatchNorm2d(64)
)
self.path1_3 = nn.Sequential(
conv1x1(256 * block.expansion, 64),
nn.BatchNorm2d(64)
)
self.path2 = SAM(128 * block.expansion, 64)
self.path3 = nn.Sequential(
conv1x1(64 * block.expansion, 64),
nn.BatchNorm2d(64)
)
self.fuse1_1 = FFM(64)
self.fuse1_2 = FFM(64)
self.fuse12 = CAM(64)
self.fuse3 = FFM(64)
self.fuse23 = BRM(64)
self.head_1 = conv3x3(64, 1, bias=True)
self.head_2 = conv3x3(64, 1, bias=True)
self.head_3 = conv3x3(64, 1, bias=True)
self.head_4 = conv3x3(64, 1, bias=True)
self.head_5 = conv3x3(64, 1, bias=True)
self.head_edge = conv3x3(64, 1, bias=True)
self.initialize()
def forward(self, x, shape=None):
shape = x.size()[2:] if shape is None else shape
l1, l2, l3, l4, l5 = self.bkbone(x)
# 公式(1): Up(GAP(E5))
path1_1 = F.avg_pool2d(l5, l5.size()[2:])
path1_1 = self.path1_1(path1_1)
path1_1 = F.interpolate(path1_1, size=l5.size()[2:], mode='bilinear', align_corners=True) # 1/32
# 公式(1): F1x1(E5)
path1_2 = F.relu(self.path1_2(l5), inplace=True) # 1/32
# 公式(1): FFM1
path1_2 = self.fuse1_1(path1_1, path1_2) # 1/32
# 公式(1): Up(FFM1)
path1_2 = F.interpolate(path1_2, size=l4.size()[2:], mode='bilinear', align_corners=True) # 1/16
# 公式(1): F1x1(E4)
path1_3 = F.relu(self.path1_3(l4), inplace=True) # 1/16
# 公式(1): FFM2
path1 = self.fuse1_2(path1_2, path1_3) # 1/16
# path1 = F.interpolate(path1, size=l3.size()[2:], mode='bilinear', align_corners=True)
path2 = self.path2(l3) # 1/8
path12 = self.fuse12(path1, path2) # 1/8
path12 = F.interpolate(path12, size=l2.size()[2:], mode='bilinear', align_corners=True) # 1/4
path3_1 = F.relu(self.path3(l2), inplace=True) # 1/4
path3_2 = F.interpolate(path1_2, size=l2.size()[2:], mode='bilinear', align_corners=True) # 1/4
path3 = self.fuse3(path3_1, path3_2) # 1/4
path_out = self.fuse23(path12, path3) # 1/4
logits_1 = F.interpolate(self.head_1(path_out), size=shape, mode='bilinear', align_corners=True)
logits_edge = F.interpolate(self.head_edge(path3), size=shape, mode='bilinear', align_corners=True)
if self.cfg.mode == 'train':
logits_2 = F.interpolate(self.head_2(path12), size=shape, mode='bilinear', align_corners=True)
logits_3 = F.interpolate(self.head_3(path1), size=shape, mode='bilinear', align_corners=True)
logits_4 = F.interpolate(self.head_4(path1_2), size=shape, mode='bilinear', align_corners=True)
logits_5 = F.interpolate(self.head_5(path1_1), size=shape, mode='bilinear', align_corners=True)
return logits_1, logits_edge, logits_2, logits_3, logits_4, logits_5
else:
return logits_1, logits_edge
def initialize(self):
if self.cfg.snapshot:
self.load_state_dict(torch.load(self.cfg.snapshot))
else:
weight_init(self)Loss
SOD任务通常使用BCE loss(模型预测mask和ground-truth的逐像素误差)或IoU loss(结构相似度而非单个像素):
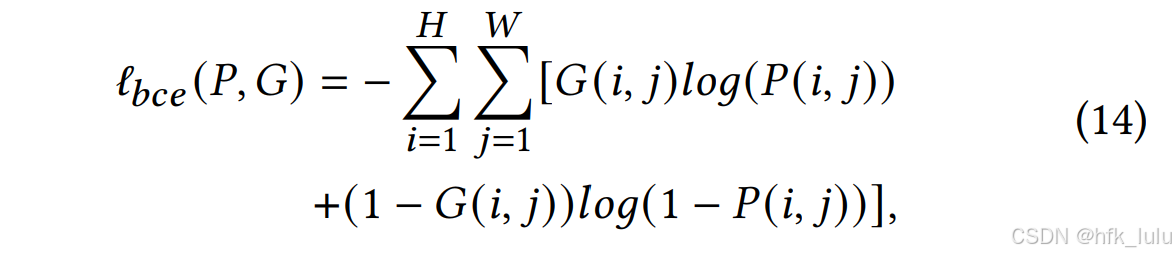
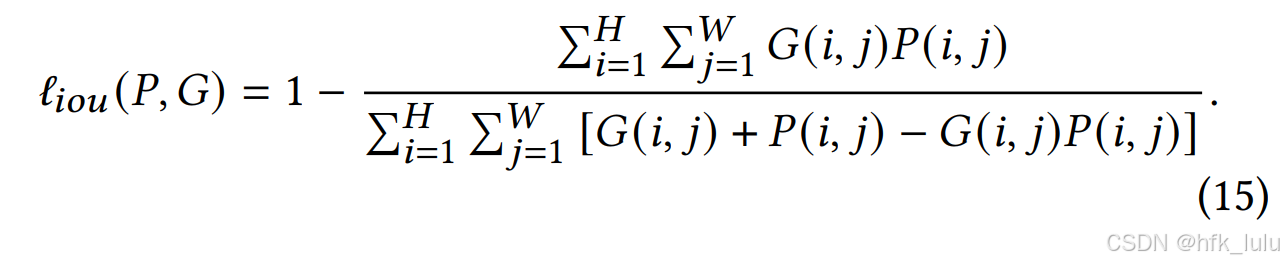
模型共输出六个mask,其中Dp3仅使用BCE loss,其余Dp123/Dp12/Dp1/Eg5/E6均使用IoU loss + 0.6*BCE loss
![]()
def total_loss(pred, mask):
pred = torch.sigmoid(pred)
bce_loss = nn.BCELoss()
bce = bce_loss(pred, mask)
inter = (pred * mask).sum(dim=(2, 3))
union = (pred + mask).sum(dim=(2, 3))
iou = 1 - (inter+1)/(union-inter+1)
iou = iou.mean()
return iou + 0.6*bce out1, out_edge, out2, out3, out4, out5 = net(image)
loss1 = total_loss(out1, mask)
loss_edge = bce_loss(out_edge, edge)
loss2 = total_loss(out2, mask)
loss3 = total_loss(out3, mask)
loss4 = total_loss(out4, mask)
loss5 = total_loss(out5, mask)
loss = loss1 + loss_edge + loss2/2 + loss3/4 + loss4/8 + loss5/16⚗️Experiment Keypoints
- “coarse-fine-finer”三个阶段的可视化

- Dataset:
ECSSD (1,000) PASCAL-S (850) DUTS (15,552) HKU-IS (4,447) DUT-OMRON (5,168) - Metrics:Mean Absolute Error (MAE)-像素级平均绝对误差, F-measure-准确+召回 and E-measure-结构相似度
- 数据前处理:训练阶段resize-352×352 with 随机剪裁+随机水平翻转,推理阶段直接resize
- 优化器:SGD with momentum of 0.9 + weight decay of 5e-4
- batch size 32 + epoch 40 (1080Ti)
- 其他训练策略:warm-up + linear decay学习率 with lr最大值 5e-3 for 预训练 backbone and 5e-2 for 其他网络
# enc_params为backbone网络,dec_params为其他网络
optimizer = torch.optim.SGD([{'params': enc_params}, {'params': dec_params}], lr=cfg.lr, momentum=cfg.momen, weight_decay=cfg.decay, nesterov=True)
for epoch in range(cfg.epoch):
# 学习率的linear decay
optimizer.param_groups[0]['lr'] = (1-abs((epoch+1)/(cfg.epoch+1)*2-1))*cfg.lr*0.1
optimizer.param_groups[1]['lr'] = (1-abs((epoch+1)/(cfg.epoch+1)*2-1))*cfg.lr📖Background Knowledge
- 下采样n倍 = 原图分辨率的1/n
- 底层 = 浅层(Stage-小),高层 = 深层(Stage-大)
- 视觉注意力机制:通道注意力(CAM)、空间注意力(SAM)、混合注意力(CBAM)、自注意力(ASPP)
- U-shape structure (e.g. FCN, SegNet, Unet)
- salient object detection (SOD)
- EGNet: a strong backbone (e.g., ResNet-50 or ResNet-101) + a complicated decode
paper:[1908.08297] EGNet:Edge Guidance Network for Salient Object Detection (arxiv.org)
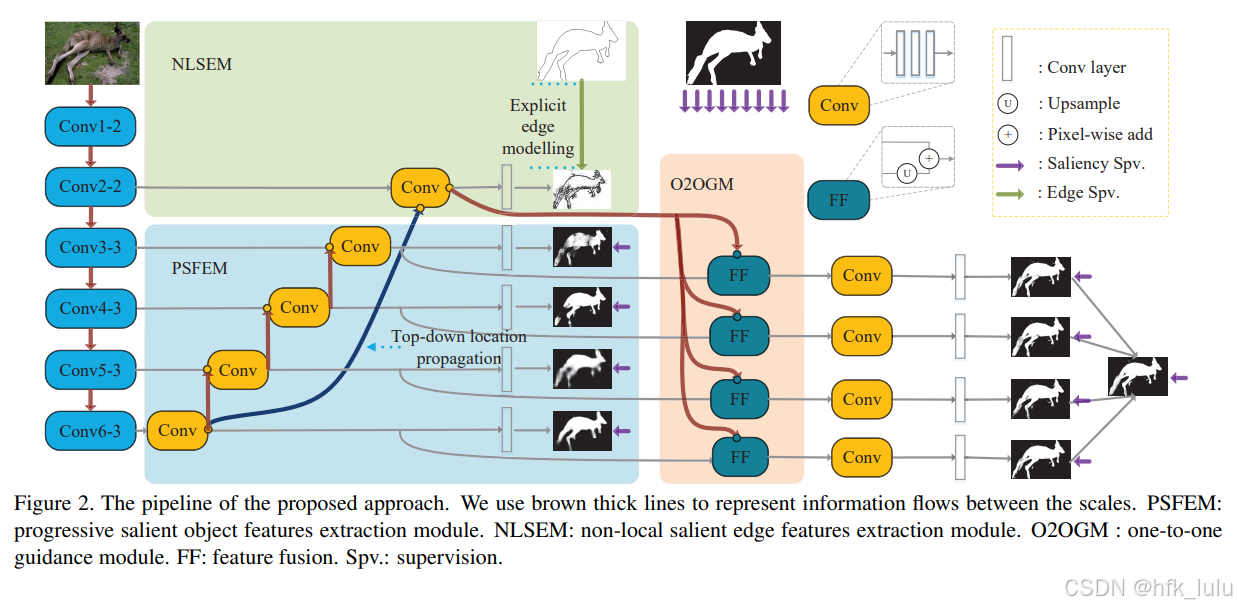
- U-shape: Pi-CANet, TDBU, ASNet, MINet, DASNet, PFSNet
- efficient: PoolNet, CPD, ITSDNet
- 改进U-shape边界不准问题 (introducing an additional boundary-aware branch or a boundary-aware loss function): C2SNet, BASNet, EGNet, BANet, PAGE, AFNet, SCRN
- 思路相似:BiSeNet系列,PIDNet (CVPR'2023)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









