






目录标题
MongoDB与Redis常见问题全解析:从持久化到缓存穿透,从开发到运维
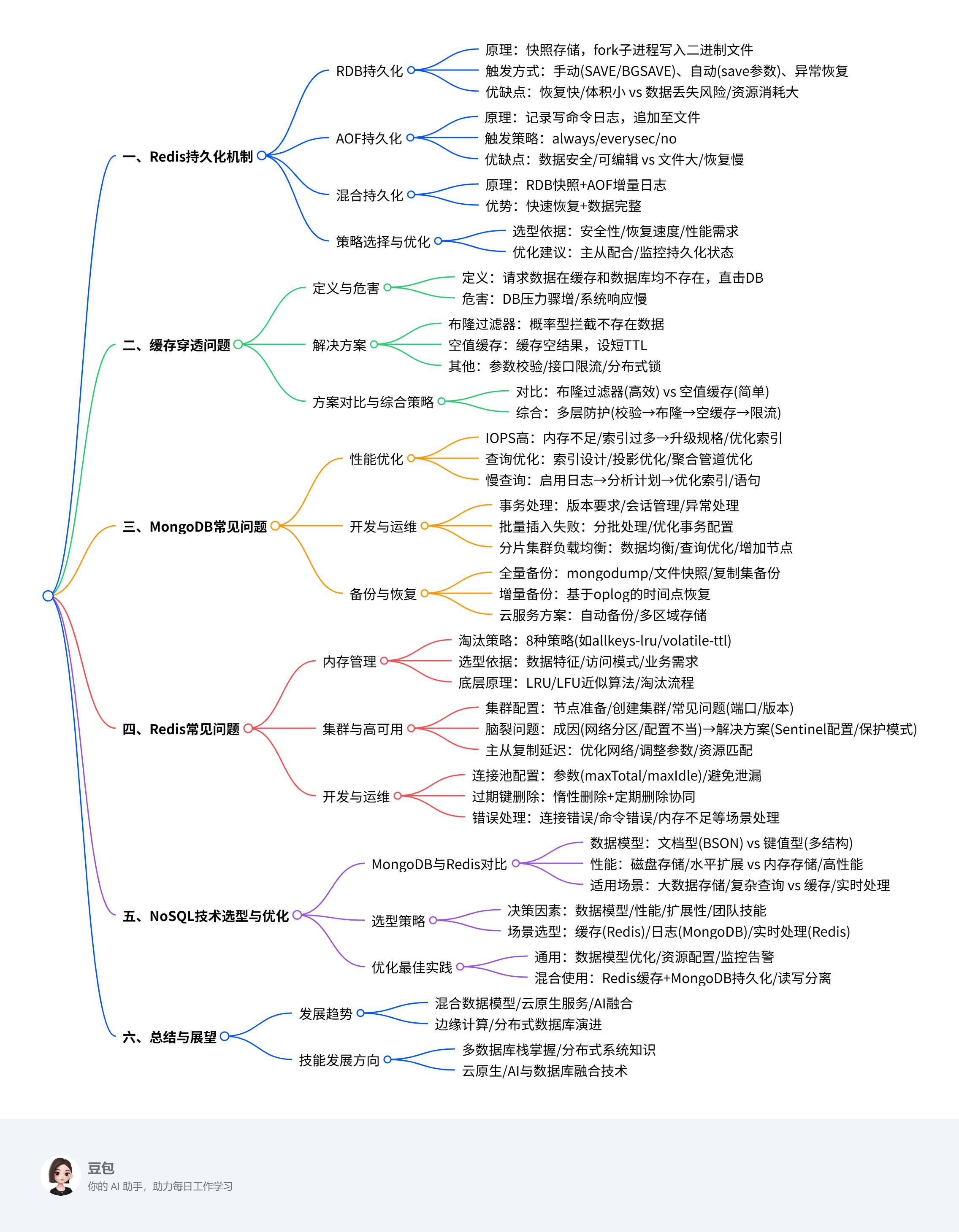
一、Redis持久化机制详解
1.1 RDB(Redis Database Snapshot)持久化
1.1.1 RDB原理与触发方式
RDB是Redis的快照存储机制,即将某一时刻的数据以二进制格式保存到磁盘中。其核心原理是通过fork子进程将内存中的数据写入RDB文件,实现数据的持久化备份。
触发方式主要有三种:
-
手动触发:
SAVE命令:同步阻塞式保存快照,会暂停所有客户端操作直到完成,线上应禁止使用BGSAVE命令:异步非阻塞式保存快照,主进程继续处理客户端请求,子进程负责生成RDB文件
-
自动触发:
- 根据配置文件中的
save参数自动触发,如save 900 1表示900秒内至少有1次写操作时触发保存 - 执行
SHUTDOWN命令关闭Redis时,会自动触发RDB持久化
- 根据配置文件中的
-
异常触发:
- 当Redis实例崩溃或服务器断电时,若开启了RDB持久化,重启时会自动加载最后一次有效的RDB文件
写时复制(COW)机制:在生成RDB文件的过程中,如果主进程对数据进行修改,操作系统会为被修改的数据创建一个副本,子进程写入的是原始数据,主进程则操作新副本,确保数据一致性。
1.1.2 RDB优缺点与适用场景
优点:
- 恢复速度快:RDB文件是二进制格式,加载速度快,适合大规模数据恢复
- 文件体积小:相比AOF文件,RDB文件更小,占用磁盘空间少
- 性能影响小:通过子进程完成持久化,对主进程性能影响较小
缺点:
- 数据丢失风险:如果发生故障时距离上次RDB持久化时间较长,可能丢失大量数据
- 生成过程资源消耗大:生成RDB文件需要fork子进程并占用CPU和内存资源,大数据量时影响性能
适用场景:
- 对数据完整性要求不是极高,但要求快速恢复的场景
- 需要定期备份数据的场景
- 数据量较大但允许一定时间内数据丢失的场景
1.1.3 RDB流程详解
生成流程:
- 触发快照(手动或自动)
- Redis fork一个子进程
- 子进程从内存中读取所有数据并写入临时RDB文件
- 主进程继续处理客户端请求
- 临时RDB文件写入完成后,替换旧的RDB文件
加载流程:
- Redis启动时,优先加载RDB文件(如果存在)
- 解析并加载二进制数据到内存中
- 恢复到快照生成时的状态
1.2 AOF(Append Only File)持久化
1.2.1 AOF原理与触发方式
AOF是Redis的另一种持久化方式,通过将每个写操作以日志形式追加到文件末尾,实现数据的持久化。
触发方式主要由appendfsync参数控制:
appendfsync always:每次写命令都立即同步到磁盘,数据最安全但性能最差appendfsync everysec(默认):每秒同步一次,数据丢失量较小,性能较好appendfsync no:由操作系统决定何时将数据写入磁盘,性能最高但数据丢失风险大
AOF文件结构:
- AOF文件是文本格式,记录了Redis协议格式的写命令
- 例如,执行
SET zhuge 666会在AOF文件中记录为*3 $3 SET $5 zhuge $3 666
1.2.2 AOF优缺点与适用场景
优点:
- 数据安全性高:默认每秒执行一次
fsync操作,最多只丢失1秒数据 - 写入性能高:追加操作直接写入文件尾部,性能较优
- 文本格式,便于编辑和恢复:AOF文件可读性高,便于编辑和恢复,如误执行
flushall后可通过编辑日志文件移除相关命令
缺点:
- 文件体积大:同等数据量下,AOF文件通常比RDB文件更大
- 性能开销较高:每次写命令都需记录,性能开销比RDB大
- 恢复速度慢:由于需要重放所有日志命令,数据恢复耗时较长
适用场景:
- 对数据安全性要求高的场景
- 写操作频繁的场景
- 需要快速恢复且数据完整性要求高的场景
1.2.3 AOF流程详解
写入流程:
- Redis将每个写操作以文本形式追加到AOF文件末尾
- 根据配置的
fsync策略,定期将数据同步到磁盘
重写流程:
- 触发条件:AOF文件大小超过上一次重写时的100%且大于64MB时触发
- Redis fork一个子进程
- 子进程扫描当前内存数据,生成最简化的命令集
- 写入新的AOF文件
- 新文件生成后,替换旧的AOF文件
1.3 混合持久化(Hybrid Persistence)
1.3.1 混合持久化原理与工作机制
混合持久化是Redis 4.0引入的一种持久化机制,结合了RDB和AOF的特性,既保留RDB的高效性,又降低AOF文件大小和启动时间。
工作原理:
- 生成RDB快照:将内存中的数据快照保存到RDB文件
- 追加增量AOF日志:在RDB快照之后,记录从快照生成到持久化完成之间的所有操作日志
混合文件结构:
- 文件前半部分是RDB格式的二进制数据
- 文件后半部分是AOF格式的增量日志
1.3.2 混合持久化优缺点与适用场景
优点:
- 快速恢复:先加载RDB部分,再回放AOF增量日志,恢复速度大幅提升
- 文件体积小:相比纯AOF文件,混合持久化文件更小
- 性能优化:RDB快照通过子进程完成,对主进程性能影响小
缺点:
- 配置复杂性:混合持久化的配置比单独使用RDB或AOF更加复杂
- 磁盘空间占用:混合持久化模式下,AOF文件既包含RDB快照部分又包含增量日志,可能会占用更多的磁盘空间
适用场景:
- 对恢复速度要求高的场景
- 对数据完整性要求高的场景
- 低延迟要求的系统:混合持久化减少了AOF文件的写入,降低了磁盘延迟
1.3.3 混合持久化恢复流程
恢复流程:
-
加载RDB部分:
- 检测到AOF文件开头是RDB格式
- 使用与普通RDB文件相同的逻辑解析和加载二进制数据
- 将快照中的数据完整恢复到内存中
-
回放AOF部分:
- 解析AOF文件的后半部分(增量日志)
- 按顺序逐条执行AOF部分的命令
- 将操作作用于内存数据,更新到最新状态
1.4 Redis持久化策略选择与优化建议
1.4.1 如何选择合适的持久化策略
选择建议:
- 数据安全性要求极高:建议使用AOF持久化或混合持久化
- 恢复速度要求高:建议使用RDB或混合持久化
- 内存占用敏感:建议使用RDB持久化
- 写入性能要求高:建议使用AOF的
appendfsync everysec策略或混合持久化
混合使用策略:
- 可以同时启用RDB和AOF持久化,以满足快速恢复和数据安全的双重需求
- 当同时配置了AOF和RDB持久化时,Redis重启时会优先使用AOF文件恢复数据,因为AOF文件通常更完整
1.4.2 持久化性能优化建议
通用优化建议:
- 控制最大内存:减少
fork时间,避免内存不足导致持久化失败 - 手动触发备份和重写:避免多实例同时进行持久化操作
- 主从配合:主机提供服务,从机用于备份,分摊性能压力
- 监控持久化状态:定期检查持久化日志和监控指标,及时发现问题
AOF优化建议:
- 合理设置AOF重写触发条件:根据业务写入量调整
auto-aof-rewrite-percentage和auto-aof-rewrite-min-size参数 - 避免频繁重写:过大的AOF文件重写会导致性能波动
- 使用AOF重写的后台线程:Redis 4.0引入的AOF重写后台线程避免了AOF重写过程中的性能瓶颈
RDB优化建议:
- 合理设置save参数:根据业务需求调整自动触发RDB的条件
- 监控RDB生成时间:避免在业务高峰期生成RDB文件
- 使用写时复制优化:理解并利用写时复制机制,减少内存使用
二、缓存穿透问题分析与解决方案
2.1 缓存穿透原理与危害
2.1.1 缓存穿透的定义与产生原因
缓存穿透定义:缓存穿透是指客户端请求的数据在缓存中和数据库中都不存在,这样缓存永远不会生效,这些请求都会打到数据库。
产生原因:
- 恶意请求:黑客暴力扫描不存在的ID(如-1、0等非法值),试图压垮数据库
- 业务逻辑缺陷:业务未校验参数有效性,直接透传至数据库
- 数据生命周期管理问题:某些数据被删除后,缓存没有及时更新,导致后续查询穿透
- 缓存空值处理不当:查询数据库返回空值后,未将空值存入缓存,导致每次查询都穿透
2.1.2 缓存穿透的危害与影响
主要危害:
- 数据库压力骤增:高频无效请求直接访问数据库,导致数据库压力过大,甚至崩溃
- 系统响应变慢:数据库处理大量无效请求,影响正常业务请求的处理速度
- 可用性降低:数据库可能因压力过大而无法响应,导致系统不可用
- 资源浪费:处理无效请求浪费服务器CPU、内存等资源
2.2 缓存穿透解决方案分析
2.2.1 布隆过滤器(Bloom Filter)方案
布隆过滤器原理:布隆过滤器是一种概率型数据结构,用于快速判断一个元素是否属于一个集合。它使用多个哈希函数将一个元素映射到位阵列中的多个点,将这些点设置为1。查询时,若所有对应点都是1,则元素可能存在;若有一个点是0,则元素一定不存在。
布隆过滤器实现步骤:
- 数据预热:将所有可能存在的数据ID加载到布隆过滤器中
- 请求拦截:客户端请求时,先通过布隆过滤器判断数据是否存在
- 处理流程:
- 若布隆过滤器返回"一定不存在",直接返回空值或错误信息
- 若返回"可能存在",再查询缓存和数据库
代码示例(Java实现):
// 使用Guava实现布隆过滤器
BloomFilter<Long> bloomFilter = BloomFilter.create(
Funnels.longFunnel(),
1000000, // 预期元素量
0.01 // 误判率
);
// 预热数据
for (long id : validIds) {
bloomFilter.put(id);
}
// 查询拦截
public String getProduct(Long id) {
if (!bloomFilter.mightContain(id)) {
return "非法ID";
}
// 继续查询流程...
}
优点:
- 内存占用少(1百万数据仅需1MB)
- 查询效率高,能在O(1)时间内完成判断
- 有效拦截大量无效请求
缺点:
- 存在误判率(可通过调整参数降低)
- 无法删除元素(存在删除困难)
适用场景:
- 电商商品ID扫描攻击防护
- 社交平台查询已注销用户防护
- 已知数据集合的查询场景
2.2.2 空值缓存方案
空值缓存原理:将查询结果为空的键也存入缓存,设置较短过期时间,避免每次都查询数据库。
实现步骤:
- 查询缓存,若存在空值标记,直接返回
- 若缓存未命中,查询数据库
- 若数据库也不存在该数据,将空值或特殊标记存入缓存,并设置较短TTL
代码示例(Java实现):
public String getProduct(Long id) {
String key = "product:" + id;
String value = redis.get(key);
if ("NULL".equals(value)) {
return "商品不存在"; // 命中空缓存
}
if (value == null) {
value = db.query(id);
if (value == null) {
redis.setex(key, 300, "NULL"); // 空值缓存5分钟
} else {
redis.setex(key, 3600, value);
}
}
return value;
}
优点:
- 实现简单,无需引入额外组件
- 对现有系统侵入性小
- 能有效拦截针对同一不存在数据的高频请求
缺点:
- 可能缓存大量无效Key,浪费内存空间
- 不适用于数据库中数据变化频繁的场景
适用场景:
- 数据存在性相对稳定的场景
- 数据库查询成本较高的场景
- 恶意请求防护
2.2.3 其他解决方案
1. 请求参数校验:
- 在应用层对请求参数进行合法性校验,如ID是否为合法的数值类型、长度是否符合要求等
- 对于明显不合法的请求直接返回错误,无需查询缓存和数据库
2. 接口限流:
- 对高频访问的接口实施限流措施,如使用令牌桶、漏桶算法等
- 限制单位时间内的请求次数,防止恶意攻击
3. 分布式锁:
- 在缓存失效时,通过分布式锁控制仅一个线程重建缓存
- 避免大量并发请求同时查询数据库
4. 动态黑名单:
- 监控请求频率和返回结果,对频繁请求不存在数据的IP或用户ID加入黑名单
- 对黑名单中的请求直接返回错误或限制访问
2.3 缓存穿透解决方案对比与选择
2.3.1 不同解决方案对比分析
| 解决方案 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| 布隆过滤器 | 内存占用少,查询效率高,拦截效果好 | 存在误判率,无法删除元素 | 已知数据集合,高并发场景 |
| 空值缓存 | 实现简单,侵入性小,能拦截重复请求 | 浪费内存空间,不适用于数据变化频繁场景 | 数据相对稳定,数据库查询成本高 |
| 请求参数校验 | 实现简单,资源消耗低 | 仅能拦截明显不合法请求 | 接口参数有明确规范的场景 |
| 接口限流 | 有效防护恶意攻击,实现相对简单 | 可能影响正常用户体验 | 高并发且存在安全风险的场景 |
| 分布式锁 | 防止缓存重建时的并发问题 | 实现复杂,性能开销大 | 缓存重建成本高的场景 |
2.3.2 综合解决方案设计
综合方案建议:
-
多层防护体系:
- 第一层:请求参数校验,快速拦截明显非法请求
- 第二层:布隆过滤器,拦截大量不存在的数据请求
- 第三层:空值缓存,拦截重复的不存在数据请求
- 第四层:接口限流,防止恶意用户或IP的高频攻击
-
动态调整策略:
- 根据业务流量和攻击模式动态调整布隆过滤器的容量和误判率
- 调整空值缓存的过期时间,平衡内存使用和防护效果
-
监控与报警:
- 监控缓存穿透率和数据库无效查询比例
- 设置阈值触发报警,及时发现异常流量
实际应用案例:
电商平台的商品详情页通常使用以下方案防护缓存穿透:
- 对商品ID进行合法性校验,确保为合法的数值且符合长度要求
- 使用布隆过滤器存储所有已上架商品的ID
- 对查询结果为空的商品ID缓存空值,设置5分钟过期时间
- 对商品详情接口实施限流,防止同一IP频繁请求
三、MongoDB常见问题与解决方案
3.1 MongoDB性能优化问题
3.1.1 MongoDB IOPS使用率高问题
问题现象:MongoDB实例的IOPS使用率达到或接近100%,导致业务响应缓慢,甚至业务不可用。
常见原因:
- 内存不足:CacheSize越小,系统刷脏越频繁,IOPS越高
- 索引过多:创建过多索引会增加写入时的IO操作
- 写入量过大:业务写入量超出MongoDB实例处理能力
- 并发写入/读取线程数过高:过高的并发写入速度和复杂查询并发数引起IOPS瓶颈
解决方案:
- 升级实例规格:若IOPS瓶颈是由于业务写入量导致,建议升级至更高规格的MongoDB实例
- 优化索引设计:
- 删除不必要的索引
- 优化复合索引的字段顺序
- 避免在频繁更新的字段上创建索引
- 控制并发写入/读取线程数:
- 调整应用程序的并发线程数
- 采用队列或消息中间件缓冲写入请求
- 避免峰值写入:
- 将批量写入操作拆分为较小的批次
- 为每个批量写入操作添加随机时间片,平滑写入压力
- 业务架构优化:
- 将MongoDB实例升级至分片集群模式,通过数据的水平拆分来线性扩容MongoDB的写入性能
- 避免业务高峰期执行可能引起IO高的操作,如批量写入、更新、删除数据,添加索引等
3.1.2 MongoDB查询性能优化
案例背景:某电商平台的订单查询接口在处理数十亿条记录时,查询时间长达250秒,严重影响用户体验。
优化过程:
-
第一次优化:索引优化
- 分析查询语句,确定需要的字段
- 创建复合索引,覆盖查询条件和排序字段
- 查询时间从250秒缩短到30秒
-
第二次优化:投影优化
- 只查询必要的字段,减少数据传输量
- 使用
_id:0排除不需要的_id字段 - 查询时间进一步缩短到15秒
-
第三次优化:聚合管道优化
- 重写查询逻辑,使用MongoDB的聚合管道进行数据处理
- 利用
$match、$sort、$limit等操作符优化查询流程 - 查询时间最终缩短到4秒
优化建议:
-
使用
explain分析查询计划:db.collection.find(query).explain()通过分析查询计划,确定是否使用了正确的索引,扫描的文档数量等
-
覆盖查询优化:
- 确保查询的字段都包含在索引中,实现覆盖查询
- 减少对数据文件的访问,提高查询效率
-
聚合管道优化:
- 优先使用
$match过滤数据,尽早减少数据量 - 在适当的阶段使用
$sort和$limit,避免处理过多数据 - 考虑使用
allowDiskUse选项处理需要排序的大数据集
- 优先使用
-
避免全表扫描:
- 确保查询条件字段上有合适的索引
- 避免使用
$nin、$not等可能导致全表扫描的操作符
3.1.3 MongoDB慢查询日志分析与优化
慢查询日志启用:
在MongoDB配置文件中,将operationProfiling设置为true,并调整slowOpThresholdMs(单位:毫秒)。
慢查询日志分析步骤:
-
收集慢查询日志:
- 使用
db.getProfilingLevel()检查当前慢查询日志级别 - 使用
db.system.profile.find()查询慢查询日志
- 使用
-
分析慢查询原因:
- 检查是否缺少索引
- 评估查询条件是否合理
- 分析返回结果集大小是否过大
-
优化慢查询:
- 根据分析结果创建或优化索引
- 调整查询语句,减少扫描的文档数量
- 限制返回结果集的大小
慢查询优化示例:
假设有一个慢查询如下:
db.orders.find({status: "completed", total_amount: {$gt: 100}}).sort({order_date: -1})
优化步骤:
-
创建复合索引:
db.orders.createIndex({status: 1, total_amount: 1, order_date: -1}) -
调整查询语句:
// 先过滤再排序,减少数据量 db.orders.find({status: "completed", total_amount: {$gt: 100}}) .sort({order_date: -1}) .limit(10) // 限制返回结果数量 -
使用投影减少数据传输:
db.orders.find({status: "completed", total_amount: {$gt: 100}}, {_id: 0, order_number: 1, order_date: 1, total_amount: 1}) .sort({order_date: -1}) .limit(10)
优化效果评估:
通过监控工具对比优化前后的查询执行时间、扫描文档数和返回文档数,评估优化效果。
3.2 MongoDB开发与运维问题
3.2.1 MongoDB事务处理问题
事务支持限制:
- 版本要求:MongoDB从4.0版本开始支持多文档事务,4.0版本仅支持副本集事务,4.2版本开始支持分片集群事务
- 架构要求:必须在副本集环境中运行MongoDB,不能在单机模式下使用事务
- 事务大小限制:最大事务大小(包括数据和日志)不能超过16MB,事务中的操作数量不能超过1000个
事务未生效的常见场景:
- MongoDB版本不支持事务:若版本低于4.0,事务功能无法生效
- 连接配置错误:未使用副本集连接字符串,直接连接单节点而非副本集成员
- 会话管理不当:未显式开启客户端会话(ClientSession)或在多个会话中执行事务操作
- 事务操作违规:在事务中执行不支持的操作(如
createCollection),或事务超时、超出大小限制 - 异常处理缺陷:在事务执行过程中未正确处理异常,未及时回滚或提交事务
解决方案:
-
验证和升级MongoDB版本:
- 使用
mongo --eval 'db.version()'查看版本 - 升级到支持事务的版本(4.0或更高)
- 使用
-
正确配置连接字符串:
- 对于副本集,使用
mongodb://host1:27017,host2:27017,host3:27017/?replicaSet=rs0格式的连接字符串 - 对于分片集群,按照相应的格式进行配置
- 对于副本集,使用
-
规范会话管理:
- 显式开启客户端会话(ClientSession)
- 确保事务内的所有操作都在同一个会话实例下进行
-
合规执行事务操作:
- 避免在事务中使用不支持的操作
- 合理控制事务的执行时间和操作量
- 必要时将大事务拆分成多个较小的事务
-
完善异常处理机制:
- 在事务执行的代码块中添加全面的异常捕获和处理逻辑
- 一旦捕获到异常,立即调用
abortTransaction方法终止事务会话
事务性能优化建议:
-
设置合理的事务超时时间:
clientSession.startTransaction(TransactionOptions.builder() .maxCommitTime(Duration.ofSeconds(60)) .build());默认超时时间为60秒,可根据业务需求调整
-
监控事务性能:
- 添加命令监听,监控事务的执行情况
- 在MongoClientSettings中添加
CommandListener监控事务执行
-
避免长事务:
- 减少事务中的操作数量
- 避免在事务中执行耗时操作
- 将复杂的业务逻辑拆分成多个短小的事务
3.2.2 MongoDB批量插入失败问题
批量插入失败常见原因:
- 事务大小限制:MongoDB对单个事务的大小限制为16MB,操作数量限制为1000个
- 锁竞争:多个客户端同时对同一集合进行插入操作,导致锁竞争
- 系统资源不足:服务器CPU、内存或磁盘IO资源不足
- 网络问题:网络不稳定或出现故障导致批量插入失败
- 重复键错误:插入的数据违反了唯一性约束
解决方案:
-
分批插入:
- 将大批量数据拆分成多个较小的批次(如每批500条)
- 每批数据使用单独的事务处理
-
优化事务配置:
- 调整
writeConcern参数,降低写入安全性要求以提高性能 - 必要时使用
w:1(默认)而不是w:majority
- 调整
-
提升系统资源:
- 增加服务器CPU或内存资源
- 优化磁盘IO性能
-
稳定网络连接:
- 检查网络状况和服务器配置
- 增加网络带宽或使用更稳定的网络连接
-
处理重复键错误:
- 使用
upsert操作,当数据不存在时插入,存在时更新 - 在事务中捕获
duplicate key error,进行相应的处理(如重试或记录日志)
- 使用
批量插入优化示例:
// 分批插入示例
function batchInsert(collection, data, batchSize) {
for (let i = 0; i < data.length; i += batchSize) {
const batch = data.slice(i, i + batchSize);
try {
collection.insertMany(batch, {ordered: false});
} catch (e) {
console.error("Batch insertion failed:", e);
// 处理错误,如记录日志或重试
}
}
}
3.2.3 MongoDB分片集群负载均衡问题
分片集群负载不均原因:
- 数据分布不均:某些分片包含的数据量远大于其他分片
- 查询分布不均:某些分片接收到的查询请求远多于其他分片
- 哈希策略问题:负载均衡服务通过源IP Hash策略,将不同请求源IP路由到不同的Mongos节点
- 批量扫描和getMore问题:某些查询操作可能导致特定Mongos节点负载过高
解决方案:
-
数据均衡:
- 使用
sh.status()检查分片状态 - 使用
sh.moveChunk()手动迁移数据Chunk - 调整分片键,确保数据分布更均匀
- 使用
-
查询均衡:
- 分析查询模式,优化查询语句
- 避免在分片键上使用范围查询,导致某些分片负载过高
- 使用
hint()强制查询使用特定索引
-
调整负载均衡策略:
- 根据业务需求调整负载均衡策略
- 考虑使用轮询或其他负载均衡算法替代源IP Hash
-
增加Mongos节点:
- 增加Mongos节点数量,分散请求压力
- 配置负载均衡器将请求均匀分发到多个Mongos节点
分片集群性能优化建议:
-
合理选择分片键:
- 选择基数高、分布均匀的字段作为分片键
- 避免选择单调递增的字段作为分片键
-
索引优化:
- 确保分片键上有索引
- 优化复合索引的设计,提高查询效率
-
监控与告警:
- 设置告警阈值,及时发现并处理分片集群中的性能问题
- 使用监控工具监控各分片的CPU、内存、网络和磁盘IO使用率
-
动态扩容分片:
- 业务增长时及时增加分片节点
- 根据数据量和查询负载动态调整分片数量
3.3 MongoDB备份与恢复策略
3.3.1 MongoDB全量备份与恢复
全量备份方法:
-
使用mongodump工具:
mongodump -h db_host -d db_name -o db_directory -u user -p password- 参数说明:
-h:服务器IP地址-d:需要备份的数据库库名-o:备份的数据存放位置-u -p:用户名和密码(如果需要)
- 参数说明:
-
使用文件系统快照:
- 对MongoDB数据目录进行文件系统快照
- 需要先暂停数据库服务或将其切换到只读模式
-
复制集备份:
- 在复制集的Secondary节点上进行备份操作
- 避免影响Primary节点的正常读写
全量恢复方法:
-
使用mongorestore工具:
mongorestore -h db_host -d db_name --dir db_directory -u user -p password- 参数说明:
-h:服务器IP地址-d:需要恢复的数据库库名--dir:备份数据的目录-u -p:用户名和密码(如果需要)
- 参数说明:
-
文件系统快照恢复:
- 恢复文件系统快照到指定目录
- 启动MongoDB服务,指定新的数据目录
-
复制集恢复:
- 将Secondary节点提升为Primary节点
- 重新配置复制集
全量备份最佳实践:
- 定期备份:根据业务需求制定合理的备份频率
- 异地存储:将备份文件存储在不同的地理位置,防止单点故障
- 加密备份:对备份文件进行加密处理,保护敏感数据
- 定期测试恢复流程:确保备份数据可用
3.3.2 MongoDB增量备份与时间点恢复
增量备份方法:
-
使用oplog备份:
mongodump -h 192.168.0.193 --port 27017 -uroot -pUcloudcn --authenticationDatabase=admin -d local -c oplog.rs -o /opt/oplogbackup- 说明:备份
oplog.rs集合,记录了所有数据库操作
- 说明:备份
-
结合全量备份和oplog:
- 定期进行全量备份
- 同时备份
oplog.rs集合作为增量备份
时间点恢复方法:
-
恢复全量备份:
mongorestore -h 192.168.0.193 --port 27017 /opt/fullbackup/ -uroot -pUcloudcn -
重放oplog:
mongorestore --oplogReplay --oplogLimit "1622257440:1" --drop /opt/oplogbackup/local/oplog.rs.bson -uroot -pUcloudcn- 参数说明:
--oplogReplay:重放oplog日志--oplogLimit:指定恢复到的时间点
- 参数说明:
时间点恢复场景分析:
-
场景一:备份开始的时间点A到误删除的时间点C这段时间的
oplog.rs数据未被覆盖- 可以完全恢复出所有数据
- 直接用
oplog全量备份的oplog.rs.bson文件替换之前全量备份的产生的oplog.bson文件,然后恢复时使用--oplogReplay和--oplogLimit参数
-
场景二:备份开始的时间点A到误删除的时间点C这段时间的
oplog.rs数据被覆盖了- 只能先恢复全备,然后再从
oplog.rs里面尽可能找到更多的关于这个集合的操作 - 恢复效果取决于能否找到足够的操作日志
- 只能先恢复全备,然后再从
增量备份与恢复最佳实践:
- 定期备份oplog:设置合理的oplog备份频率
- 监控oplog空间使用:确保oplog有足够的空间存储必要的操作日志
- 测试时间点恢复流程:定期验证时间点恢复功能是否正常工作
- 保留足够的备份历史:根据业务需求保留足够的历史备份和oplog日志
3.3.3 MongoDB云服务备份解决方案
MongoDB Atlas备份:
- 自动备份:MongoDB Atlas云服务会自动进行备份,并提供灵活的恢复选项
- 时间点恢复:支持恢复到任意时间点的数据
- 备份策略配置:
- 可以配置备份保留策略
- 可以配置备份窗口,避免在业务高峰期进行备份
云数据库MongoDB备份与恢复:
-
控制台备份:
- 登录MongoDB管理控制台
- 在备份管理页面创建手动备份
- 查看备份历史和恢复状态
-
自动化备份策略:
- 设置自动备份计划
- 指定备份保留天数
- 配置备份存储位置
-
恢复操作:
- 选择需要恢复的备份
- 指定恢复的时间点(如果支持)
- 选择恢复的目标实例
云服务备份最佳实践:
- 利用云服务的自动备份功能:减少手动操作,提高可靠性
- 配置多区域备份:将备份存储在不同的地理区域,提高容灾能力
- 定期测试云备份恢复流程:确保备份可用
- 结合云服务的监控和告警:及时发现备份失败或异常情况
四、Redis常见问题与解决方案
4.1 Redis内存管理问题
4.1.1 Redis内存淘汰策略详解
内存淘汰策略概述:
当Redis内存达到maxmemory限制时,根据配置策略自动删除部分键值对。策略选择直接影响系统性能和业务逻辑,需根据数据特征谨慎选择。
Redis支持的8种内存淘汰策略:
-
noeviction(默认策略):
- 行为:拒绝所有写请求(DEL除外),返回OOM错误
- 适用场景:数据不可丢失的关键业务
- 风险提示:可能导致服务中断
-
allkeys-lru:
- 算法:近似LRU(最近最少使用)
- 范围:全体键
- 特点:自动淘汰冷数据
- 推荐场景:缓存系统
-
volatile-lru:
- 算法:近似LRU
- 范围:仅过期字典(设过期时间的键)
- 优势:保护持久数据
- 典型应用:混合存储场景
-
allkeys-random:
- 行为:随机删除任意键
- 适用场景:测试环境或数据分布均匀的场景
-
volatile-random:
- 行为:随机删除设置了过期时间的键
- 适用场景:测试环境或数据分布均匀的场景
-
volatile-ttl:
- 行为:优先删除剩余生存时间短的键
- 适用场景:寿命长的数据需要优先保留的场景
-
allkeys-lfu:
- 算法:近似LFU(最近最不常用)
- 范围:全体键
- 特点:淘汰访问频率最低的键
- 推荐场景:长期缓存
-
volatile-lfu:
- 算法:近似LFU
- 范围:仅过期字典(设过期时间的键)
- 适用场景:混合存储场景
4.1.2 如何选择合适的内存淘汰策略
选择策略考虑因素:
- 数据特征:是否所有数据都可淘汰,是否需要保留部分持久数据
- 访问模式:数据访问是否符合LRU或LFU模式
- 业务需求:对数据一致性和可用性的要求
- 性能目标:缓存命中率和响应时间要求
不同场景下的推荐策略:
-
缓存场景:
- 推荐策略:
allkeys-lru或allkeys-lfu - 理由:优先保留热点数据,最大化缓存命中率
- 推荐策略:
-
持久化存储:
- 推荐策略:
noeviction(需确保内存足够或启用持久化) - 替代方案:若允许部分数据丢失,可使用
volatile-lru结合过期时间
- 推荐策略:
-
临时数据场景:
- 推荐策略:
volatile-ttl - 理由:自动清理生命周期明确的数据(如验证码、会话信息)
- 推荐策略:
-
混合型数据:
- 推荐策略:
allkeys-lru+ 部分键设置过期时间 - 示例:电商系统中,商品详情用
allkeys-lru缓存,购物车数据设置TTL
- 推荐策略:
策略选择误区:
- volatile-ttl依赖惰性删除:该策略仅在内存不足时触发,仍需依赖定期/惰性删除清理过期键
- LFU计数器并非精确值:访问频率通过概率递增,适用于相对比较而非绝对计数
- LRU算法是近似实现:Redis使用采样方法实现近似LRU,而非精确LRU
4.1.3 Redis内存淘汰底层实现原理
LRU/LFU近似算法:
-
LRU实现:
- Redis使用近似LRU算法,通过随机采样(默认取5个键)选择最久未使用的键
- 而非遍历所有键,以减少计算开销
-
LFU实现:
- Redis实现的LFU会随时间衰减访问计数
- 避免旧热点数据长期霸占内存
-
LRU时钟:
- Redis使用全局24位时钟(精度为秒)记录键的最近访问时间
- 内存中每个对象存储与全局时钟的差值(
lru字段),而非精确时间戳
-
LFU计数器:
- 每个键的
lru字段被拆分为两部分:- 高16位:最近访问时间的分钟级精度
- 低8位:访问频率计数器(0~255),通过概率递增,随时间衰减
- 每个键的
淘汰流程:
- 客户端执行写入命令触发内存检查
- Redis检查
maxmemory是否已超出 - 根据配置的策略选择待淘汰键
- 删除键并触发相关事件(如
evicted通知)
内存淘汰监控:
-
查看内存指标:
INFO memory # 查看内存指标(used_memory、maxmemory) -
查看淘汰键数量:
INFO stats # 查看evicted_keys(淘汰键数量) -
监控内存使用趋势:
- 使用监控工具(如RedisInsight、Prometheus)实时跟踪内存使用情况
- 设置告警阈值,当内存使用接近
maxmemory时触发告警
4.2 Redis集群与高可用问题
4.2.1 Redis集群配置与管理
集群搭建步骤:
-
配置文件准备:
- 为每个节点创建独立的配置文件
- 设置
cluster-enabled yes启用集群模式 - 设置
cluster-config-file nodes.conf指定集群配置文件 - 设置
cluster-node-timeout 5000指定节点超时时间
-
启动节点:
redis-server.exe redis-7000.conf redis-server.exe redis-7001.conf redis-server.exe redis-7002.conf -
创建集群:
redis-cli --cluster create \ 127.0.0.1:7000 \ 127.0.0.1:7001 \ 127.0.0.1:7002 \ --cluster-replicas 1- 参数说明:
--cluster-replicas 1表示每个主节点配置1个从节点
- 参数说明:
-
验证集群状态:
redis-cli -c -h 127.0.0.1 -p 7000 cluster info- 说明:
-c参数表示启用集群模式连接
- 说明:
集群配置常见问题:
-
集群总线端口未开放:
- 问题现象:集群节点无法通信,
CLUSTER NODES显示节点状态异常 - 解决方案:
- 集群总线端口为节点端口加10000
- 例如,节点端口为7001,则总线端口为17001
- 确保防火墙开放对应的总线端口
- 问题现象:集群节点无法通信,
-
节点数据残留:
- 问题现象:节点无法加入集群,提示已有集群配置
- 解决方案:
- 清理旧集群数据
- 删除节点目录下的
nodes.conf文件
-
版本兼容性问题:
- 问题现象:不同版本的Redis节点无法组成集群
- 解决方案:
- 使用统一版本的Redis节点
- 确保所有节点版本一致
集群管理最佳实践:
-
监控集群状态:
- 定期检查
CLUSTER INFO和CLUSTER NODES输出 - 使用监控工具(如Redis Cluster Monitor)实时监控集群状态
- 设置告警,当节点故障或数据分片不均时及时通知
- 定期检查
-
节点扩容与缩容:
- 扩容:使用
redis-cli --cluster add-node添加新节点 - 缩容:使用
redis-cli --cluster del-node删除节点 - 数据迁移:使用
redis-cli --cluster reshard重新分片
- 扩容:使用
-
故障处理:
- 单个节点故障:集群会自动进行故障转移
- 多个节点故障:需手动干预恢复
- 数据恢复:从备份中恢复故障节点数据
4.2.2 Redis脑裂问题分析与解决方案
脑裂问题定义:
脑裂问题是指在分布式系统中,由于网络分区或节点故障,集群中多个节点认为自己是主节点(Master),从而导致数据的不一致性。
脑裂问题成因:
-
网络分区:
- 集群中的节点之间的通信被网络故障隔断
- 每个分区内的节点无法知道其他分区的节点状态
- 可能导致多个主节点的产生
-
主节点故障:
- 当主节点发生故障时,Redis Sentinel或其他高可用性机制会进行主从切换
- 如果在切换过程中,原主节点恢复并未能正确识别自己已经不是主节点,则可能产生脑裂问题
-
配置不当:
- 不正确的高可用性配置可能导致在网络抖动或节点短暂失联时,错误地进行主从切换
- 从而引发脑裂问题
脑裂问题影响:
-
数据不一致:
- 由于存在多个主节点,客户端可能向不同的主节点写入数据
- 导致数据不一致
-
数据丢失:
- 在脑裂期间写入的数据,可能在故障恢复后无法合并
- 从而导致数据丢失
-
服务中断:
- 脑裂问题可能导致部分或全部客户端无法正确访问数据
- 造成服务中断
脑裂问题解决方案:
-
合理配置Redis Sentinel:
- 配置
quorum参数:决定了Sentinel判断主节点失效所需的投票数 - 增加Sentinel数量:提高集群的容错能力,通常建议配置奇数个Sentinel节点
- 配置
-
开启保护模式:
- Redis 3.2引入了保护模式,可以在检测到脑裂时阻止新的主节点接受写请求
- 配置
protected-mode yes开启保护模式
-
使用更高级的分布式系统框架:
- 在需要更高可用性和更强一致性的场景下,可以使用诸如Redlock或其他分布式锁机制
- 确保在多个数据中心之间的一致性和可用性
-
配置客户端连接策略:
- 在客户端层面,通过合理的重试和超时配置,减少因短暂网络抖动引发的脑裂问题
- 配置客户端在连接失败时的重试次数和间隔
- 设置合理的连接超时和操作超时,避免长时间的等待引发的误判
脑裂问题预防措施:
-
网络监控和优化:
- 保持集群网络的稳定性
- 使用高质量的网络设备和链路
- 监控网络状态,及时处理网络异常
-
定期演练:
- 定期进行故障演练,模拟脑裂场景
- 测试系统的故障恢复能力和一致性处理机制
-
系统监控和报警:
- 通过系统监控和报警机制,及时发现和处理脑裂问题
- 监控包括节点状态、网络延迟、Sentinel日志等
4.2.3 Redis主从复制延迟问题与优化
主从复制延迟原因:
-
网络原因:
- 网络带宽不足或网络抖动导致同步延迟
- 主从节点之间的网络延迟高或带宽不足会导致命令传输变慢
-
主节点写入压力过大:
- 主节点写入量超过从节点处理能力
- 复制缓冲区积压,从节点处理延迟
-
复制缓冲区溢出:
- 复制缓冲区暂存当前主节点接收到的写命令,待传输给从节点
- 如果从节点处理过慢,写入的命令又过多,则会导致复制缓冲区溢出
- 此时从节点就需要重新执行全量复制,导致延迟
-
主节点持久化影响:
- AOF文件重写可能会造成主节点阻塞,影响复制速度
- RDB快照生成期间,主节点可能会暂停处理部分请求,影响复制
-
从节点处理能力不足:
- 从节点配置低于主节点或处理能力不足
- 从节点CPU/内存不足,导致命令执行延迟
主从复制延迟解决方案:
-
优化网络环境:
- 确保主从节点在同一机房或邻近区域
- 增加网络带宽
- 使用专用网络连接
-
优化主节点写入性能:
- 监控主节点写入QPS,合理设置
client-output-buffer-limit - 考虑分片分散写入压力
- 增加从节点数量分担读取压力
- 监控主节点写入QPS,合理设置
-
优化从节点性能:
- 确保从节点与主节点硬件配置相当
- 避免从节点执行耗时操作(如
keys *) - 检查从节点是否有其他资源密集型任务
-
调整复制参数:
- 适当增大
repl-backlog-size(默认1MB) - 根据业务写入量调整,公式建议:
buffer_size = 写入速度 * 最大延迟时间 * 2 - 调整
repl-timeout值,避免因超时而中断复制过程
- 适当增大
-
优化持久化配置:
- 对于从节点,考虑关闭持久化(但有数据丢失风险)
- 使用无盘复制(
repl-diskless-sync)配置 - 避免从节点执行AOF重写或RDB快照
监控与诊断方法:
-
查看复制状态:
redis-cli info replication- 关注
master_repl_offset和slave_repl_offset的差异 - 查看
master_last_io_seconds_ago:最后一次IO时间 - 查看
slave_lag:从节点延迟秒数
- 关注
-
监控指标:
- 使用监控工具(如Prometheus、Grafana)监控复制延迟指标
- 设置告警阈值,当复制延迟超过阈值时触发告警
-
慢查询日志:
redis-cli slowlog get- 检查是否有慢查询影响主节点性能
优化建议总结:
- 网络优化:确保低延迟、高带宽连接
- 资源配置:主从节点硬件配置匹配
- 参数调优:合理设置
repl-backlog-size和client-output-buffer-limit - 架构设计:考虑级联复制或分片减轻主节点压力
- 监控告警:建立完善的复制延迟监控体系
4.3 Redis开发与运维问题
4.3.1 Redis连接池配置与管理
连接池配置参数:
-
最大连接数:
maxTotal:连接池中的最大连接数- 建议值:根据应用程序并发需求设置,通常为100-200
-
最大空闲连接数:
maxIdle:连接池中允许保持空闲状态的最大连接数- 建议值:通常设置为最大连接数的1/3到1/2
-
最小空闲连接数:
minIdle:连接池中确保保持的最小空闲连接数- 建议值:根据应用程序的基础并发需求设置
-
连接超时:
timeout:获取连接的超时时间(单位:毫秒)- 建议值:通常设置为5000-10000毫秒
-
测试连接有效性:
testOnBorrow:在从连接池获取连接时测试连接是否有效testOnReturn:在归还连接到连接池时测试连接是否有效- 建议值:通常设置为
true
连接池配置优化建议:
-
根据业务需求调整参数:
- 高并发写入场景:增加最大连接数
- 读多写少场景:适当减少最大连接数
- 连接长时间空闲的场景:调整
minIdle和maxIdle参数
-
避免连接泄漏:
- 确保在使用完连接后及时归还到连接池
- 使用
try-finally块确保连接被正确释放 - 监控连接池的连接使用情况,及时发现连接泄漏
-
监控连接池状态:
- 监控连接池的活跃连接数、空闲连接数和等待队列长度
- 设置告警,当连接池达到最大连接数或等待队列过长时触发告警
- 使用监控工具(如JMX、Prometheus)监控连接池状态
连接池耗尽问题解决方案:
-
排查连接泄漏:
- 检查代码中是否有未正确释放连接的情况
- 使用工具(如VisualVM、YourKit)分析连接使用情况
- 修复连接泄漏问题
-
调整连接池参数:
- 增加
maxTotal参数值,提高连接池容量 - 调整
maxIdle和minIdle参数,优化连接复用 - 增加
timeout参数值,避免因短暂高峰导致连接耗尽
- 增加
-
优化业务逻辑:
- 减少不必要的Redis操作
- 批量处理Redis操作,减少连接使用次数
- 调整业务逻辑,避免在短时间内大量使用Redis连接
4.3.2 Redis过期键删除策略
过期键删除策略:
Redis采用两种策略协同工作来管理过期键:
-
惰性删除:
- 原理:当客户端尝试访问一个键时,Redis会先检查这个键是否设置了过期时间以及是否已过期
- 操作:如果键已过期,Redis会立即删除这个键,然后才执行客户端的访问命令(返回
nil或执行失败) - 优点:对CPU时间友好,只有在真正访问到过期键时才付出删除的成本
- 缺点:对内存不友好,如果一个键设置了过期时间但之后再也没有被访问过,它会一直占用内存空间
-
定期删除:
- 原理:Redis会周期性地、主动地从设置了过期时间的键集合中随机抽取一部分键,检查它们是否过期
- 操作:
- 每次执行时,从过期字典中随机选择一定数量的键
- 删除其中所有已过期的键
- 如果发现本次检查中过期的键比例超过一定阈值(默认是25%),则立即再随机抽取一批键进行检查(循环)
- 直到过期键比例降到阈值以下或达到时间限制(避免过度占用CPU)
- 优点:一定程度上减少了惰性删除带来的内存浪费问题
- 缺点:需要平衡扫描的频率、每次扫描的数量以及CPU消耗
过期键删除与内存淘汰的关系:
-
内存淘汰触发条件:
- 当内存不足且需要写入新数据时,Redis会根据配置的内存淘汰策略删除部分键
- 内存淘汰策略与过期键删除策略相互独立但又协同工作
-
过期键处理流程:
- 先通过惰性删除和定期删除处理过期键
- 如果内存仍然不足,再根据内存淘汰策略删除非过期键
过期键删除策略优化:
-
调整定期删除频率:
- 通过
hz配置参数调整Redis的定期删除频率(单位:次/秒) - 默认值为10,即每秒执行10次定期删除检查
- 可以根据业务需求适当增加
hz值,提高过期键删除频率
- 通过
-
优化过期键分布:
- 避免大量键设置相同的过期时间
- 使用随机过期时间偏移量,分散过期键的过期时间点
- 减少同一时间过期的键数量
-
监控过期键处理情况:
- 使用
INFO stats命令查看expired_keys指标(已删除的过期键数量) - 使用
INFO persistence命令查看expired_stale_perc指标(过期键的比例) - 设置告警,当过期键比例过高时触发告警
- 使用
过期键删除策略最佳实践:
-
合理设置过期时间:
- 根据业务需求设置合理的键过期时间
- 对于短期数据,设置较短的过期时间
- 对于长期数据,考虑使用内存淘汰策略而非过期时间
-
定期清理无用键:
- 定期检查并删除不再使用的键
- 避免在Redis中存储大量长期不用的数据
- 使用
SCAN命令遍历键空间,识别并删除无用键
-
结合内存淘汰策略:
- 根据数据特征选择合适的内存淘汰策略
- 对于可过期的数据,考虑使用
volatile-lru或volatile-ttl策略 - 对于不可过期的数据,使用
allkeys-lru或allkeys-lfu策略
4.3.3 Redis常见错误处理与调试
Redis常见错误类型:
-
连接错误:
Could not connect to Redis at 127.0.0.1:6379: Connection refused- 原因:Redis服务未启动、端口错误或防火墙阻止连接
- 解决方案:启动Redis服务,检查端口和防火墙设置
-
命令错误:
(error) ERR unknown command 'XYZ'- 原因:使用了Redis不支持的命令
- 解决方案:检查命令拼写,确认Redis版本是否支持该命令
-
数据类型错误:
(error) WRONGTYPE Operation against a key holding the wrong kind of value- 原因:对错误数据类型的键执行了操作
- 解决方案:检查键的数据类型,确保操作与数据类型匹配
-
内存不足错误:
(error) OOM command not allowed when used memory > 'maxmemory'- 原因:内存达到
maxmemory限制且内存淘汰策略为noeviction - 解决方案:调整内存淘汰策略或增加内存容量
-
事务错误:
(error) EXECABORT Transaction discarded because of previous errors- 原因:事务中有错误的命令
- 解决方案:检查事务中的命令是否正确,确保所有命令在执行时有效
错误处理最佳实践:
-
统一异常处理:
- 在应用程序中统一处理Redis异常
- 使用try-catch块捕获Redis异常
- 记录详细的错误信息,包括错误类型、错误信息和上下文信息
-
错误重试机制:
- 对于暂时性错误(如连接超时、网络抖动),实现重试机制
- 设置合理的重试次数和重试间隔
- 避免无限重试导致系统资源耗尽
-
错误分类处理:
- 根据错误类型采取不同的处理策略
- 对于永久性错误(如命令错误、数据类型错误),立即返回错误信息
- 对于暂时性错误(如连接失败、超时),进行重试或切换到备用节点
调试工具与方法:
-
Redis CLI工具:
- 使用
redis-cli直接连接Redis服务器,执行命令测试 - 使用
MONITOR命令监控Redis服务器接收到的所有命令 - 使用
DEBUG命令进行底层调试(谨慎使用)
- 使用
-
日志分析:
- 查看Redis服务器日志文件,分析错误原因
- 开启详细日志记录,增加调试信息
- 使用日志分析工具(如ELK Stack)分析日志数据
-
监控工具:
- 使用
INFO命令获取Redis服务器状态信息 - 使用
SLOWLOG命令查看慢查询日志 - 使用监控工具(如RedisInsight、Prometheus)实时监控Redis性能指标
- 使用
五、NoSQL数据库技术选型与优化
5.1 MongoDB与Redis对比分析
数据模型对比:
-
MongoDB:
- 数据模型:文档型(BSON格式)
- 数据结构:灵活的文档结构,支持嵌套文档和数组
- 适用场景:存储半结构化数据,如用户信息、内容管理、日志记录等
-
Redis:
- 数据模型:键值型,支持多种数据结构(字符串、哈希、列表、集合、有序集合等)
- 数据结构:每种数据结构有不同的操作命令
- 适用场景:缓存、会话管理、计数器、排行榜、消息队列等
性能特点对比:
-
MongoDB:
- 读写性能:适合大量数据的读写操作,性能随数据量增长线性下降
- 扩展性:支持水平扩展(分片集群),可通过添加节点处理更大的数据量和更高的并发
- 索引性能:支持复合索引,但索引维护会增加写入开销
-
Redis:
- 读写性能:内存数据库,读写速度极快,性能几乎不受数据量影响
- 扩展性:支持主从复制和集群,但主要是垂直扩展(增加内存)
- 数据结构性能:不同数据结构有不同的时间复杂度,总体操作复杂度较低
持久化与数据安全对比:
-
MongoDB:
- 持久化方式:支持WiredTiger存储引擎的持久化,数据写入磁盘
- 数据安全:支持复制集(Replica Set)和自动故障转移,提供高可用性
- 备份恢复:提供
mongodump、mongorestore等工具,支持全量备份和增量备份
-
Redis:
- 持久化方式:支持RDB快照和AOF日志两种持久化方式,可单独或组合使用
- 数据安全:支持主从复制,但数据主要存储在内存中,存在数据丢失风险
- 备份恢复:提供
SAVE、BGSAVE等命令生成RDB快照,支持基于快照的备份恢复
使用场景对比:
-
MongoDB适用场景:
- 需要存储大量半结构化数据的应用
- 需要复杂查询和聚合分析的场景
- 需要水平扩展的大数据量存储场景
- 内容管理系统、日志分析、物联网数据存储等
-
Redis适用场景:
- 高性能缓存系统,减少数据库访问压力
- 实时数据处理,如计数器、排行榜、实时统计
- 消息队列和发布/订阅系统
- 分布式锁、会话管理、短时间内的高频读写场景
优缺点对比:
| 特性 | MongoDB | Redis |
|---|---|---|
| 数据模型 | 文档型,灵活的结构 | 键值型,支持多种数据结构 |
| 性能 | 适合大量数据存储和查询,性能随数据量增长下降 | 内存数据库,性能极高且稳定 |
| 扩展性 | 水平扩展(分片集群) | 主从复制和集群,但主要是垂直扩展 |
| 持久化 | 基于磁盘的持久化,数据安全较高 | 支持RDB和AOF,但数据主要在内存中 |
| 适用场景 | 大数据存储、复杂查询、半结构化数据 | 高性能缓存、实时数据处理、消息队列 |
| 学习曲线 | 中等,需要理解文档模型和查询语言 | 简单,命令简洁,数据结构容易掌握 |
5.2 NoSQL数据库选型策略与决策因素
选型决策因素:
-
数据模型需求:
- 数据结构是否结构化、半结构化或非结构化
- 是否需要灵活的数据模型,允许动态变化
- 是否需要支持复杂的查询和聚合操作
-
性能需求:
- 读写性能要求
- 数据量大小和增长趋势
- 并发访问量和峰值负载
- 响应时间要求
-
扩展性需求:
- 需要水平扩展还是垂直扩展
- 预期的数据增长速度
- 分布式架构需求
-
数据安全与持久化需求:
- 数据丢失的容忍程度
- 数据持久化的要求
- 备份和恢复的需求
- 高可用性和容灾需求
-
开发团队技能:
- 团队成员对不同NoSQL数据库的熟悉程度
- 学习新数据库的成本和时间
- 社区支持和资源丰富程度
不同场景下的选型建议:
-
缓存场景:
- 推荐数据库:Redis
- 理由:内存数据库,高性能,支持丰富的数据结构
- 备选方案:Memcached(仅支持简单键值对)
-
日志存储场景:
- 推荐数据库:MongoDB
- 理由:文档型数据库,适合存储半结构化日志数据,支持高效的查询和分析
- 备选方案:Elasticsearch(更适合日志分析和全文搜索)
-
实时数据处理场景:
- 推荐数据库:Redis
- 理由:支持高性能的读写操作,提供丰富的数据结构和原子操作
- 备选方案:Apache Kafka(更适合高吞吐量的消息处理)
-
内容管理系统:
- 推荐数据库:MongoDB
- 理由:灵活的文档模型,适合存储和查询内容数据
- 备选方案:CouchDB(更适合分布式内容管理)
-
物联网数据存储:
- 推荐数据库:MongoDB
- 理由:支持海量数据存储和水平扩展,适合存储时间序列数据
- 备选方案:InfluxDB(专门为时间序列数据设计)
混合使用策略:
-
缓存+持久化存储:
- Redis作为缓存层,MongoDB作为持久化存储
- 优点:结合Redis的高性能和MongoDB的数据持久化优势
- 适用场景:大多数Web应用和高并发系统
-
数据处理管道:
- Redis作为消息队列,MongoDB作为结果存储
- 优点:利用Redis的消息传递能力和MongoDB的数据分析能力
- 适用场景:实时数据处理和分析系统
-
分布式系统组件:
- Redis用于分布式锁和会话管理,MongoDB用于业务数据存储
- 优点:发挥各自的专长,构建高效可靠的分布式系统
- 适用场景:大型分布式系统和微服务架构
5.3 NoSQL数据库优化策略与最佳实践
通用优化策略:
-
数据模型优化:
- 根据查询模式设计数据模型
- 避免过度规范化或过度嵌套
- 合理使用索引,提高查询效率
-
资源配置优化:
- 根据工作负载配置合适的硬件资源
- 合理分配CPU、内存和磁盘资源
- 监控资源使用情况,及时调整配置
-
查询优化:
- 分析查询模式,优化查询语句
- 使用合适的索引,避免全表扫描
- 限制返回结果集的大小,减少数据传输量
-
缓存策略优化:
- 合理设置缓存过期时间,避免缓存穿透和雪崩
- 使用布隆过滤器等技术优化缓存命中率
- 监控缓存使用情况,调整缓存策略
MongoDB优化最佳实践:
-
索引优化:
- 根据查询模式创建合适的索引
- 避免在频繁更新的字段上创建索引
- 使用
explain分析查询计划,评估索引使用情况
-
分片策略优化:
- 选择合适的分片键,确保数据分布均匀
- 监控分片状态,及时调整数据分布
- 避免在分片键上使用范围查询,导致热点分片
-
写入性能优化:
- 使用批量写入操作,减少网络开销
- 调整写入关注点(write concern),平衡性能和数据安全
- 避免在主节点执行复杂的读操作,影响写入性能
-
查询性能优化:
- 使用投影减少返回字段数量
- 合理使用聚合管道,避免在应用层处理大量数据
- 优化正则表达式查询和范围查询,减少扫描的数据量
Redis优化最佳实践:
-
内存使用优化:
- 选择合适的数据结构,减少内存占用
- 使用压缩列表(ziplist)和整数集合(intset)等紧凑数据结构
- 监控内存使用情况,及时调整内存淘汰策略
-
连接管理优化:
- 使用连接池管理Redis连接,提高连接复用率
- 合理配置连接池参数,避免连接泄漏和连接池耗尽
- 优化业务逻辑,减少不必要的Redis操作
-
持久化优化:
- 根据业务需求选择合适的持久化方式(RDB或AOF)
- 合理设置持久化参数,避免频繁的持久化操作
- 使用从节点进行持久化操作,避免影响主节点性能
-
过期键管理优化:
- 避免大量键设置相同的过期时间
- 使用随机过期时间偏移量,分散过期键的过期时间点
- 定期清理无用键,减少过期键处理压力
混合使用优化策略:
-
数据分层存储:
- 高频访问的数据存储在Redis缓存中
- 低频访问的数据存储在MongoDB等持久化数据库中
- 使用LRU或LFU策略管理缓存数据,确保热点数据留在内存中
-
读写分离策略:
- 读请求优先访问Redis缓存
- 写请求直接操作持久化数据库,并更新Redis缓存
- 使用异步机制或消息队列同步缓存和数据库,减少一致性问题
-
分布式锁优化:
- 使用Redis实现分布式锁,确保关键操作的原子性
- 设置合理的锁超时时间,避免死锁
- 使用Redlock等算法提高分布式锁的可靠性
监控与运维优化:
-
监控指标设置:
- 为关键性能指标设置监控和告警
- 监控数据库的响应时间、吞吐量和错误率
- 监控资源使用情况,如CPU、内存和磁盘IO
-
定期维护与优化:
- 定期清理无用数据和索引
- 重组和压缩数据库文件,优化存储效率
- 监控慢查询和性能瓶颈,及时调整优化策略
-
应急预案制定:
- 制定数据库故障恢复计划
- 定期测试备份和恢复流程
- 建立容灾和故障转移机制,确保高可用性
六、总结与展望
6.1 NoSQL数据库发展趋势
技术发展趋势:
-
混合数据模型融合:
- 越来越多的NoSQL数据库开始支持多种数据模型
- 如MongoDB支持文档型和时间序列数据,Redis支持键值对和JSON文档
- 趋势:未来NoSQL数据库将提供更灵活的数据模型,满足多样化的业务需求
-
云原生数据库服务:
- 数据库即服务(DBaaS)模式成为主流
- 云提供商提供托管的NoSQL数据库服务,如MongoDB Atlas、Redis Cloud
- 趋势:数据库服务将更加自动化、智能化,提供一键式部署和管理
-
AI与数据库融合:
- 数据库开始集成AI功能,如自动索引优化、异常检测、性能预测
- 如MongoDB Atlas的自动化索引建议和Redis的AI模块
- 趋势:AI将深度融入数据库系统,提供更智能的管理和优化能力
-
边缘计算与分布式数据库:
- 边缘计算场景推动分布式数据库技术发展
- 数据库需要支持更广泛的分布式部署和数据同步
- 趋势:数据库将更注重边缘计算场景下的低延迟、高可用和数据一致性
性能发展趋势:
-
硬件加速技术:
- 使用FPGA、GPU等硬件加速数据库操作
- 如Redis的内存数据库加速技术,MongoDB的WiredTiger存储引擎优化
- 趋势:硬件加速将成为提升数据库性能的重要手段
-
计算存储分离架构:
- 数据库开始采用计算与存储分离的架构设计
- 提高资源利用率和系统弹性,支持更灵活的扩展
- 趋势:计算存储分离将成为大规模分布式数据库的主流架构
-
内存数据库技术演进:
- Redis等内存数据库开始支持更大的内存容量和更高效的内存管理
- 结合持久化技术,减少数据丢失风险
- 趋势:内存数据库将提供更高的性能和更可靠的数据安全保障
应用场景扩展:
-
物联网(IoT)数据管理:
- NoSQL数据库因其灵活的数据模型和扩展性,成为IoT数据管理的首选
- 支持海量设备数据的高效存储和实时分析
- 趋势:IoT将成为NoSQL数据库的重要增长领域
-
实时数据分析:
- NoSQL数据库与实时计算框架(如Apache Flink、Spark Streaming)的集成
- 支持实时数据处理和分析,满足实时业务需求
- 趋势:实时数据分析将成为NoSQL数据库的核心应用场景之一
-
区块链与分布式账本:
- NoSQL数据库的分布式特性与区块链技术高度契合
- 支持区块链数据的高效存储和查询
- 趋势:区块链应用将推动NoSQL数据库技术的进一步发展
6.2 数据库技术栈未来展望
多模态数据库架构:
-
数据模型融合:
- 未来数据库将支持多种数据模型的融合,如文档、键值、图、时序等
- 用户可以根据不同的业务需求选择合适的数据模型
- 趋势:单一数据库支持多模态数据模型将成为主流
-
混合存储架构:
- 结合内存存储和磁盘存储的优势,提供高性能和高可靠性
- 内存数据库支持持久化存储,磁盘数据库提供内存加速
- 趋势:混合存储架构将成为数据库系统的标准配置
-
智能查询优化:
- 利用机器学习和AI技术优化查询计划
- 自动识别查询模式,生成最优执行计划
- 趋势:查询优化将更加智能化和自适应
数据库智能化:
-
自动化管理:
- 数据库将具备自我管理能力,自动完成备份、恢复、扩容等操作
- 自动检测和修复潜在问题,减少人工干预
- 趋势:数据库管理将更加自动化和智能化
-
智能诊断与优化:
- 数据库将提供智能诊断工具,帮助用户快速定位和解决问题
- 自动优化性能参数和资源分配
- 趋势:数据库将成为更加智能的自优化系统
-
预测性维护:
- 利用机器学习预测数据库性能变化和潜在故障
- 提前预警并自动采取措施,避免服务中断
- 趋势:预测性维护将成为数据库运维的重要组成部分
分布式数据库发展:
-
全球分布式数据库:
- 数据库将支持跨地域、跨数据中心的分布式部署
- 提供全球范围内的数据一致性和高可用性
- 趋势:全球化应用将推动分布式数据库技术的发展
-
边缘-中心协同计算:
- 数据库将支持边缘计算和中心云的协同工作
- 边缘节点处理本地实时数据,中心云进行全局数据分析
- 趋势:边缘-中心协同计算将成为未来数据处理的重要模式
-
联邦数据库系统:
- 多个异构数据库系统通过联邦方式协同工作
- 提供统一的数据访问接口,支持跨系统的查询和分析
- 趋势:联邦数据库系统将解决企业数据孤岛问题
数据库安全与隐私保护:
-
加密技术演进:
- 数据库将支持更高级的加密技术,如全同态加密、安全多方计算
- 数据在加密状态下即可进行处理和分析
- 趋势:加密技术将成为数据库安全的基础保障
-
隐私计算技术:
- 数据库将集成隐私计算技术,如差分隐私、匿名化处理
- 在保护用户隐私的同时,允许数据分析和挖掘
- 趋势:隐私计算将成为数据库系统的重要组成部分
-
区块链与数据库融合:
- 利用区块链技术增强数据库的安全性和不可篡改性
- 实现数据的可信存储和可追溯
- 趋势:区块链与数据库的融合将开辟新的应用场景
6.3 开发者与运维人员技能发展方向
数据库开发技能提升:
-
多数据库技术栈掌握:
- 掌握多种数据库技术,包括关系型和非关系型数据库
- 理解不同数据库的适用场景和优缺点
- 能够根据业务需求选择合适的数据库技术
-
数据库设计与优化能力:
- 掌握数据库设计原则和最佳实践
- 具备查询优化和性能调优的能力
- 能够设计高效的数据模型和索引策略
-
分布式系统知识:
- 理解分布式系统的基本原理和挑战
- 掌握分布式数据库的架构设计和实现
- 具备处理分布式一致性和可用性问题的能力
数据库运维技能提升:
-
自动化运维能力:
- 掌握数据库自动化部署和管理技术
- 能够编写自动化脚本和工具,提高运维效率
- 具备监控和告警系统的设计和实施能力
-
故障诊断与恢复能力:
- 掌握数据库故障诊断的方法和工具
- 能够快速定位和解决数据库故障
- 具备完善的备份和恢复策略设计能力
-
性能优化与容量规划:
- 掌握数据库性能分析和优化技术
- 能够进行容量规划和资源分配
- 具备数据库扩展和升级的实施能力
新兴技术学习方向:
-
云原生数据库技术:
- 学习云原生数据库的设计理念和实现技术
- 掌握云数据库服务的使用和管理
- 理解云数据库的弹性扩展和高可用性机制
-
AI与数据库融合技术:
- 学习机器学习和人工智能在数据库中的应用
- 掌握智能查询优化、异常检测等AI数据库技术
- 理解AI模型与数据库集成的方法和挑战
-
边缘计算与数据库:
- 学习边缘计算环境下的数据库设计和应用
- 掌握边缘数据库的同步和一致性技术
- 理解边缘-中心协同数据处理的架构和方法
跨领域技能拓展:
-
数据科学与分析能力:
- 学习数据分析和挖掘技术
- 掌握数据可视化和报告生成方法
- 能够将数据库技术与数据分析结合,提供业务洞察
-
安全与合规知识:
- 学习数据安全和隐私保护技术
- 掌握数据库安全加固和合规审计方法
- 理解数据安全法规和标准,如GDPR、CCPA等
-
系统架构设计能力:
- 学习系统架构设计原则和模式
- 掌握微服务架构和分布式系统设计方法
- 能够设计高可用、可扩展的数据库架构
持续学习与实践:
-
参与开源社区:
- 参与数据库开源项目的贡献和讨论
- 学习最新的数据库技术和发展趋势
- 与行业专家交流经验和见解
-
实践与实验:
- 搭建实验环境,尝试新的数据库技术和架构
- 进行性能测试和对比分析
- 总结经验教训,形成技术积累
-
认证与培训:
- 参加数据库厂商的认证培训和考试
- 获取专业认证,提升职业竞争力
- 参加行业会议和技术研讨会,拓展人脉和视野
七、结语
本文全面解析了MongoDB和Redis等NoSQL数据库的常见问题及解决方案,涵盖了持久化机制、缓存穿透、性能优化、集群管理等多个方面。通过本文的学习,读者可以深入理解NoSQL数据库的工作原理和优化方法,提高解决实际问题的能力。
在实际应用中,数据库技术的选择和优化需要结合具体业务需求和场景特点。随着数据量的不断增长和业务复杂度的提高,数据库技术也在不断演进和创新。作为开发者和运维人员,我们需要保持学习的热情,不断更新知识和技能,才能应对未来的挑战。
无论是MongoDB还是Redis,都有其独特的优势和适用场景。通过合理选择和优化,可以为应用提供高效、可靠的数据支持。在未来的发展中,数据库技术将继续朝着智能化、分布式、多模态的方向演进,为企业数字化转型提供更强大的支持。
最后,希望本文能够帮助读者解决实际工作中的问题,提高数据库应用的性能和可靠性,为构建更加高效、稳定的系统贡献力量。
内容由 AI 生成

















 733
733

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









