






node_netstat_Tcp_RetransSegs 指标采集原理
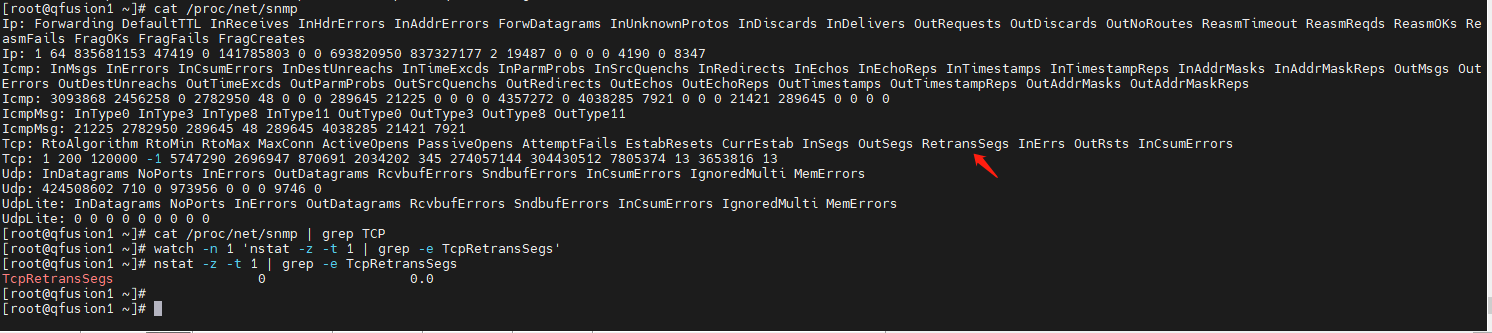
node_netstat_Tcp_RetransSegs 指标是用于监控 TCP 协议中重传的段数,其数据来源于 Linux 系统的 /proc/net/snmp 文件,而不是 /proc/net/netstat 文件。/proc/net/snmp 文件提供了 TCP、UDP 等网络协议的统计数据,其中包含了 TCPRetransSegs 这一关键指标。
-
采集原理
- 在 Linux 内核实现中,当 TCP 数据段发送后,在一定时间内没有收到接收方的确认应答(ACK),就会触发重传机制,内核会维护一个统计变量来记录 TCP 重传段的数量。
- 当
node_exporter运行时,它会定期读取/proc/net/snmp文件,解析其中的 TCP 相关统计数据,提取出TCPRetransSegs的值,并将其作为node_netstat_Tcp_RetransSegs指标暴露出来,供 Prometheus 采集。
-
指标意义
node_netstat_Tcp_RetransSegs用于衡量 TCP 数据传输时因各种原因(如网络丢包、延迟、接收方缓冲区满等)导致的重传次数。该指标可以反映出网络连接的稳定性和可靠性,重传次数过多可能意味着网络存在较大的丢包或延迟问题。
-
相关命令示例
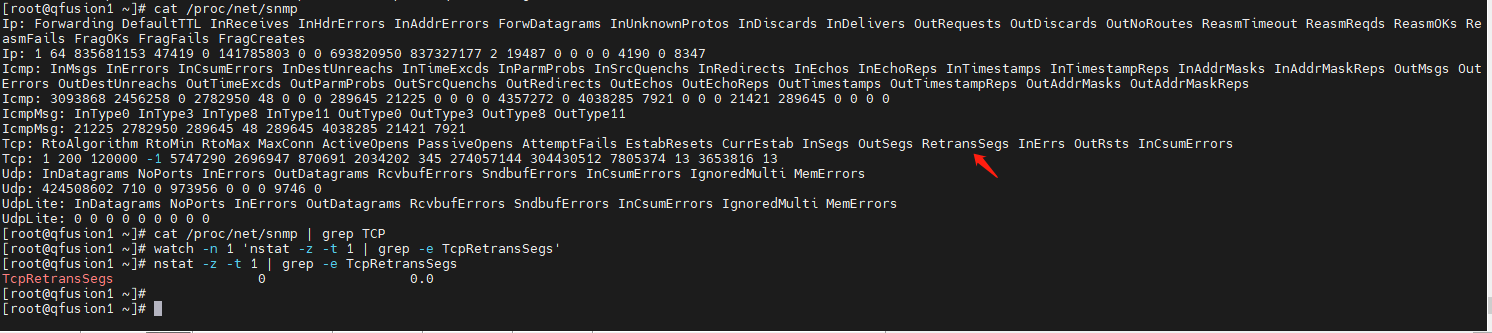
- 可以使用以下命令查看系统中每秒 TCP 重传报文数量:
该命令利用watch -n 1 'nstat -z -t 1 | grep -e TcpRetransSegs'nstat工具来获取 TCP 重传段数的统计数据,并通过watch命令每秒更新一次显示,方便观察 TCP 重传情况。
- 可以使用以下命令查看系统中每秒 TCP 重传报文数量:
-
默认未采集原因
node_netstat_Tcp_RetransSegs指标在node_exporter的默认配置中未启用,这是因为node_exporter的网络统计采集器(netstat collector)默认只采集了一些常见的网络指标,未涵盖所有可能的网络统计项。
-
启用方法
- 如果需要
node_netstat_Tcp_RetransSegs指标,可以通过修改node_exporter的配置来启用。具体方法是设置--collector.netstat.fields参数,指定要采集的网络统计字段。例如,可以使用以下命令启动node_exporter:
该命令通过指定正则表达式来匹配和采集一系列的 TCP、UDP 和 ICMP 等网络协议的统计信息,其中包括node_exporter --collector.netstat --collector.netstat.fields='^(. |_InErrors|_InErrs|Ip_Forwarding|Ip(6|Ext)(InOctets|OutOctets)|Icmp6?(InMsgs|OutMsgs)|TcpExt(Listen._|Syncookies.\*|TCPSynRetrans|TCPTimeouts|TCPOFOQueue)|Tcp_(ActiveOpens|InSegs|OutSegs|OutRsts|PassiveOpens|RetransSegs|CurrEstab)|Udp6?_(InDatagrams|OutDatagrams|NoPorts|RcvbufErrors|SndbufErrors))$'TCPRetransSegs指标。
- 如果需要
-
其他数据来源
- 除了
/proc/net/snmp文件,还可以通过执行netstat -s命令来查看 TCP 重传段数等网络统计信息,但该命令输出的内容较为冗杂,不如直接读取/proc/net/snmp文件或使用nstat工具来获取特定指标数据方便。
- 除了

















 4443
4443


 到【灌水乐园】发言
到【灌水乐园】发言








