







 本文介绍字符串逆序变换、删除最少出现字符及统计单词频率等算法实现,并通过C++示例代码展示了如何使用二叉树数组表示法完成先序遍历。
本文介绍字符串逆序变换、删除最少出现字符及统计单词频率等算法实现,并通过C++示例代码展示了如何使用二叉树数组表示法完成先序遍历。

第一题相对简单,就是把一个字符串逆序变换,再由原字符串返回,也就是在原字符串存储空间存储逆序变换后的字符串。
第二题是删除掉一个字符串中出现次数最少的字符,若出现次数同样少,则都删除,并返回删除后的子字符串,保持在原字符串中的位置不变。这道题和下面的第三道题类似,都是统计字符串中子串的个数,或出现的频率,并定位它们在原字符串中的位置。这道题原题要求只要考虑纯小写字母的情况,即原字符串完全由小写字母组成,没有大写字母,没有空格等其他标点符号了。第三道题更加复杂一些,要求考虑到大小写,空格,逗号,句号等字符。
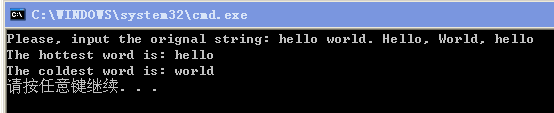
第三题,找出一个字符串中出现频率最高和最低的单词或字符,若出现频率同样,则输出第一个出现的单词或字符。原字符串有大小写单词,但要求程序忽略大小写区别。单词或字符间分割符有空格,逗号,句号。找出出现频率最高和最低的单词或字符后输出,输出的单词仅为小写。函数原型已经给定:void GetFilteredString(const string & orig, string & hotword, stirng & cold); 例如,输入为:"hello world. Hello, World. Hello. ",则输出为: "The hottest word is : hello The coldest word is: world"
下面是我写的C++程序:
#include<iostream>
#include<map>
#include<string>
#include<sstream>
using namespace std;
void GetFilteredString(const string&, string&, string&);
int main()
{
cout << "Please, input the orignal string: ";
string str;
getline(cin, str);
string hotword;
string coldword;
GetFilteredString(str, hotword, coldword);
cout << "The hottest word is: " << hotword << endl;
cout << "The coldest word is: " << coldword << endl;
return 0;
}
string uppertolower(const string &orig)
{
string newstr(orig);
for ( string::iterator it = newstr.begin(); it != newstr.end(); ++it) {
if ( (*it >= 65) && (*it <= 90) )
//newstr.push_back(*it + 32);
*it += 32;
else if ( (*it == ',') || (*it == '.') )
//newstr.push_back(' ');
*it = ' ';
/*else
newstr.push_back(*it);*/
}
return newstr;
}
void GetFilteredString(const string &orig, string &hot, string &cold)
{
string newstr = uppertolower(orig);
istringstream ss(newstr);
map<string, int> wordCount;
string word;
while(ss >> word)
++wordCount[word];
int max = 0, min = 256;
//map<string,int>::iterator hotptr, coldptr;
for (map<string,int>::iterator it = wordCount.begin(); it != wordCount.end(); ++it) {
if ( it -> second < min ) {
min = it -> second;
//coldptr = it;
}
if ( it -> second > max ) {
max = it -> second;
//hotptr = it;
}
}
istringstream tmp(newstr);
while(tmp >> word)
if ( wordCount[word] == min ) {
cold = word;
break;
}
istringstream tmp2(newstr);
while (tmp2 >> word)
if ( wordCount[word] == max) {
hot = word;
break;
}
}
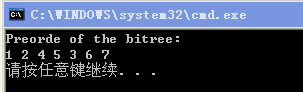
附加题是用一个整数数组构成一个二叉树,搜索整颗树以先序遍历输出节点。这道题考试当时没看题目,看了同学手抄版,就一个大概意思。要是用数组存储二叉树,而不是链表。那么先序遍历就要考虑一个根节点的孩子节点的位置。节点i的左右孩子节点的位置应该是2i和2i+1。然后编写一个先序遍历的函数,接受代表二叉树的整数数组,输出先序遍历结果。
下面是我写的程序:
#include<iostream>
using namespace std;
void preorde(int bitree[], int root)
{
if ( bitree[root -1] != 0) {
cout << bitree[root - 1] << " ";
int lchild = 2 * root;
int rchild = 2* root + 1;
preorde(bitree, lchild); // 递归调用
preorde(bitree, rchild);
}
}
int main()
{
const int maxTreeSize = 16;
int biTree[maxTreeSize]={1,2,3,4,5,6,7}; // 从左至右,从上之下依次存储每个节点值,若没有该节点,就用0代替。
//int biTree[maxTreeSize]={1,0,2,0,0,0,3};
cout << "Preorde of the bitree: " << endl;
int root = 1;
preorde(biTree, root);
cout << endl;
return 0;
}
第二题是删除掉一个字符串中出现次数最少的字符,若出现次数同样少,则都删除,并返回删除后的子字符串,保持在原字符串中的位置不变。这道题和下面的第三道题类似,都是统计字符串中子串的个数,或出现的频率,并定位它们在原字符串中的位置。这道题原题要求只要考虑纯小写字母的情况,即原字符串完全由小写字母组成,没有大写字母,没有空格等其他标点符号了。第三道题更加复杂一些,要求考虑到大小写,空格,逗号,句号等字符。
第三题,找出一个字符串中出现频率最高和最低的单词或字符,若出现频率同样,则输出第一个出现的单词或字符。原字符串有大小写单词,但要求程序忽略大小写区别。单词或字符间分割符有空格,逗号,句号。找出出现频率最高和最低的单词或字符后输出,输出的单词仅为小写。函数原型已经给定:void GetFilteredString(const string & orig, string & hotword, stirng & cold); 例如,输入为:"hello world. Hello, World. Hello. ",则输出为: "The hottest word is : hello The coldest word is: world"
下面是我写的C++程序:
#include<iostream>
#include<map>
#include<string>
#include<sstream>
using namespace std;
void GetFilteredString(const string&, string&, string&);
int main()
{
cout << "Please, input the orignal string: ";
string str;
getline(cin, str);
string hotword;
string coldword;
GetFilteredString(str, hotword, coldword);
cout << "The hottest word is: " << hotword << endl;
cout << "The coldest word is: " << coldword << endl;
return 0;
}
string uppertolower(const string &orig)
{
string newstr(orig);
for ( string::iterator it = newstr.begin(); it != newstr.end(); ++it) {
if ( (*it >= 65) && (*it <= 90) )
//newstr.push_back(*it + 32);
*it += 32;
else if ( (*it == ',') || (*it == '.') )
//newstr.push_back(' ');
*it = ' ';
/*else
newstr.push_back(*it);*/
}
return newstr;
}
void GetFilteredString(const string &orig, string &hot, string &cold)
{
string newstr = uppertolower(orig);
istringstream ss(newstr);
map<string, int> wordCount;
string word;
while(ss >> word)
++wordCount[word];
int max = 0, min = 256;
//map<string,int>::iterator hotptr, coldptr;
for (map<string,int>::iterator it = wordCount.begin(); it != wordCount.end(); ++it) {
if ( it -> second < min ) {
min = it -> second;
//coldptr = it;
}
if ( it -> second > max ) {
max = it -> second;
//hotptr = it;
}
}
istringstream tmp(newstr);
while(tmp >> word)
if ( wordCount[word] == min ) {
cold = word;
break;
}
istringstream tmp2(newstr);
while (tmp2 >> word)
if ( wordCount[word] == max) {
hot = word;
break;
}
}
附加题是用一个整数数组构成一个二叉树,搜索整颗树以先序遍历输出节点。这道题考试当时没看题目,看了同学手抄版,就一个大概意思。要是用数组存储二叉树,而不是链表。那么先序遍历就要考虑一个根节点的孩子节点的位置。节点i的左右孩子节点的位置应该是2i和2i+1。然后编写一个先序遍历的函数,接受代表二叉树的整数数组,输出先序遍历结果。
下面是我写的程序:
#include<iostream>
using namespace std;
void preorde(int bitree[], int root)
{
if ( bitree[root -1] != 0) {
cout << bitree[root - 1] << " ";
int lchild = 2 * root;
int rchild = 2* root + 1;
preorde(bitree, lchild); // 递归调用
preorde(bitree, rchild);
}
}
int main()
{
const int maxTreeSize = 16;
int biTree[maxTreeSize]={1,2,3,4,5,6,7}; // 从左至右,从上之下依次存储每个节点值,若没有该节点,就用0代替。
//int biTree[maxTreeSize]={1,0,2,0,0,0,3};
cout << "Preorde of the bitree: " << endl;
int root = 1;
preorde(biTree, root);
cout << endl;
return 0;
}

















 6436
6436

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









