




目录标题
KingbaseES + repmgr 运维笔记(cluster show 解读 & 连接串参数)
适用:KingbaseES/PG 架构,使用
repmgr做主从复制与故障切换;需要看懂repmgr cluster show、快速校验健康度,并合理设置连接串的 keepalive 与tcp_user_timeout等参数。
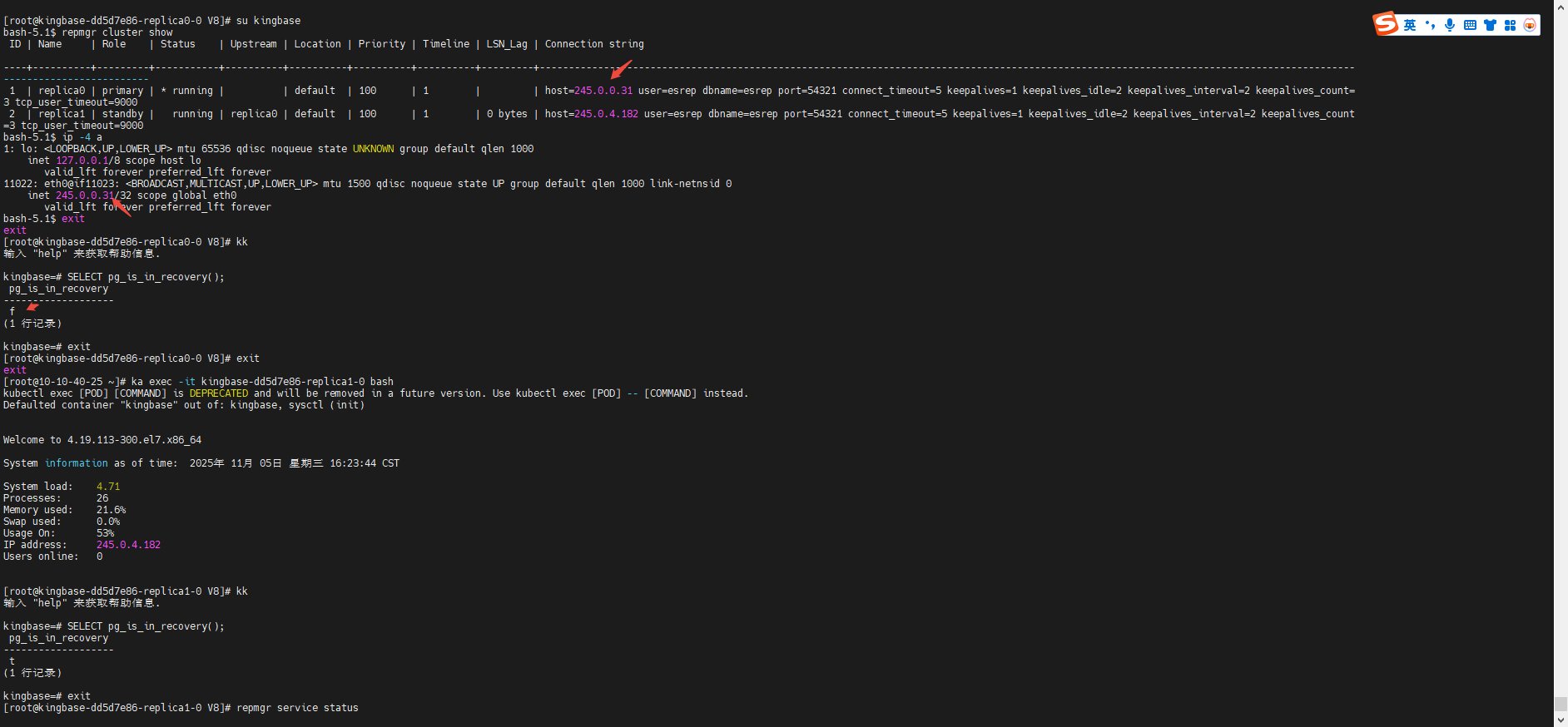
1) 一眼读懂 repmgr cluster show
-
Role / Status / Upstream
Role为 期望角色(来自 repmgr 元数据);Status表示从执行命令的这台机器去连接该节点是否可达(常见值:running/unreachable);- 若实际角色与元数据不符(例如某个 standby 被手动提升),行内会有**
!** 警示;若连不通会显示**?**。(repmgr.org)
-
Location / Priority
Location是逻辑分区标签,常用于跨机房策略;Priority影响自动故障切换的选主优先级:数值越大越优先,设为0可禁止被提升(常用于延迟备或只读副本)。(repmgr.org)
-
LSN_Lag(复制延迟)
- 以 字节差展示主从 WAL 位置差;在库内可用
pg_wal_lsn_diff()复核。(PostgreSQL)
- 以 字节差展示主从 WAL 位置差;在库内可用
-
Timeline(时间线)
- 标识 WAL 历史分支;每次 PITR 完成或副本提升通常进入新时间线。(PostgreSQL)
常用排查命令
-
查看连通失败的具体报错:
repmgr cluster show --verbose(逐节点显示失败原因,定位权限/网络/版本不匹配等问题。) (repmgr.org)
-
守护进程状态(是否启用自动切换):
repmgr service status
(汇总各节点
repmgrd运行状态。) (repmgr.org) -
全矩阵连通性/跨节点互查:
repmgr cluster matrix repmgr cluster crosscheckmatrix在每台节点上执行cluster show汇总;crosscheck进一步交叉验证“从任意节点看其余节点”的可达性。(repmgr.org)
SQL 复核复制延迟(主库执行)
SELECT application_name,
pg_wal_lsn_diff(sent_lsn, replay_lsn) AS bytes_lag
FROM pg_stat_replication;
(pg_wal_lsn_diff() 用于计算 LSN 的字节差。)(PostgreSQL)
2) 连接串关键参数(KingbaseES KCI / libkci)
KingbaseES KCI 文档与 PostgreSQL libpq 语义基本一致,以下为官方定义要点与运维含义。
connect_timeout=5
单个目标主机的建连最大等待秒数;多主机时按主机逐个计时。数值过小易误判宕机,过大则切换变慢。(help.kingbase.com.cn)keepalives=1
是否启用客户端 TCP 保活;1开启(默认)。Unix 域套接字忽略。(help.kingbase.com.cn)keepalives_idle=2
连接空闲多少秒后发送第一个保活探测;0表示使用系统默认。(help.kingbase.com.cn)keepalives_interval=2
保活探测未获确认时,两次探测之间的重发间隔秒数;0用系统默认。(help.kingbase.com.cn)keepalives_count=3
在判定连接失效前,允许连续丢失的保活探测次数;0用系统默认。(help.kingbase.com.cn)- (三者合并的“判死”经验值)
典型触发时间 ≈idle + interval × count。例如你给的值约 2 + 2×3 = 8 秒(仍受内核/调度影响)。 tcp_user_timeout=9000(毫秒)
当已发送的数据长时间未获 ACK 时,最多允许的毫秒数,超时由内核强制关闭连接;0用系统默认;仅在支持TCP_USER_TIMEOUT的系统生效。(help.kingbase.com.cn)
注:上述参数为每连接生效,会覆盖 OS 的系统默认 keepalive 取值(只限该 socket)。
3) 这些设置对高可用/复制稳定性的影响
- 更快的故障感知:激进的
keepalives_*+tcp_user_timeout让“黑洞/半开”连接在 ~8–10s 内失败 → 上层(repmgr/连接池)更快重连或切换。(PostgreSQL) - 误判风险:在 跨城/WAN/VPN/NAT/LB 等易抖环境,过于激进的探测可能把短暂拥塞误判为断链,导致频繁重连/触发切换。
- OS 默认值参考(若未显式设置三元组,通常沿用内核默认):
Linux 常见默认:tcp_keepalive_time=7200s、tcp_keepalive_intvl=75s、tcp_keepalive_probes=9(非常保守)。(Linux 文档项目)
4) 场景化推荐“挡位”(起步值,可按抖动程度微调)
目标是在足够快地探测故障与避免误判之间取平衡;并保证周期不大于云厂商/NAT/LB 的空闲清理阈值。
- 同城/专线 LAN(低抖动)
connect_timeout=3~5;keepalives_idle=10、interval=2~3、count=3(约 16–19s);tcp_user_timeout=10~15s。 - 跨机房/城际链路(中等抖动)
connect_timeout=5~8;idle=15~30、interval=5、count=3~4(约 30–50s);tcp_user_timeout=30~45s。 - 云上/NAT/LB/VPN(抖动与空闲回收较明显)
connect_timeout=5~10;idle=20~30、interval=5~10、count=4~6(约 40–90s);tcp_user_timeout=60~90s。
(OS 默认值与参数语义见上文 KCI/libpq 与 Linux 文档。)(help.kingbase.com.cn)
5) 日常健康检查与排错清单
-
repmgr 基础
repmgr cluster show --verbose:列出不可达节点的具体错误。(repmgr.org)repmgr service status:确认所有节点repmgrd是否运行。(repmgr.org)repmgr cluster matrix/cluster crosscheck:全矩阵连通性与交叉验证。(repmgr.org)
-
复制延迟核对(主库)
SELECT application_name, pg_wal_lsn_diff(sent_lsn, replay_lsn) AS bytes_lag FROM pg_stat_replication;(也可结合
pg_current_wal_lsn()/pg_last_wal_replay_lsn()自行计算。)(PostgreSQL) -
OS 层确认 keepalive 默认
sysctl net.ipv4.tcp_keepalive_time \ net.ipv4.tcp_keepalive_intvl \ net.ipv4.tcp_keepalive_probes(验证是否被应用/安全组/LB 改写。)(Linux 文档项目)
6) 关键概念补充
- WAL 与 Timeline
PostgreSQL/Kingbase 通过 WAL 确保崩溃一致性;PITR 完成或副本提升后会生成新时间线,防止覆盖历史段文件。(PostgreSQL) - 连接串语法来源
KingbaseES KCI 手册明确支持关键字=值与 URI 两种连接串格式,并列出了参数关键词及含义(包含keepalives_*、tcp_user_timeout等)。(help.kingbase.com.cn)
速查卡(Copy 即用)
# 1) 读拓扑/查失败原因
repmgr cluster show --verbose
# 2) 守护进程状态(是否启用自动切换)
repmgr service status
# 3) 全矩阵连通性(含交叉验证)
repmgr cluster matrix
repmgr cluster crosscheck

-- 主库:按字节差查看复制延迟
SELECT application_name,
pg_wal_lsn_diff(sent_lsn, replay_lsn) AS bytes_lag
FROM pg_stat_replication;
# 连接串(示例,LAN 激进探测;可按上表“挡位”替换)
host=245.0.0.164 port=54321 dbname=esrep user=esrep \
connect_timeout=5 keepalives=1 keepalives_idle=10 keepalives_interval=3 keepalives_count=3 \
tcp_user_timeout=10000
如果你告诉我网络类型(同城/跨城/云上)、是否经过 NAT/LB/VPN,以及期望的切换目标时间(比如 ≤10s/≤30s/≤60s),我可以把上面的“挡位”收敛为你的专用参数模板,并附上 OS sysctl 与 repmgr.conf 的配套清单。
Connection string
下面这列指的就是 repmgr 为每个节点登记在案的 “数据库连接串(conninfo)”。它是标准 libpq/KCI 的 keyword=value 串,repmgr 用它去“拨号”该节点做探活、读取元数据、执行切换/重加⼊等动作;所以它既是展示信息,更是 repmgr 实际连到该节点所依赖的配置。(repmgr.org)
它从哪儿来 & 被谁用
-
来源:你在每台机器的
repmgr.conf里配置的conninfo;注册节点时会写入repmgr.nodes表,后续命令直接使用这份字符串。(repmgr.org) -
用途:
cluster show用它轮询各节点并给出 “running/unreachable”等状态;--verbose可显示具体错误。(repmgr.org)- 恢复/回表时(如
repmgr node rejoin、standby follow),你要把当前主库的 conninfo 传给它,repmgr 才能拉到最新拓扑并把节点接回集群。(repmgr.org)
串里这些键值“各做什么”(与你输出对应)
你看到的 host/user/dbname/port 是基础定位;后面那串 connect_timeout/keepalives_* / tcp_user_timeout 是 libpq 客户端 TCP 行为调优项:
connect_timeout: 单目标建连最长等待秒数(多 host 时逐个计时)。(PostgreSQL)keepalives=1,keepalives_idle,keepalives_interval,keepalives_count: 打开并细化客户端 TCP keepalive 探测,缩短“半开/黑洞”连接的感知时间。(CYBERTEC PostgreSQL | Services & Support)tcp_user_timeout: 已发送但未获 ACK 的数据最多可滞留多久(毫秒),超时由内核强制断开,配合 keepalive 实现更快失败检测。(Postgres Professional)
正确性与安全小检查(很重要)
- 互联性:repmgr 明确要求“所有服务器都必须能用这条 conninfo 连接到该节点本机”。若你把
host写成仅局部可达的地址(如容器内网 IP),跨节点探测就可能失败。(repmgr.org) - 不要把密码写进 conninfo:否则它会原样出现在
repmgr.conf、repmgr.nodes表、cluster show输出和日志里。用.pgpass/凭据管理替代。(repmgr.org)
结合你这次的输出再提醒两点
-
LSN_Lag=960 kB说明副本已落后一些;且 Timeline=5(副本) / 6(主库) 通常意味着刚经历过提升/切换,副本还在追。 -
但你在
replica0上执行SELECT pg_is_in_recovery();得到f,而cluster show却把它标成 standby——这就是角色与元数据不一致或连接到了错误实例(例如连到主库的服务地址)。建议:-- 在两台机器分别执行,核对到底连的是谁 SELECT inet_server_addr(), inet_server_port(), pg_is_in_recovery(), current_setting('primary_conninfo', true);如确认角色确实不符,用
repmgr standby follow(未分叉时)或repmgr node rejoin -d '<主库conninfo>'让副本重新跟随/回表,并在必要时重新register --force纠正元数据。(repmgr.org)
小结:“Connection string” 列就是 repmgr 存档并实际使用的节点 conninfo。把它配成“所有节点互通、无明文密码、地址稳定”的形式,repmgr 的探测与切换才会可靠;串内的 keepalive/
tcp_user_timeout则决定了你想要多“快刀斩乱麻”地感知网络故障。(repmgr.org)

















 572
572

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









