




目录标题
ClickHouse 集群高可用架构分析
一、集群架构概览
1.1 整体规模
- 存储层:6 个 Shard × 2 个 Replica = 12 个 ClickHouse 节点
- 协调层:3 个 ZooKeeper 节点 (v3.7.1)
- 物理节点:4 台服务器 (qfusion1-4)
1.2 集群拓扑结构
ClickHouse 分片副本分布
| Shard | Replica 0 | Replica 1 | 说明 |
|---|---|---|---|
| Shard0 | qfusion1 (replica0-0-0) | qfusion3 (replica0-1-0) | 跨节点部署 |
| Shard1 | qfusion2 (replica1-0-0) | qfusion4 (replica1-1-0) | 跨节点部署 |
| Shard2 | qfusion2 (replica2-0-0) | qfusion4 (replica2-1-0) | 跨节点部署 |
| Shard3 | qfusion3 (replica3-0-0) | qfusion1 (replica3-1-0) | 跨节点部署 |
| Shard4 | qfusion2 (replica4-0-0) | qfusion4 (replica4-1-0) | 跨节点部署 |
| Shard5 | qfusion3 (replica5-0-0) | qfusion2 (replica5-1-0) | 跨节点部署 |
ZooKeeper 节点分布
| ZK 节点 | 物理位置 | 角色 |
|---|---|---|
| zk-0 | qfusion2 | Follower/Leader |
| zk-1 | qfusion4 | Follower/Leader |
| zk-2 | qfusion1 | Follower/Leader |
1.3 架构特点
- 分片策略:数据水平分片,分散到 6 个 Shard
- 副本策略:每个 Shard 配置 2 个副本,实现数据冗余
- 反亲和部署:同一 Shard 的副本分布在不同物理节点
- 元数据管理:ZooKeeper 负责协调副本同步、分布式 DDL、故障转移
二、高可用机制详解
2.1 ZooKeeper 层高可用
工作原理
- Quorum 机制:3 节点集群,需要 ≥2 个节点存活才能正常工作
- Leader 选举:自动选举 Leader,处理写请求
- 数据一致性:通过 ZAB 协议保证元数据强一致性
故障容忍
| 故障场景 | 影响 | 恢复机制 |
|---|---|---|
| 1 个 ZK 节点故障 | ✅ 无影响,2/3 仍有 Quorum | 自动重新选举(如需要) |
| 2 个 ZK 节点故障 | ❌ 失去 Quorum,集群不可用 | 需手动恢复至少 1 个节点 |
2.2 ClickHouse 层高可用
副本同步机制
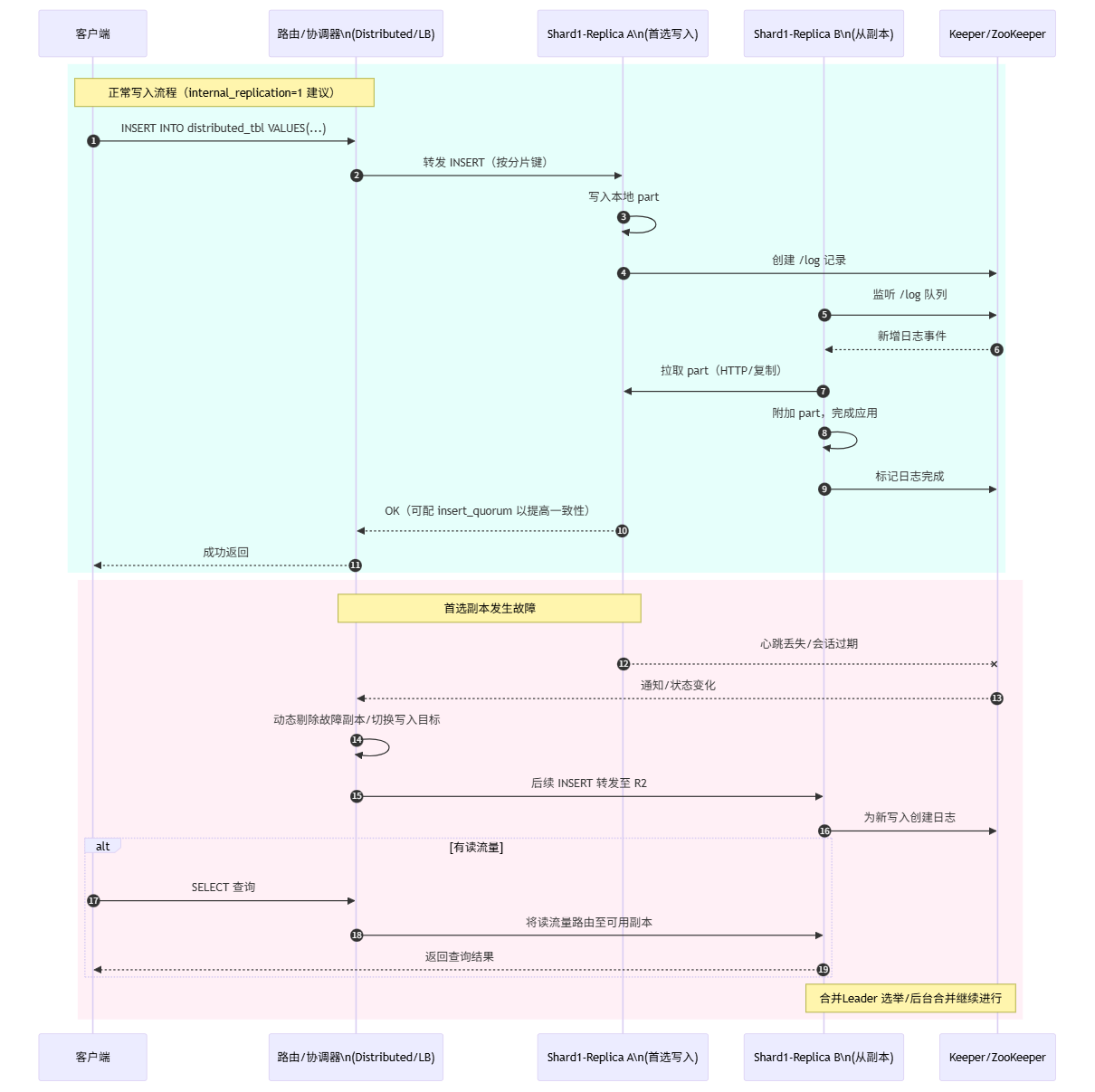
写入流程:
Client → 任意副本 → ZooKeeper 协调 → 其他副本拉取数据
↓
本地写入 WAL
↓
通知 ZK 完成
查询路由机制
- 健康检查:定期检测副本存活状态
- 负载均衡:查询自动路由到健康副本
- 故障转移:故障副本自动从查询池中剔除
故障场景分析
| 故障类型 | 影响程度 | 系统行为 | 业务感知 |
|---|---|---|---|
| 单副本故障 | 低 | 查询路由到健康副本 | 无感知 |
| 整个 Shard 故障 | 高 | 该分片数据不可用 | 查询报错 |
| 多副本不同步 | 中 | 读取可能不一致 | 数据延迟 |
2.3 数据一致性保证
ReplicatedMergeTree 引擎
- 写入保证:至少一个副本写入成功即返回
- 复制机制:异步复制,通过 ZooKeeper 协调
- 数据恢复:故障副本恢复后自动追赶数据
一致性级别
- 最终一致性:默认模式,副本间异步同步
- 读己之写:通过
insert_quorum参数控制 - 强一致读:通过
select_sequential_consistency参数控制
三、物理节点故障影响分析
3.1 单节点故障场景模拟
场景一:qfusion1 节点故障
影响组件:
- ZooKeeper:zk-2 不可用(剩余 2/3,仍有 Quorum)
- ClickHouse:
- Shard0 的 replica0-0-0 不可用(replica0-1-0 在 qfusion3 正常)
- Shard3 的 replica3-1-0 不可用(replica3-0-0 在 qfusion3 正常)
业务影响:✅ 无影响,所有 Shard 至少有一个副本可用
场景二:qfusion2 节点故障
影响组件:
- ZooKeeper:zk-0 不可用(剩余 2/3,仍有 Quorum)
- ClickHouse:
- Shard1 的 replica1-0-0 不可用
- Shard2 的 replica2-0-0 不可用
- Shard4 的 replica4-0-0 不可用
- Shard5 的 replica5-1-0 不可用
业务影响:✅ 无影响,所有受影响 Shard 在其他节点有健康副本
3.2 故障恢复流程
自动恢复(Kubernetes 环境)
本地存储,POD不会重启调度到其他节点。
恢复时间预估
| 阶段 | 时间 | 说明 |
|---|---|---|
| 故障检测 | 10-30s | K8s 健康检查周期 |
| Pod 重调度 | 1-5min | 取决于镜像拉取和启动时间 |
| 数据同步 | 变量 | 取决于故障期间的数据增量 |
四、高可用保障建议
4.1 部署层优化
Pod 反亲和性配置
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: shard
operator: In
values: ["shard-x"]
topologyKey: kubernetes.io/hostname
PodDisruptionBudget 设置
apiVersion: policy/v1
kind: PodDisruptionBudget
metadata:
name: clickhouse-pdb
spec:
minAvailable: 1 # 每个 Shard 至少保留 1 个副本
selector:
matchLabels:
app: clickhouse
4.2 监控告警体系
关键监控指标
| 指标类型 | 具体指标 | 告警阈值 |
|---|---|---|
| 可用性 | 副本存活数 | < 2 per shard |
| 性能 | 复制延迟 | > 60s |
| 资源 | 磁盘使用率 | > 85% |
| 一致性 | ZK 连接状态 | 断开 > 30s |
告警响应流程
- P0 级别:整个 Shard 不可用 → 立即响应
- P1 级别:单副本故障 → 30 分钟内响应
- P2 级别:性能降级 → 2 小时内响应
4.3 容灾演练建议
定期演练项目
- 单节点故障切换测试(月度)
- ZooKeeper Leader 切换测试(季度)
- 数据恢复速度测试(季度)
- 全量备份恢复测试(半年)
演练检查清单
# 演练前检查
kubectl get pods -n qfusion-admin -o wide | grep clickhouse
kubectl get pods -n qfusion-admin | grep zk
# 模拟节点故障
kubectl cordon <node-name>
kubectl drain <node-name> --ignore-daemonsets
# 验证高可用
# 1. 检查 ZK 集群状态
kubectl exec -n qfusion-admin zk-0 -- zkServer.sh status
# 2. 检查 ClickHouse 查询
kubectl exec -n qfusion-admin <ch-pod> -- clickhouse-client \
--query "SELECT * FROM system.replicas WHERE is_readonly=1"
# 3. 验证数据写入
kubectl exec -n qfusion-admin <ch-pod> -- clickhouse-client \
--query "INSERT INTO test_table VALUES (...)"
# 恢复节点
kubectl uncordon <node-name>
五、风险评估与应对
5.1 风险矩阵
| 风险等级 | 场景 | 概率 | 影响 | 应对措施 |
|---|---|---|---|---|
| 🔴 高 | 同一 Shard 两副本同时故障 | 低 | 数据不可用 | 强制反亲和部署 |
| 🔴 高 | ZooKeeper 失去 Quorum | 低 | 集群瘫痪 | 增加 ZK 节点到 5 个 |
| 🟡 中 | 单节点故障 | 中 | 性能降级 | 自动故障转移 |
| 🟢 低 | 网络分区 | 低 | 部分不可用 | 多可用区部署 |
5.2 应急预案
场景一:ZooKeeper 完全不可用
# 1. 临时启用只读模式
SET allow_experimental_live_view = 0;
# 2. 快速恢复 ZK
kubectl delete pod -n qfusion-admin zk-0 zk-1 zk-2
kubectl scale statefulset -n qfusion-admin zk --replicas=0
kubectl scale statefulset -n qfusion-admin zk --replicas=1
# 3. 验证恢复
echo ruok | nc <zk-ip> 2181
场景二:数据不一致处理
-- 检查副本同步状态
SELECT
database,
table,
is_readonly,
total_replicas,
active_replicas,
absolute_delay
FROM system.replicas
WHERE absolute_delay > 60;
-- 强制同步
SYSTEM SYNC REPLICA <table_name>;
-- 修复元数据
SYSTEM RESTORE REPLICA <table_name>;
六、总结
6.1 当前架构优势
✅ 高可用性:单点故障不影响业务
✅ 数据冗余:每个 Shard 双副本保护
✅ 自动恢复:K8s + ZK 实现自动故障转移
✅ 负载均衡:查询自动分散到健康副本
6.2 潜在改进空间
⚠️ 节点数量:4 个物理节点略少,建议扩展到 6 个
⚠️ ZK 节点:可考虑扩展到 5 个提高容错能力
⚠️ 跨机房:当前单机房部署,可考虑跨机房容灾
⚠️ 备份策略:需要定期全量备份 + 增量备份
6.3 核心结论
在当前 6 Shard × 2 Replica + 3 ZooKeeper 的架构下,单个物理节点故障不会导致 ClickHouse 服务中断,系统具备生产级高可用能力。
文档版本:v1.0
更新时间:2025-09-01
适用环境:Kubernetes + ClickHouse Operator
ClickHouse 高可用工作流程图 (带副本切换)

















 786
786

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









