






梯度下降的重要作用
在机器学习、深度学习中,为了求得最小的损失值与最优化参数,常通过迭代使用梯度下降来逐步逼近最小损失函数、最优模型参数。
什么是梯度下降
梯度下降法经典图示如下:
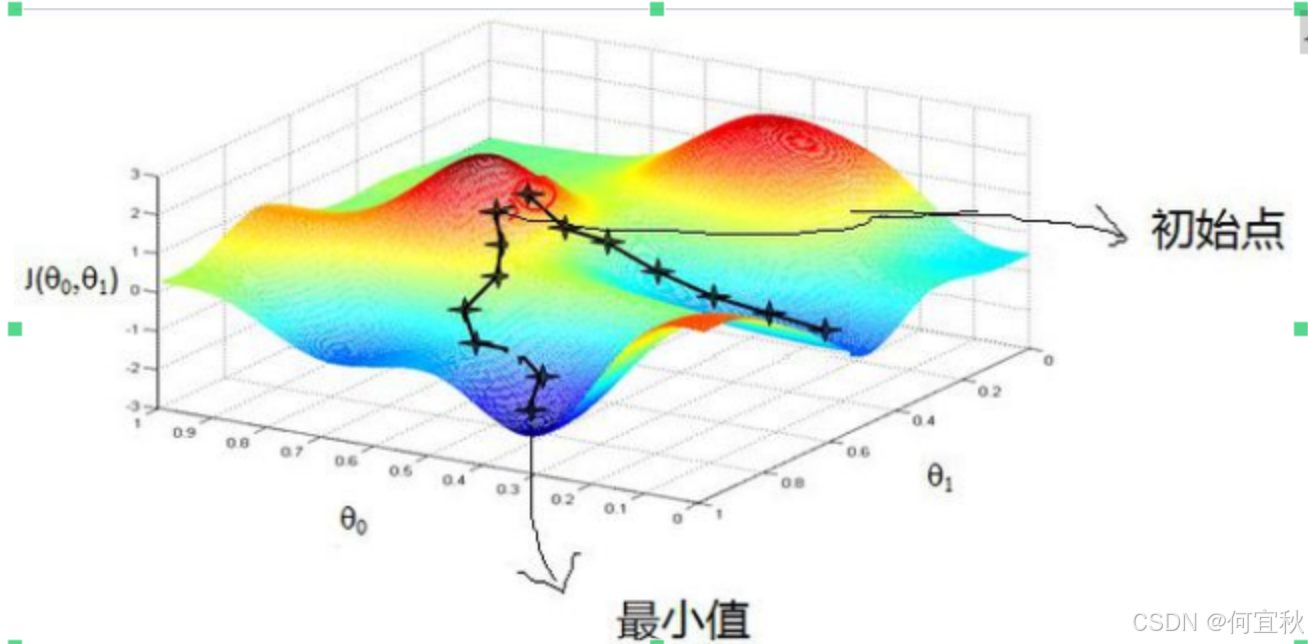
如我们在一座山的顶部,需要下山,但不熟悉下山的路,在下山过程中,每走到一个位置,都会求解当前位置的梯度,沿着梯度的负方向,也就是当前最陡峭的位置向下走一步,然后继续求解当前位置的梯度,向这一步所在的位置最陡峭最容易下山的方向走一步。不断循环求梯度,就这样一步步走下去,一直走到我们觉得已经到了山脚。当然这样走下去,有可能我们不能走到山脚,而是到了某个局部的山势低处。
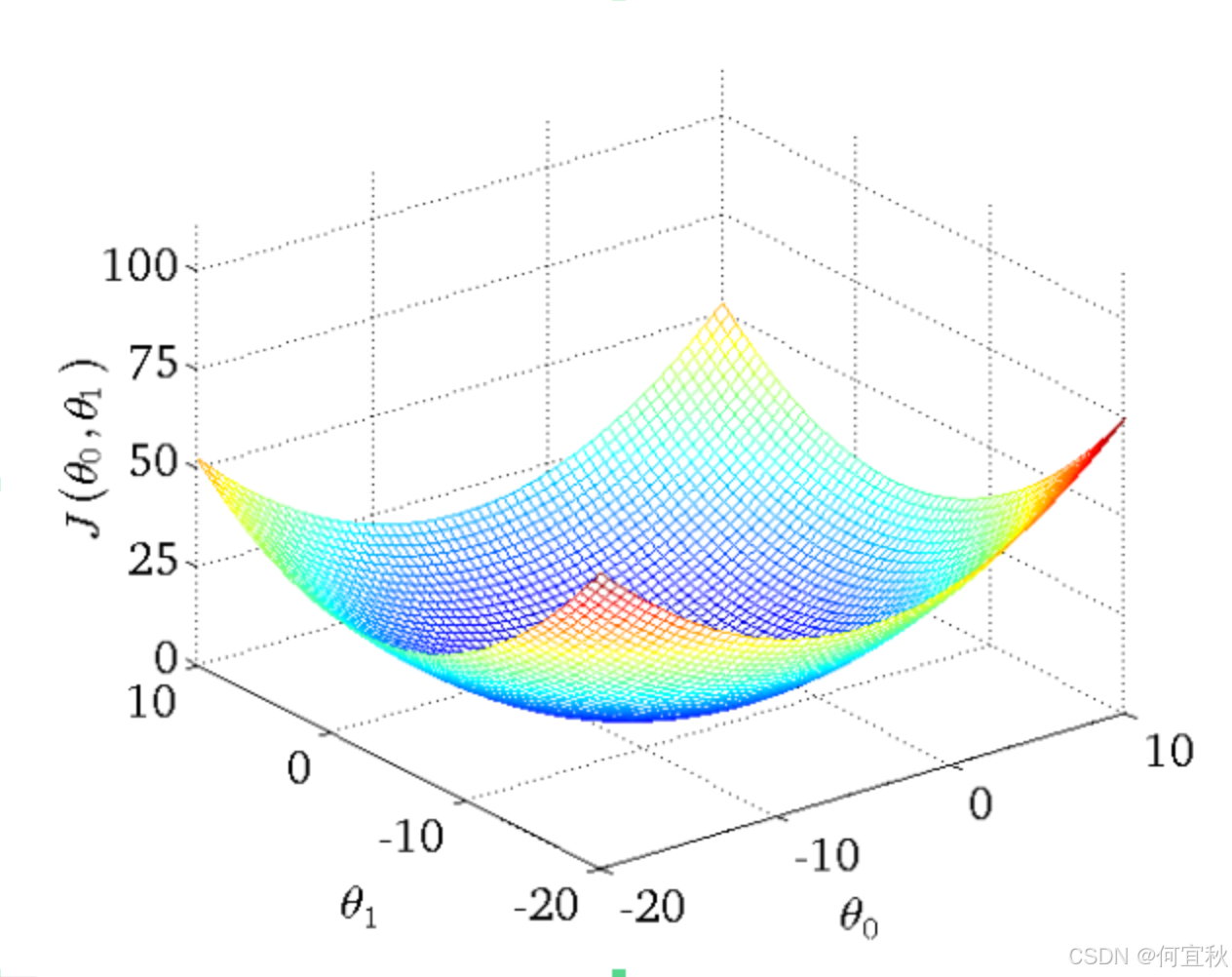
梯度下降不一定能够找到全局最优解,有可能是一个局部最优解,当然,如果损失函数是凸函数,梯度下降法得到的解就一定是全局最优解。如上图所示。
要进行梯度下降计算,先要获得一个损失函数,如果已有模型,还要初始化预训练模型参数,然后在这个基础上进行梯度下降计算。
梯度下降的数学原理
梯度下降的算法步骤如下:
1 确定优化模型的假设函数及损失函数
对于线性回归,假设函数为:
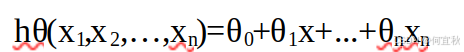
其中,θi,xi(i=0,1,2,…,n)分别为模型参数、每个样本的特征值
对于假设函数,损失函数为:
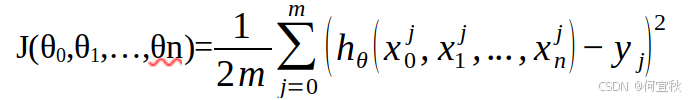
2 相关参数初始化
主要初始化θi、算法迭代步长a、终止距离ζ。初始化时可以根据经验,将θ初始化为0,步长a初始化为1。当前步长为φi。当然也可随机初始化。
3 迭代计算
计算当前位置损失函数的梯度,对于θi,其梯度表示为:
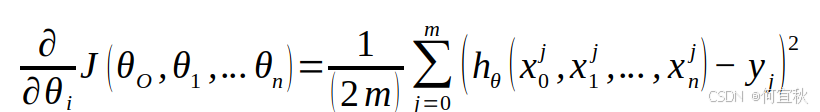
计算当前位置下降的距离:
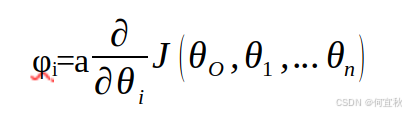
判断是否终止。
确定是否所有θi的梯度下降距离φi都小于终止距离ζ,如果都小于ζ,则算法终止,此时θi的值为最终的结果,否则进入下一步。
更新所有θi,更新后的表达式为:
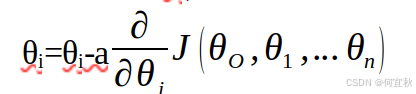
更新完毕后转入步骤1
实际使用梯度下降法时,各项参数指标不能一步就达到理想状态,对梯度下降的调优主要体现在以下几个方面。
1算法迭代步长a的选择:如果取值无效,说明要增大步长,但步长太大,有时会导致迭代速度过快,错过最优解,步长太小,迭代速度慢,算法运行时间长。
2 参数的初始值选择
3 标准化处理
梯度下降类型
随机梯度下降(Stochastic GD, SGD)求解思路
随机梯度下降法中损失函数对应的是训练集中每个样本的粒度。
损失函数可以写成如下形式:
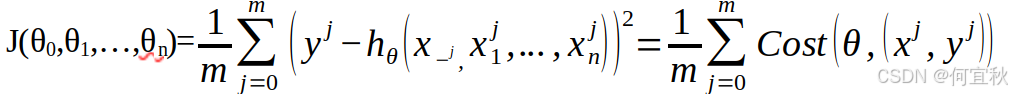
对每个参数θ按梯度方向更新θj:
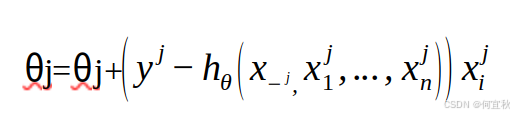
随机梯度下降法通过每个样本来迭代更新一次。
随机梯度下降法伴随的一个问题是噪声较批量梯度下降法要多,使得随机梯度下降法并不是每次迭代都向着整体最优化方向。
批量梯度下降法(Batch GD , BGD))的求解思路
首先得到每个对应的梯度:
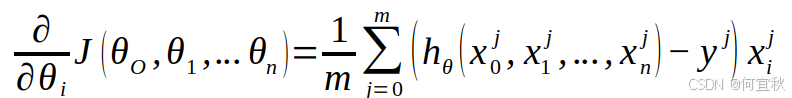
由于是求最小化风险函数,所以接下来按每个参数θ的梯度负方向更新θi:
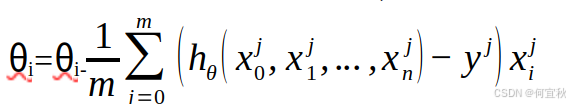
从上式可以看到,它得到的虽然是一个最优解,但每迭代一步,都要用到训练集所有的数据,如果样本数据很大,这种方法迭代速度就很慢。
相比而言,随机梯度下降法可避免这种问题。
小批量(Mini-Batch)梯度下降法的求解思路
对于总数为m的样本数据,选取其中的n(1<n<m)个子样本来迭代。其参数θ按梯度方向更新θi:
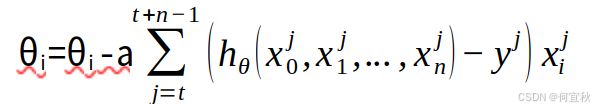


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









